Experimentation
The Experimentation platform at eBay runs around 1500 experiments that are responsible for processing over hundreds of TBs of reporting data contained in millions of files using Hadoop infrastructure and consuming thousands of computing resources. The entire report generation process contains well over 200 metrics, and it enables millions of customers to experience small and large innovations that enable them to buy and sell products in various countries in diverse currencies and using diverse payment mechanisms in a better way everyday.
The Experimentation reporting platform at eBay is developed using Scala, Scoobi, Apache Hive, Teradata, MicroStrategy, InfluxDB, and Grafana.
Tracking
Our user-behavior tracking platform enables us to gain insights into how customers behave
and how products are used and unlock the information needed to build the right strategies for improving conversion, deepening engagement, and maximizing retention.
The eBay platform contains hundreds of applications that enable users to search for products, view specific product, and engage in commerce. These applications are running on numerous servers in data centers across the world, and they log details of every event that occurs between a user and eBay (in a specific application), such as activity (view product, perform search, add to cart, and ask questions, to name a few) and transaction (BID, BIN, and Buyer Offer, for example), including the list of experiments that a user is qualified for and has experienced during that event. Tracking data is moved from application servers to distributed systems like Hadoop and Teradata for post-processing, analytics, and archival.
Anomalies
Any experiment that runs on the Experimentation platform can experience anomalies that need to be identified, monitored, and rectified in order to achieve the goal of that experiment.
- Traffic corruption. An experiment is set up to ensure that it receives an approximately equal share of unique visitors, identified by GUID (global unique identifier) or UID (signed-in), throughout its life cycle. At times, this traffic share is significantly skewed between experiment (the new experience) and control (the default experience), potentially resulting in incorrect computation of bankable and non-bankable metrics. This is one of the critical anomalies and is carefully monitored.
- Tag corruption. The vast amounts of user activity collected by eBay application servers include information (tags) about the related list of experiments that a user is qualified for. Any kind of corruption or data loss can significantly hamper metrics computed for any experiment.
Here are some typical reasons for these anomalies:
- GUID reset: GUIDs are stored on browser cookies. Any kind of application error or mishandling of browser upgrades can cause GUID resets against either the experiment or the control, resulting in traffic corruption.
- Cache refresh: eBay application servers maintain caches of experiment configurations. A software or hardware glitch can cause the caches on these servers to go out of sync. This problem can lead to both traffic and tag corruption.
- Application anomalies: Web pages are served by application servers. These application servers invoke several experimentation services to determine the list of experiments that a user is qualified for, based on several factors. Application servers can incorrectly log this information, thereby corrupting essential tags because of incorrect encoding, truncation, and application errors. This problem results in both traffic and tag corruption.

Monitoring anomalies
Anomalies in experiments are detected daily and ingested into InfluxDB, an open-source time-series database, visualized with Grafana.
InfluxDB is an open-source database, specifically designed to handle time-series data with high availability and high performance requirements. InfluxDB installs in minutes without external dependencies, yet is flexible and scalable enough for complex deployments. InfluxDB offers these features, among many others.
- InfluxDB possesses on-the-fly computational capabilities that allow data to become available within milliseconds of its capture.
- InfluxDB can store billions of data points for historical analysis.
- InfluxDB aggregates and precomputes time-series data before it is written to disk.
Grafana provides a powerful and elegant way to create, explore, and share dashboards and data with your team. Grafana includes these features among many others:
- Fast and flexible client-side graphs with a multitude of options
- Drag-and-drop panels, where you can change row and panel widths easily
- Support for several back-end time series databases, like InfluxDB, Prometheus, Graphite, and Elastic Search, with the capability to plug in custom databases
- Shareable links to dashboards or full-screen panels
The Experimentation reporting platform leverages both InfluxDB and Grafana to monitor anomalies in experiments. It supports the following features.
