eBay has been exploring the potential benefits of incorporating peer-to-peer transport technologies into our network topology. We’ve begun to use BitTorrent for index distribution, and we’ll soon use it for build distribution as well. In this post, we discuss our experience with BitTorrent and the problem of package distribution within the enterprise environment. Typical enterprise requirements are for replicating packages of medium to large size (a few megabtyes to several gigabytes) across a large number of target nodes, with high transfer reliability and often within stringent time lines. Use cases having such requirements include the following:
- Rollout of versioned software packages
- Fan-out of data packages across distributed grids for downstream processing
About BitTorrent
BitTorrent (BT) is a popular peer-to-peer (P2P) transport protocol that is commonly used across the Internet to transfer packages such as audio, video files, and data sets. According to a comprehensive 2008-2009 study of Internet traffic in eight regions of the world, BitTorrent traffic represents not only a lion’s share of all P2P traffic, but also a significant portion (20-30% or more) of all Internet traffic. BT works well due to the distributed nature of the transfers among the nodes; since a single server, or a few servers, do not need to transfer to all nodes across the grid, BT is efficient for distributing large packages to a large number of nodes.
BT splits the packages into pieces that are shared between the peers. A tracker maintains and provides a list of peers that are interested in a particular package. A peer first acts as a client. Once it receives a full piece, it acts as a server for that piece. The peer discovers other peers via one or more trackers. Information about trackers, pieces, and their checksums is stored within a “.torrent” file, which is typically a fraction of the overall file size. Before BT transfers can be initiated, the “.torrent” file is distributed to the peers using HTTP, SCP, or other client/server means. The BT specification and protocol details are described at theory.org.
The P2P technique, particularly the BitTorrent protocol, is well studied. Two key strategies for efficient BT content replication have been found to be piece selection and peer selection (see the 2006 paper, Rarest First and Choke Algorithms Are Enough). BT uses rarest first as the piece selection strategy, and the choke algorithm as the peer selection strategy. The rarest first strategy, as the name suggests, involves peers targeting the rarest piece for transfer. The choke strategy is based on fairness, speed, and reciprocation of uploads.
The content distribution problem has also been studied from a theoretical perspective (see Optimal Scheduling of Peer-to-Peer File Dissemination). Optimal distribution choices, comparing performance using a client/server mechanism versus P2P transfers, are described below.
| Protocol | Transfer time |
| Client/server | t * N |
| P2P with a single piece | t + t * log2(N) |
| P2P with multiple pieces | t + t * log2(N) / R |
where:
N = Number of nodes
R = Number of pieces that the package is split into
t = Time to transfer a complete package from one node to another
BitTorrent within the enterprise environment
BitTorrent has been used to a limited extent in large-scale web services to distribute files. Facebook uses it for file sharing, and Twitter for code deployments.
The BitTorrent protocol is designed for Internet scale with slow, unreliable, far-away and greedy clients in the presence of ISP throttling. BT-style distributions are desirable in enterprise environments, where large data sets of increasing size need to be transferred to a large set of nodes. In some ways, the problem of data transfers (fan-out) within a data center is simpler with reliable, managed, fast, and low-latency nodes. However, the demands of predictability, scalability, manageability, and efficiency are higher in such environments.
We now turn to optimization options, on top of regular BT transfers, for improving efficiency and predictability
Configuration
The general BitTorrent configuration is designed for Internet scale with slow and unreliable clients. This configuration can be adapted to work better in the enterprise environment with homogenous clients. The upload and download parameters and piece sizes can be adapted to improve transfer rates and reliability in an enterprise environment. The tit-for-tat strategy as a part of the choke algorithm, throttling, and encryption of payload may not be needed in enterprise environments.
Peer selection
When distributing pieces between peers, it is efficient to pick peer nodes the closest to each other. In enterprise environments, the server topology may be available beforehand and easily leveraged in the algorithm to pick nearer neighbors. We find that closeness of IP address can often be used as a reasonable approximation.
Cross-data-center transfers
When distribution topology extends across multiple data centers, it is useful to limit cross-data-center transfers due to bandwidth constraints–limited and/or expensive bandwidth.
A naïve approach to reducing cross-data-center transfers is to perform them in two steps. The first step is to transfer a package to one or a few nodes in each data center. The second step is to initiate BT transfers within each data center such that package transfer takes place between the initial nodes and the rest of the nodes in that data center—in effect, one BT transfer session per data center. This two-step scheme increases the overall transfer time. Peer selection based on closeness of IP address can be an effective way of conducting transfers in a single step, with all nodes participating in the torrent session.
Package transfer steps
When the source package is in HTTP, HDFS, or custom storage, BT distribution requires sequential execution of steps as follows:

Before initiating the BT session to download a package, the additional steps that need to be executed are downloading from the package store, generating the “.torrent” file (assuming it was not previously generated), and seeding the package. Each step requires the sequential reading or writing of the data. It is common to find that the time taken by these steps is comparable to actual download time.
