Large development teams with a sizable code base have two conflicting needs: code sharing and rapid developer setup (agility). Teams who are working on different features need to modify common projects and source elements. While code ownership helps, members of the same team invariably need to touch the same components across different features – or even the same features! Additionally, as ownership itself changes over time, developers other than the original authors need to enhance features or resolve issues.
The problem facing large development teams stems from more than source-level conflicts and SCM code merges or promotions – which, in our experience, are well bounded. The more fundamental problem has to do with enabling teams to set up their development environments rapidly while working with a code base that is not only large but has a high velocity of changes.
Between the need for code sharing and the need for developer setup agility, code sharing often receives priority as it avoids duplicating code and reinventing the wheel. In this two-part post, we discuss our experience with providing rapid developer setup.
The size of the problem
We will first consider quantitative aspects of the problem before looking at our journey to solutions. The problem involves both the number of changes and the velocity of the changes. The eBay code base consists of hundreds of thousands of source elements (with total lines of code in the tens of millions). The applications – which comprise web, services, messaging, and batch style – number in the thousands. It is common for an application to use tens of thousands of source elements. The elements themselves are contributed by different teams and are shared with other applications.
| Code Type | Count |
| Source elements | 100,000’s |
| Source elements per application | 10,000’s |
| Applications | 1000’s |
| Features per month | 100’s |
| Source elements changed per feature | 100’s (sometimes 1000’s) |
| Projects | 1000’s |
| Source elements per project | 10’s-100’s (sometimes 1000’s) |
Code base changes take the form of new features, which require modifying, adding, and (sometimes) removing source elements. eBay is a fast-paced environment with hundreds of teams; every month, we roll out hundreds of features. The following chart shows the number of source elements that features touch.
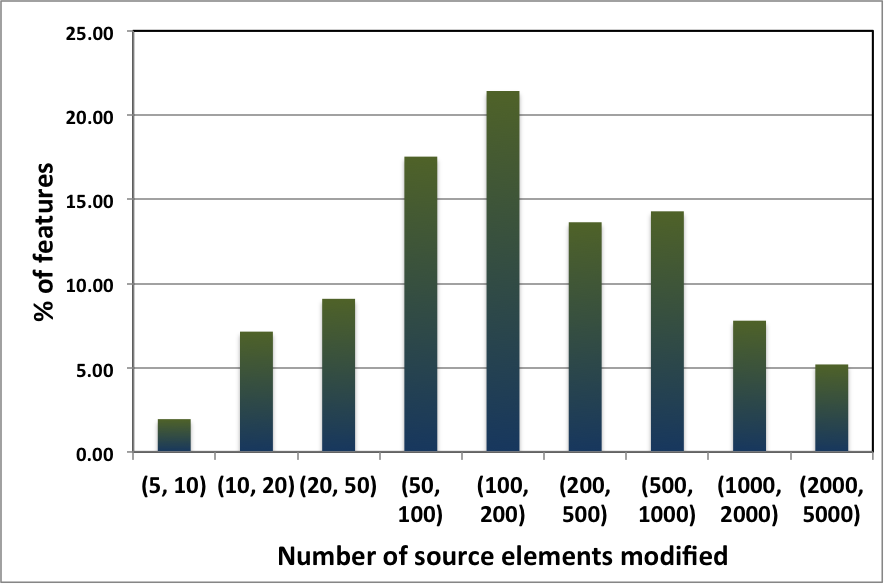
The X-axis is a log-like scale indicating the number of elements modified. The Y-axis shows the percentage of features matching each bucket. The data distribution is fairly normal, with a median of 100 to 200 source elements. Compared to the overall code base size, the per-feature change is less than 1% of applications. However, with hundreds of features rolled out per month, these changes compound quickly.
