In a previous post, Junling discussed data mining and our need to process petabytes of data to gain insights from information. We use several tools and systems to help us with this task; the one I’ll discuss here is Apache Hadoop.
Created by Doug Cutting in 2006 who named it after his son’s stuffed yellow elephant, and based on Google’s MapReduce paper in 2004, Hadoop is an open source framework for fault tolerant, scalable, distributed computing on commodity hardware.
MapReduce is a flexible programming model for processing large data sets:
Map takes key/value pairs as input and generates an intermediate output of another type of key/value pairs, while Reduce takes the keys produced in the Map step along with a list of values associated with the same key to produce the final output of key/value pairs.
Map (key1, value1) -> list (key2, value2)Reduce (key2, list (value2)) -> list (key3, value3)
Ecosystem

Athena, our first large cluster was put in use earlier this year.
Let’s look at the stack from bottom to top:
- Core – The Hadoop runtime, some common utilities, and the Hadoop Distributed File System (HDFS). The File System is optimized for reading and writing big blocks of data (128 MB to 256 MB).
- MapReduce – provides the APIs and components to develop and execute jobs.
-
Data Access – the most prominent data access frameworks today are HBase, Pig and Hive.
- HBase – Column oriented multidimensional spatial database inspired by Google’s BigTable. HBase provides sorted data access by maintaining partitions or regions of data. The underlying storage is HDFS.
- Pig (Latin) – A procedural language which provides capabilities to load, filter, transform, extract, aggregate, join and group data. Developers use Pig for building data pipelines and factories.
- Hive – A declarative language with SQL syntax used to build data warehouse. The SQL interface makes Hive an attractive choice for developers to quickly validate data, for product managers and for analysts.
-
Tools & Libraries – UC4 is an enterprise scheduler used by eBay to automate data loading from multiple sources.
Libraries: Statistical (R), machine learning (Mahout), and mathematical libraries (Hama), and eBay’s homegrown library for parsing web logs (Mobius). - Monitoring & Alerting – Ganglia is a distributed monitoring system for clusters. Nagios is used for alerting on key events like servers being unreachable or disks being full.
Infrastructure
Our enterprise servers run 64-bit RedHat Linux.
- NameNode is the master server responsible for managing the HDFS.
- JobTracker is responsible for coordination of the Jobs and Tasks associated to the Jobs.
- HBaseMaster stores the root storage for HBase and facilitates the coordination with blocks or regions of storage.
- Zookeeper is a distributed lock coordinator providing consistency for HBase.
The storage and compute nodes are 1U units running Cent OS with 2 quad core machines and storage space of 12 to 24TB. We pack our racks with 38 to 42 of these units to have a highly dense grid.
On the networking side, we use top of rack switches with a node bandwidth of 1Gbps. The rack switches uplink to the core switches with a line rate of 40Gpbs to support the high bandwidth necessary for data to be shuffled around.
Scheduling
Our cluster is used by many teams within eBay, for production as well as one-time jobs. We use Hadoop’s Fair Scheduler to manage allocations, define job pools for teams, assign weights, limit concurrent jobs per user and team, set preemption timeouts and delayed scheduling.
Data Sourcing
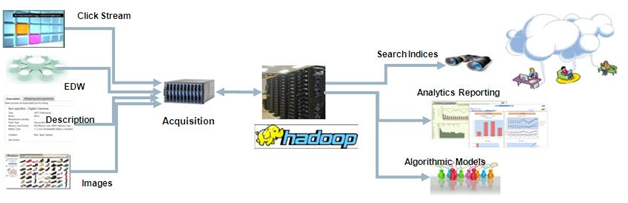
On a daily basis we ingest about 8 to 10 TB of new data.
Road Ahead
Here are some of the challenges we are working on as we build out our infrastructure:
-
Scalability
In its current incarnation, the master server NameNode has scalability issues. As the file system of the cluster grows, so does the memory footprint as it keeps the entire metadata in memory. For 1 PB of storage approximately 1 GB of memory is needed. Possible solutions are hierarchical namespace partitioning or leveraging Zookeeper in conjunction with HBase for metadata management. -
Availability
NameNode’s availability is critical for production workloads. The open source community is working on several cold, warm, and hot standby options like Checkpoint and Backup nodes; Avatar nodes switching avatar from the Secondary NameNode; journal metadata replication techniques. We are evaluating these to build our production clusters. -
Data Discovery
Support data stewardship, discovery, and schema management on top of a system which inherently does not support structure. A new project is proposing to combine Hive’s metadata store and Owl into a new system, called Howl. Our effort is to tie this into our analytics platform so that our users can easily discover data across the different data systems. -
Data Movement
We are working on publish/subscription data movement tools to support data copy and reconciliation across our different subsystems like the Data Warehouse and HDFS. -
Policies
Enable good Retention, Archival, and Backup policies with storage capacity management through quotas (the current Hadoop quotas need some work). We are working on defining these across our different clusters based on the workload and the characteristics of the clusters. -
Metrics, Metrics, Metrics
We are building robust tools which generate metrics for data sourcing, consumption, budgeting, and utilization. The existing metrics exposed by some of the Hadoop enterprise servers are either not enough, or transient which make patterns of cluster usage hard to see.
eBay is changing how it collects, transforms, and uses data to generate business intelligence. We’re hiring, and we’d love to have you come help.
Anil Madan
Director of Engineering, Analytics Platform Development