As multiples of these steps need to be performed in sequence, the best way to simplify the distribution is to avoid some of the steps altogether.
Web seeding
HTTP-based web servers are popularly used to host packages. Clients connect to one or a handful of these servers to download a package. Even when using BT, it is common for the initial “.torrent” file to be downloaded from an HTTP server. The “.torrent” file contains package meta-information, including the location of trackers and piece-by-piece checksums.
Web seeding is an attempt to host packages on web servers so that they can be used for seeding. This technique avoids the need for a separate BT seeding process, as web servers can double up as seeders for hosted content.
BitTorrent web seeding has two distinct and incompatible specifications. The BitTornado specification is based on a custom URL scheme to download specific pieces. The GetRight specification relies on the basic HTTP 1.1 download mechanism using byte serving (byte range queries).
We find that the HTTP byte-serving method is more convenient, as it simply requires hosting packages behind an HTTP 1.1-compatible server. We recommend hosting both the “.torrent” file and packages on the same server. The “.torrent” file can be created at the same time that the source package is generated, thereby avoiding the need for a separate step to create it later during BT transfer. In this scheme, BT seeders are not used; instead, BT clients use HTTP range queries to download pieces from a web server. Once one or a few peers have a piece, the distribution of that piece takes place between peers without a request to the HTTP server. Note that this scheme requires BT clients to support both the BT and HTTP protocols.
Here is a summary of the benefits of using web seeding:
- HTTP server-hosted packages can be used for both HTTP and BT transport. Web seeding allows the HTTP packages to be transferred using the BT protocol; when distributing to a few nodes, HTTP transport works well.
- BT seeding requires the additional step(s) of downloading the package (if the seeder is different from the HTTP package store), and then seeding it before the BT transfer can be initiated. As explained above, web seeding avoids these steps and saves time.
- When we have a large number of packages, any of which can be downloaded using BT, serving via BT seeding requires an always-on seeder—which means having a separate seeding process (a process or thread per package). Even when transfers are inactive, these processes or threads need to be running. By contrast, HTTP transport does not require any activity when package download is not occurring.
- With traditional BT seeding, the seeder periodically communicates with the tracker on its status and progress, so that tracker logs can be mined for network utilization, the time taken by nodes, and other package transfer details. If the BT seeding session is left active to support any future BT downloads, it continues communicating with the tracker whether or not there is any download activity. The result is communication overhead and cluttered logs. Web seeding avoids these disadvantages because it does not involve communicating with the tracker.
HDFS-based seeding
Hadoop and HDFS are becoming increasingly popular in enterprise environments to store large data files. In HDFS, large data files are split into several blocks, copies of which are stored on multiple nodes to provide reliability and fail-over capability (default block size is 64 MB).
Distribution for HDFS-hosted packages can borrow ideas from the web-seeding approach, as HDFS supports retrieval of arbitrary portions of packages. The “.torrent” file can be generated in a parallel manner, with piece checksums being computed as a map/reduce task. In order for the map/reduce task to work efficiently, the BT piece size can be chosen such that one or multiple BT pieces equate to a single HDFS block. This strategy helps with torrent generation and BT distribution, as BT pieces wouldn’t spawn across HDFS blocks.
The use of HDFS-based seeding has the following advantages (some of which are similar to those of web seeding):
- The source package may be stored across HDFS nodes. Downloading it on a single seeder node requires download and aggregation of HDFS blocks before BT seeding. This step can be avoided with HDFS-based seeding.
- BT seeding traverses through the entire package, validating checksums, before seeding. The HDFS-based seeding approach both avoids a sequential read of a large package and provides an always-on seeder.
- Using traditional BT seeding with large HDFS packages requires keeping multiple versions of the packages on seeder nodes—and consequently extra bookkeeping, space management, and cleanup. HDFS seeding avoids this overhead.
Dealing with deltas
When clients have an earlier version of a package with some overlapping content, efficiency improvements can be achieved by downloading less of that package. The rsync algorithm is one of the commonly used techniques for dealing with package deltas. This algorithm uses a combination of strong and weak checksums to determine the deltas. A modified scheme, called zsync, is used for delta computation in a distributed manner. The zsync scheme works nicely with HTTP 1.1 and byte range queries. We suggest a combination of BitTorrent and zsync as a way to transfer packages with some overlapping content.
As clients may have different versions of a package, each client identifies and reuses common parts of the package by employing small “.zsync” files that contain weak and strong checksums. When using zsync in combination with the BitTorrent protocol, a client can download the modified portion from other peers if peers contain the piece. If other peers do not contain the piece, the client can default to web seeding and use HTTP 1.1 byte range to download that piece from source.
The amount of overlap between package versions would depend on the package format as well as the changes compared to the earlier version of the package. The package producers are likely to know whether such overlap is expected. The presence of a “.zsync” file can indicate whether a previous version of the package should be scanned to determine overlap. In the absence of a “.zsync” file, the BT client can fall back to the case where no common parts are shared with the previous version.