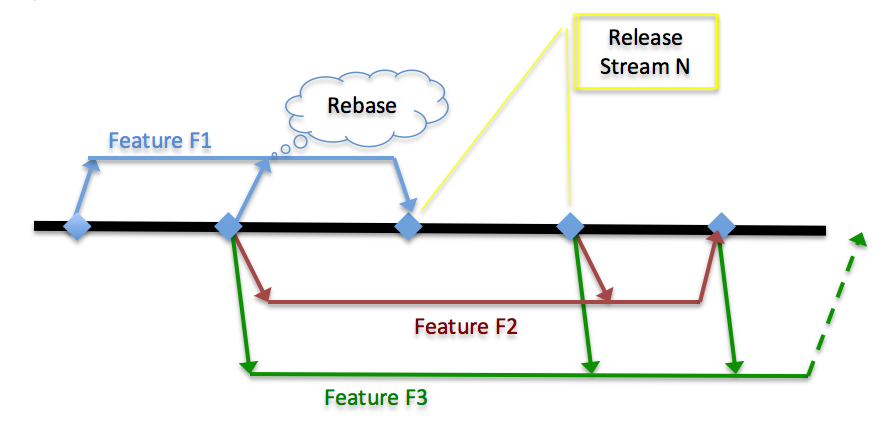
In addition, the code base dynamically changes across features. As modifications for individual features are validated and rolled out, later features pick up modifications from earlier features as they themselves are validated and rolled out.
Setup time
The time involved in setting up the development environment consists of the following activities:
1. Determining the target set of source elements (can be for multiple applications)
2. Provisioning (downloading) of the target set of elements
3. Setting up the development environment in an IDE
4. Compiling source elements such as Java source code
Although we find that practices like service orientation, binary dependencies, and code ownership help minimize code-level coupling, quick setup challenges still exist in large and fast-paced environments. The following sections describe eBay’s own evolution toward providing a faster and more reliable development environment.
Binary bundles
An application typically has several thousand source elements. Instead of provisioning and compiling all of those elements, the setup problem is simplified by consuming many of the elements in binary form. Already-compiled binary bundles diminish setup time by reducing the number of source elements that need downloading and compiling. The release stream tags the binary bundles that are released; different features can consume the bundles based on the release stream.
Feature teams can consume some projects as source while consuming many others in binary form. Source projects are required only where code authorship is required. As source projects take longer to set up, teams are encouraged to use them only for the projects that they expect to modify. The rest is consumed as binary bundles, to which the source is attached.
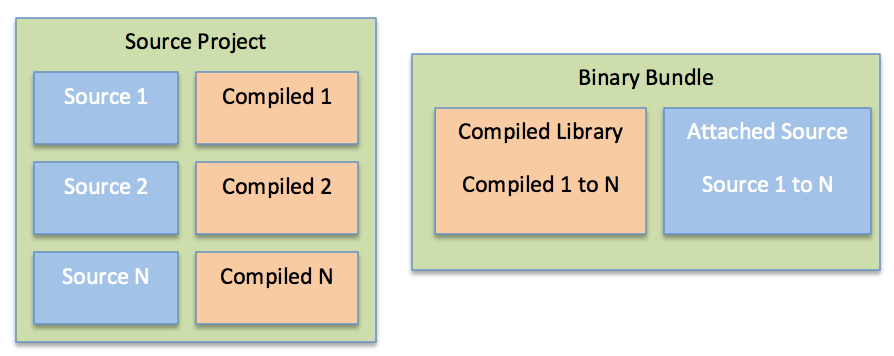
The binary bundle approach has clear advantages in reducing the number of source elements that need to be dealt with in the development environment. With this approach, the release streams are a vehicle for contributing changes that can be consumed later by other features. This methodology has also been adopted in the open-source world – for example, with the Apache Maven build tool and with increasingly popular binary repositories.
One of the challenges with the binary bundle approach is managing the bundles per release stream. This approach also requires the development team to identify the set of bundles that need authorship and thus need to be consumed as source. Furthermore, storing binary bundles at the release-stream level does not provide feature-level isolation. These shortcomings are discussed next.
