Today’s successful organizations are data-driven. At eBay, we have thousands of engineers, analysts, and data scientists crunching petabytes of data every day to provide a seamless user experience. Through the use of data, we can execute at a massive scale and connect our millions of users to global ecommerce.
Apache Hadoop has been one of the most popular framework choices for Big Data analytics at eBay. We use Hadoop to generate value from data to improve search experience and identify and optimize relevant advertisements. This value also helps us enrich our product catalogs, and perform click stream analysis to understand how eBay customers leverage our marketplace. The Analytics Data Infrastructure (ADI) team at eBay is responsible for providing highly available and reliable Hadoop clusters for all customers. Currently, the team maintains 10+ Hadoop clusters ranging from hundreds to thousands of nodes. In this blog, we explore how we have enabled federation on one of our largest Hadoop clusters with 4,000+ nodes, 1B file system objects and 170PB of storage – all with the goal of improving our customer experience.
Problem Statement
One of our largest Hadoop clusters reached the magic number of 1B total file system objects. The NameNode process was running with 200GB of memory. Once file system objects count exceeds 950M, we began observing various scaling issues.
1) The NameNode process was running with almost 90 percent memory leading to frequent full GC. Given we were already running with 200GB memory, we had reached the physical memory limit of enterprise node with no further scope of increasing memory.
2) As shown below, we faced NameNode failover every other day due to high GC activities. We observed six failovers in seven days and the cluster was becoming unstable.

3) The overall RPC processing time by NameNode increased significantly and resulted in slowness for various SLA jobs.
4) We were running out of RPC threads on the NameNode which hindered our ability to add more data nodes to cluster.
Under these conditions, we were not able to provide a highly available and reliable cluster. This forced us to consider scaling out a solution for name service by enabling federation for our cluster. Below, we discuss View FileSystem, namespace selection (the most important design decision), and basic ideas and outcome of the NameNode federation. We then conclude with some of our learnings and future plans.
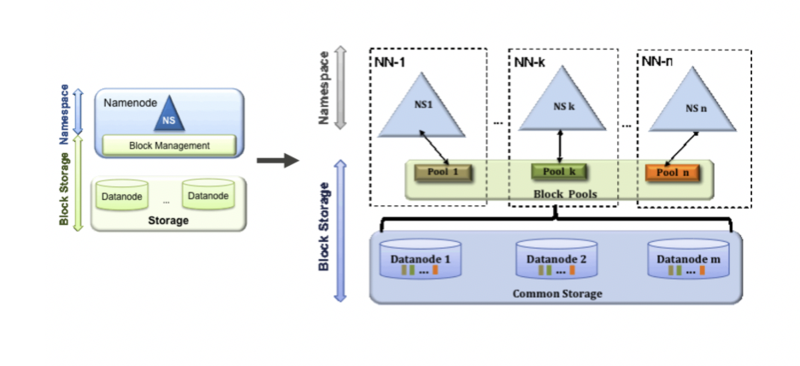
NameNode Federation
Hadoop NameNode federation allows horizontal scaling of the name service. It contains several NameNodes or namespaces, each of which act independent of each other. These independent NameNodes are federated, which means that they don’t require inter-coordination. DataNodes are used as common storage by all the NameNodes, while each DataNode is registered with all the NameNodes in the cluster. For more information about NameNode federation design, please click here.


View FileSystem
The View File System (ViewFs) provides a way to manage multiple Hadoop file system namespaces (or namespace volumes). It is particularly useful for clusters that have multiple NameNodes and hence multiple namespaces in HDFS Federation. ViewFs is analogous to client-side mount tables in some Unix/Linux systems. ViewFs can be used to create personalized namespace views and also per-cluster common views. The team was particularly interested in using viewFS as it enabled our customers to use their existing code on the federated cluster with only config changes. For more information about viewFS, please click here.


Selection of Namespace
One of the important decisions for enabling federation is selection of namespace. As shown in the table below, we had a couple of folders which were candidates for separate namespace. One of the obvious choices was “/PathA” folder having the highest storage utilization. However, NameNode performance (in terms of RPC processing time, GC activities, etc.) directly depends on the amount of file system objects it needs to store in memory and the amount of operations performed for those objects. As the below shows “/PathB” folder used only 13.6PB storage, but it had the highest number of file system objects and operations being performed. Therefore, we decided to create “/PathB” as separate namespace and placed all the other remaining folders under another single namespace.
 Federation Outcome
Federation Outcome
NameNode Heap Usage
The most important benefit of federation is that the overall metadata will be reduced for NameNodes in terms of memory usage. As shown in the graph below, memory usage of existing NN reduced from 146GB to 88-95GB after the federation rollout.

NameNode Metadata Size
As heap memory usage reduces, it’s able to store more metadata per NameNode process with less memory requirement. The table and graph below show that currently, the new federation cluster is holding almost the same or slightly more metadata information than the old cluster.


Though total file system objects for the new cluster is a little higher than the old cluster, overall heap usage is almost half. As shown in the below graph, heap usage for federated NameNodes is 85GB and 96GB.

For the old cluster, it was 182GB even after full GC.

Based on current metrics, we can easily double the number of file system objects for new clusters without impacting performance.
GC Time for Each Cycle
Amount of time spent for each GC also matters in measuring performance of application. As shown in the graph below, the GC time is around 100 ms for federated NameNodes.

For the old cluster, the time was around 200 ms.

Average Operation Time
There was direct impact on average operation time performed by NameNode. One of the most important and costly operations performed by Namenode is "GetBlocks". As shown in the graph below, this operation takes around 50ms to 125ms for federated NameNodes.

For similar operations in our older cluster, it took 300ms to 400ms.

FS Image Size
FS image contains all metadata information which is used in event of a NameNode restart. At the NameNode restart, the entire image gets loaded into memory and block reports are generated. NameNode stays in safe mode and no write operations are allowed during this time. This FS image size purely depends on metadata information. We now have almost half FS image size for federation NameNodes compared to the old cluster, which reduces NameNode startup time.
 Learning
Learning
While enabling federation of our cluster, we came across four main issues:
1) Default move operation is very strict in viewFs. By default, viewFs does not allow mv operations across mount points for the same namespace. This resulted in issues with Hive/Spark queries. The solution was to apply the HADOOP-14455 patch.
2) Spark/Hive job failure because of ORC write error on viewFs. This was resolved with patch HIVE-10790.
3) We observed higher iowait caused by “du” command as HDFS needs to scan two 256 * 256 blockpools resulting in higher system load.
All existing Hive/Spark tables locations had to be updated in Hive Metastore. We modified all locations from hdfs:// to viewfs:// during roll out. If you have a firewall in your system, then make sure to have all connectivity issues resolved for newly added federated NameNodes.
After enabling the NameNode federation, we were able to provide a more reliable and performant cluster for our customers. Our selection for namespace was near-perfect as we were able to reduce heap usage, RPC processing time, and GC time by half for both NameNodes. We are now confident to add additional federated NameNodes in the future to increase our cluster capacity beyond 5,000 nodes.
Appendix
At eBay, we run our Hadoop 2.7.3 custom build on about 5,000+ nodes on our custom designed hardware (ODM) using Kubernetes in assimilation mode.