BitTorrent test results
To optimize transfer time, we ran a series of experiments using a small cluster of 16 nodes. The results discussed below are captured in a data center environment with fast connectivity (1 Gbps) between nodes with low latency (less than a few milliseconds). We used BitTornado for our experiments. The peer nodes are homogenous, running the same BT client version with identical configurations.
This first table shows the actual and theoretical times taken to transfer a 30 GB package as the number of nodes is varied:
| Number of nodes | Theoretical client server (minutes) | Theoretical P2P best (minutes) – B | Actual transfer time (minutes) – A | Ratio (B / A) |
| 1 | 4 | 4 | 11 | 0.36 |
| 2 | 8 | 4 | 12 | 0.33 |
| 3 | 12 | 4 | 13 | 0.31 |
| 4 | 16 | 4 | 13.5 | 0.30 |
| 6 | 24 | 4 | 16 | 0.25 |
| 8 | 32 | 4 | 16 | 0.25 |
| 16 | 64 | 4 | 17 | 0.24 |
The theoretical times are computed using the formulas described earlier with t = 4 minutes and R = 3840. The actual time taken is the time for all nodes to receive the full package.
The theoretical client/server time shows a linear increase as the number of nodes is increased. The theoretical P2P best time is constant at 4 minutes. The data shows that the actual transfer times are better than the theoretical client/server times when the number of nodes increases beyond 3-4. While the actual time taken increases as the number of nodes increases, the rate of growth decreases.
The ratio between theoretical best and actual times indicates the efficiency in transfer compared to the theoretical best. The ratio, and thus efficiency, decreases as the number of nodes increases—going from 36% to 24% as the number of nodes increases from 1 to 16. The low efficiency suggests potential improvements with an optimized BitTorrent implementation or use of other P2P schemes.
The following table shows the time taken by the different steps in downloading and transferring the 30 GB package to a 16-node cluster:
| Step # | Step | Time taken (minutes) |
| 1 | HDFS download | 6 |
| 2 | Torrent generation | 6 |
| 3 | Seeding | 6 |
| 4 | Package transfer | 17 |
The time for actual package transfer (step 4) is comparable to the combined time of the three prior steps. Web seeding or HDFS-based seeding would avoid steps 1 and 3. Step 2 can be performed during package creation or as a map/reduce task for HDFS packages. Because steps 1 through 3 are executed sequentially, HTTP- or HDFS-based seeding can achieve substantial gains for package transfer.
The following graph shows the amount of piece sharing that happens in the swarm of 16 nodes. The data depicted is captured from tracker logs at the end of a BT transfer.
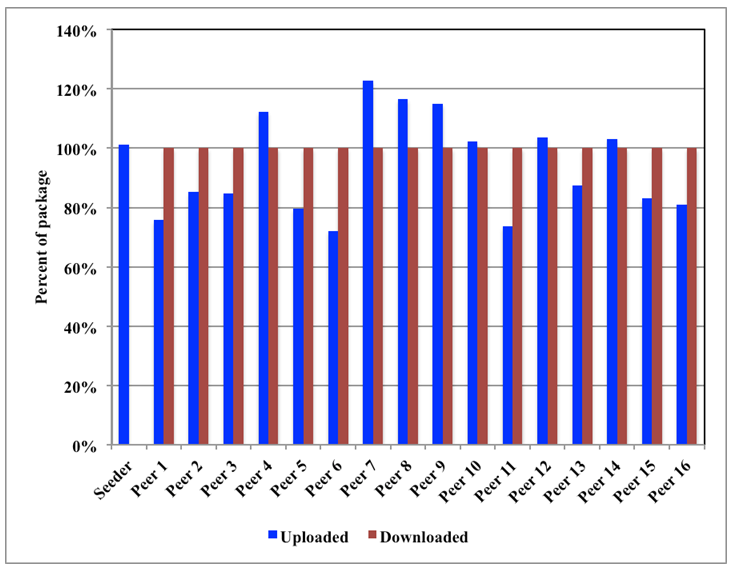
The download figures are not very interesting, as each peer needs the entire package. Thus, download is 100% for peers while 0% for the seeder.
The amount of upload varies between the seeder and the peers. The seeder needs to upload all pieces at least once, and thus its upload would be 100% or more. The results show seeder upload of slightly more than 100%, while peer upload ranged from 75% to 125%. Thus, all peers participated in uploads such that the original seeder did not upload a disproportionately high amount of the package bytes.
Summary
For the package fan-out problem in enterprise environments, BitTorrent-based distribution is a good solution. The problem of package transfers is simpler in enterprise environments, with their fast, reliable networks and homogenous clients. Web seeding and HDFS-based seeding can be used to avoid some of the steps and increase the speed of package transfers. Deltas across package versions can be dealt with effectively by using an approach that combines zsync and BitTorrent mechanisms.