Binary bundles with feature isolation and round-tripping
Feature-level isolation is required because features are developed in parallel and have overlapping code areas. In addition, features might be in early stages of development or might be developed in an experimental manner; changes from such features, in the form of binary bundles, should not be shared with others. With feature isolation, modified bundles are not shared until they have gone through appropriate validations and rollout. In other words, we desire to limit sharing when features are actively under development, and to encourage sharing after those changes have been rolled out.
To provide feature isolation, a common repository with release and snapshot versions does not suffice, as that approach is meant to encourage sharing. We use a per-feature binary repository to achieve feature isolation.
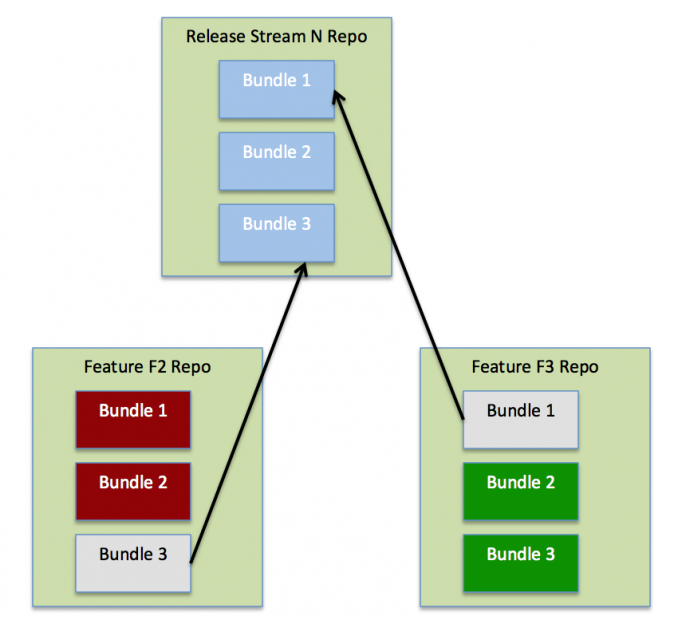
As individual features change only a small set of bundles, a complete binary repository per feature leads to duplication of binary bundles. We use hierarchical binary repositories to avoid duplication of bundles and to improve efficiency. Only bundles that are modified by features are placed in the feature repository. The rest of the bundles are obtained from higher-level repositories such as those from the release stream. This approach is similar to hierarchical management of source code in an SCM system (trunk -> branch 1 -> branch 2). In addition to the hierarchical binary repository, the local cache of these bundles is stored in a hierarchical manner to encourage sharing of common bundles across different features.
Another aid to rapid developer setup is dynamic conversion of binary bundles to source and vice versa. This conversion ability enables development to start before all of the projects that need source authorship have been identified. Furthermore, it encourages teams to start with a small set of source projects and to consume most (or even all!) in binary form. When the team realizes the need for source authorship, the appropriate projects are converted from binary to source. During conversion, the system determines source elements, provisions (downloads) them, compiles them, and appropriately adjusts project dependencies.
Once the authoring is completed, the projects can be converted back to binary form. This reverse conversion picks up binary bundles with the recent changes that have been made to those bundles.
The main challenge with this approach is managing the hierarchical repository, including timely updates as feature changes are committed. The hierarchical repository itself needs to point to different release streams as a feature is rebased. This approach still involves numerous source elements if the number or size of projects is large.
Binary bundles with source element changes
As discussed earlier in this post, most of our feature changes consist of hundreds of source elements. We find that these changes occur across tens of different projects. The chart below summarizes project size and usage in our environment.