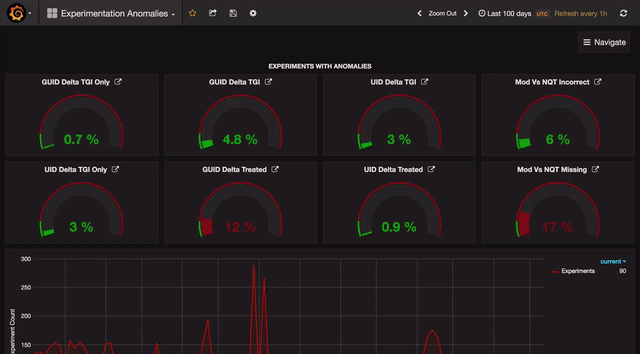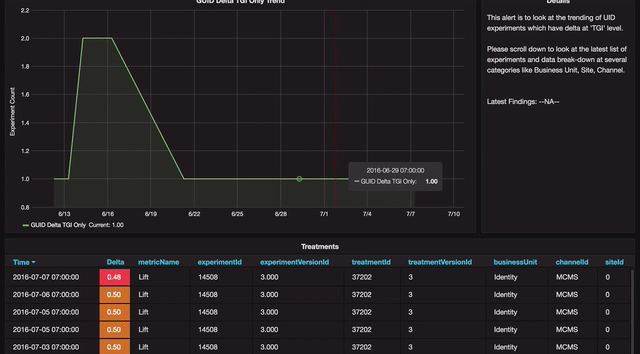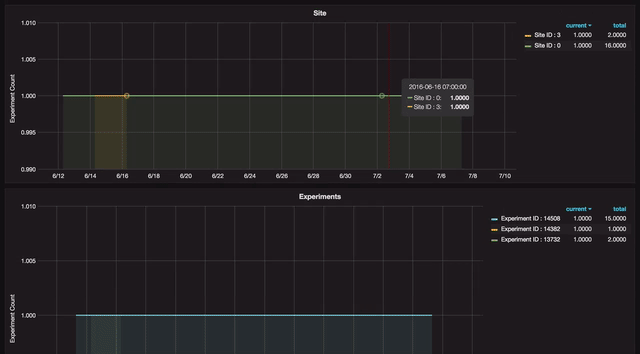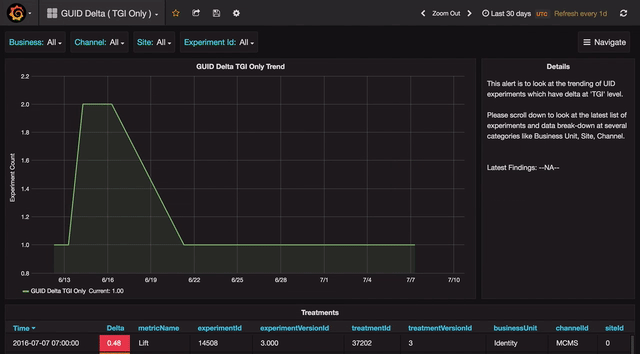
Home page
The home page consists of a bird’s-eye view of all anomalies, broken at various levels like channel, business (application), and country. Every anomaly has certain threshold beyond which it needs to be further analyzed. The Gauge panel in Grafana enables us to do just that.
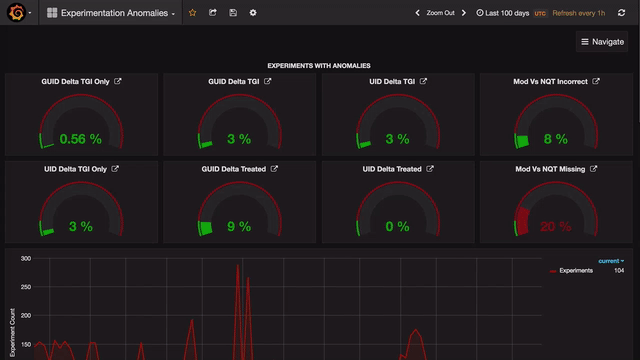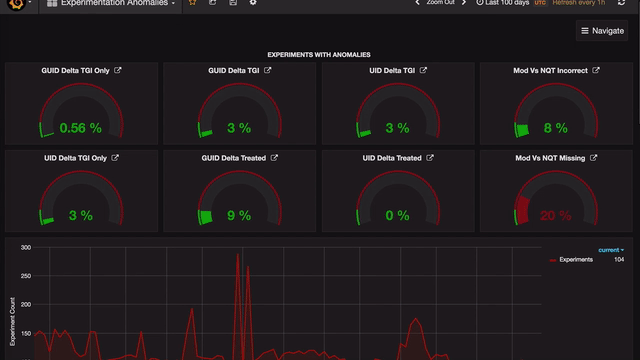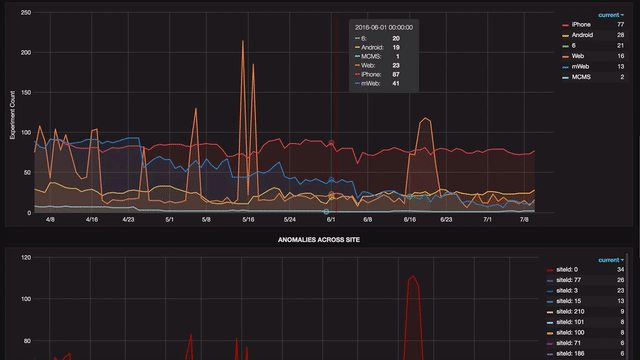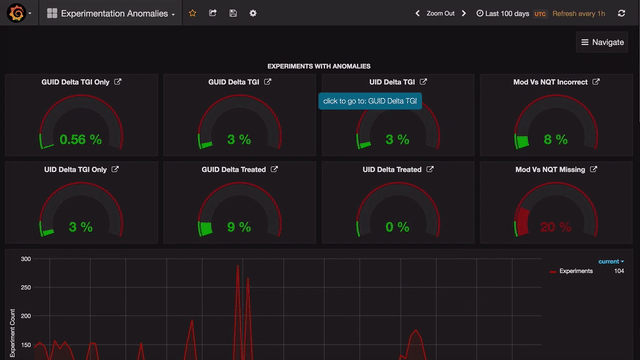
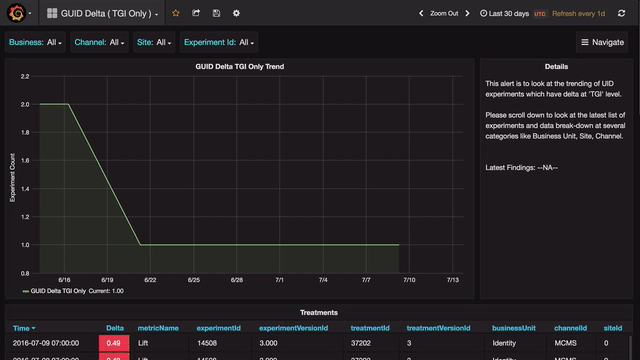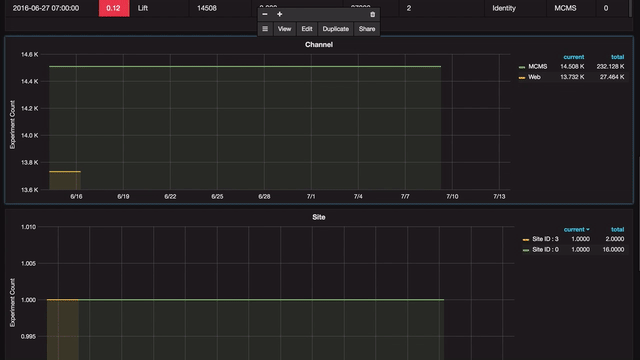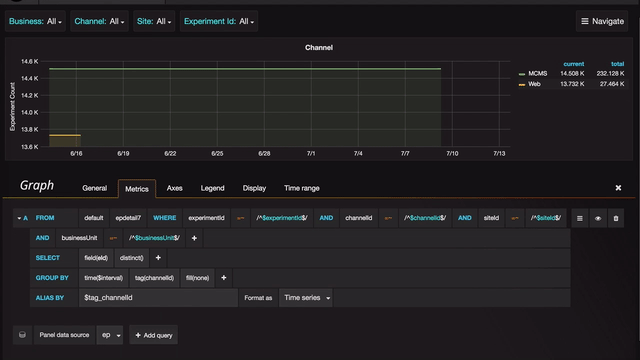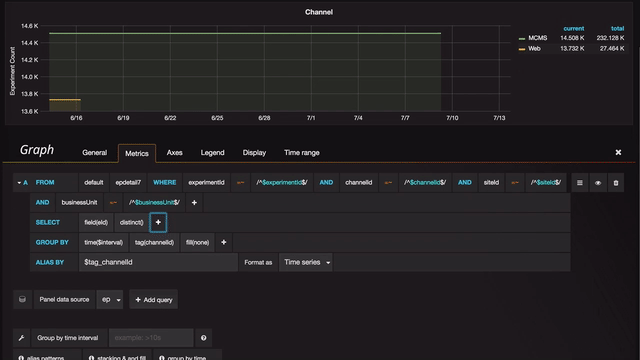
Drill-Down view
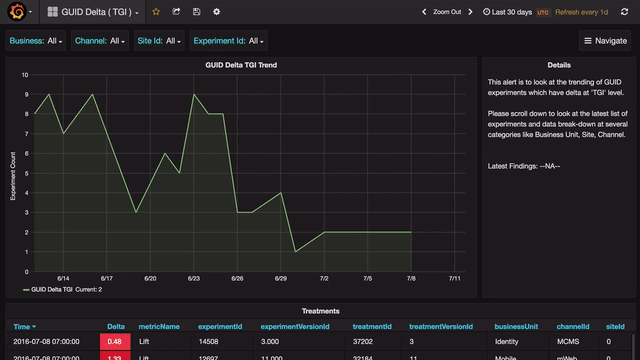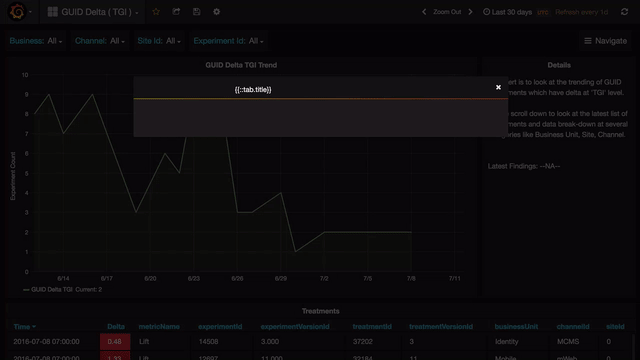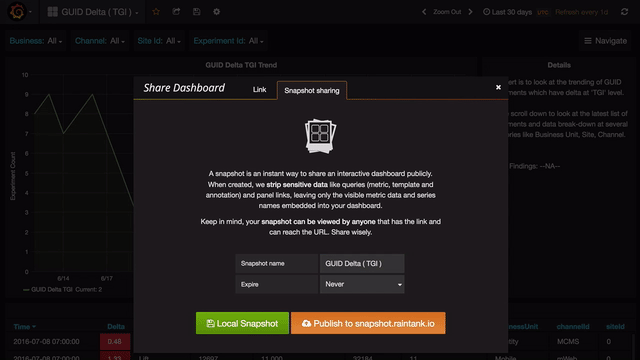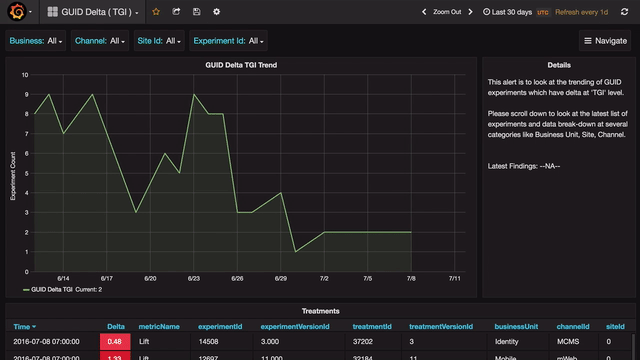
Any anomaly can be further analyzed in a drill-down view that shows details of that anomaly, which is again broken down at various levels.
Grafana allows quick duplication of each panel with a view that can be be easily modified. The user can select either an SQL or a drop-down interface to edit queries.
Search
There are several occasions during the triaging process when we need to quickly check if a given experiment or channel or country is experiencing any anomalies. The search feature provided by Grafana (through templating) allows us to do just that. The user can type or select from a drop-down to view details of all anomalies for a specific combination of filters.

Every dashboard can be customized and shared across the organization.
Setup and scale
InfluxDB (v 0.11-1) is installed on a single node, and so is Grafana (v 3.0.2). Each of these are hosted on the eBay cloud with 45 GB of memory, 60GB of disk space, and Ubuntu 14.04. Each day, around 2000 points are ingested into InfluxDB using a Scala client with ingestion time of around few seconds. Currently, the system contains seven months of historical anomaly data, taking around 1.5 GB disk space in InfluxDB and consuming approximately 19 GB of RAM. Anomaly data is archived on HDFS for recovery in case of system failure.
This dataset is minuscule compared to vast amounts of data that can be handled by InfluxDB, especially when assisted by its capability to be set up as a cluster for fault tolerance, which unfortunately is not supported beyond v 0.11-1.
Conclusion
The anomaly monitoring platform is the cornerstone for monitoring anomalies in experiments at eBay. It is becoming a single point for monitoring, sharing, and searching for anomalies in experiments for anyone in the company who runs experiments on the Experimentation platform. Its ability to be self-service (thanks to Grafana) in terms of creating new dashboards for new datasets is what makes it stand out.
There are several measures and metrics that determine if a experiment is experiencing an anomaly. If the thresholds are breached, the experiment is flagged and a consolidated email notification is sent out. It’s always been discussed in Grafana circles as to when alerting is coming (Winter has come, so will alerting), and it seems that alerting is actually coming to Grafana, enabling users to set alert thresholds for every metric that is being monitored, right from the dashboard.
References
- Grafana and Grafana Live Demo
- InfluxDB and InfluxDB Benchmark
- InfluxDB Scala Client, by paulgoldbaum
- GIFs were created using GIPHY Capture.
- The block diagram was created using Gliffy.