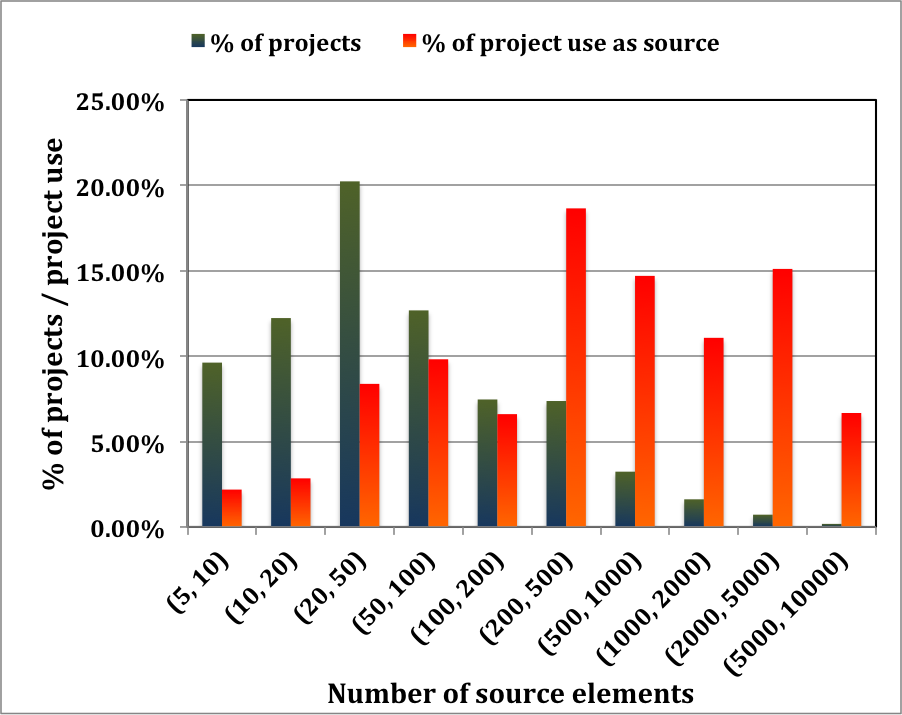
The X-axis identifies the number of source elements in a project. The green bars show the percentage of projects that match a given bucket, and the red bars show the distribution of projects that are used as source. The median project size is about 50 to 100 elements, and we have a small number of projects that have more than 1000 elements. However, while small in number, the large projects get used disproportionately, to the extent where the largest of them are used significantly more compared to their counts.
We find that projects don’t start out being large; rather, some grow huge because many features use them and contribute to them. As these projects grow by contribution, many features consume them in source form. Due to their size, these source projects drastically increase development setup time.
To avoid such issues, we use various approaches: splitting large projects into several small projects, decoupling applications from common code areas, creating meta-information (DSL) instead of compiled source code, etc. These are all valid ways of addressing the problem. In our experience, it is easier to start with an approach that incorporates these concepts rather than changing to such an approach later, because of the pervasive nature of changes that touch large numbers of projects.
Another way of achieving rapid setup in the presence of large projects is by using source element changes in combination with binary bundles. When a project needs source authorship, instead of having all elements come in source form, we include a small set of the elements that are modified or that need authorship. The rest of the elements continue to come from binary bundles. We achieve this approach by setting the classpath such that compiled source elements take precedence over the elements coming in binary form.
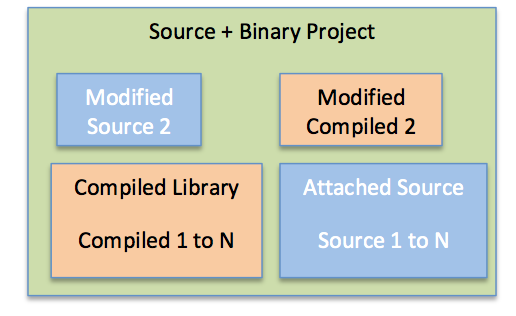
The challenges with this approach include setting up the development environment while incorporating others’ feature changes, and dealing with non-source elements that are used for prebuilds. Given the limited number of source elements that change by feature, we are starting to adopt this approach in a limited fashion and are finding that it has potential to work well.
In the second part of this post, we will describe how we use the Eclipse IDE to optimize working with both source elements and binary bundles.