The problem
We were working on a problem that involved processing workflows in the cloud. The problem was how we design a system that is scalable and fault tolerant, allowing dynamic allocation of cloud nodes to every step in the workflow.
To explain with an example, imagine a workflow like the following:
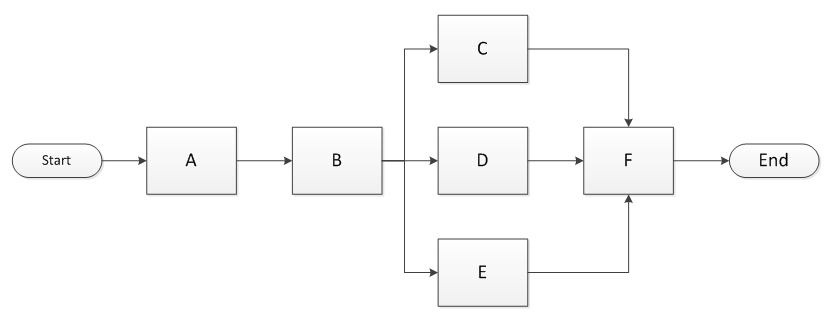
Diagram A
We need to execute A based on a trigger, followed by B; then we need to execute C, D, and E in parallel; and when they are complete, we need to execute F, which will trigger the end of the flow. There is a strict dependency hierarchy in the above graph that needs to be followed as we visit each node. The problem was that we needed to process a series of different independent workflow graphs like the above, but depending on the trigger. So we were faced with two potential issues:
- How do we execute different workflows in a generic, coherent manner?
- How do we scale our solution so that we have a system where we can run thousands or more arbitrary workflows concurrently in the cloud?
Initial idea
We started with a brute-force idea: Why not just hard-code all of the workflows (initially we had just a handful)? We could have, for instance, six nodes running each of the tasks corresponding to the diagram above, and the tasks could communicate state information via a shared database. This primitive approach worked well initially. All of the tasks could run concurrently on different nodes and would start doing actual work only when the dependency was met as per the database state.
However, we started facing problems when the number of workflow variations increased. We also had an issue hard-coding the dependency above since, for instance, task B depended on A and it was harder to insert a new task between the two. Moreover, the larger we got the trickier it became to maintain, enhance, and optimize the system.
Our solution
We started hashing out ideas on an effective solution that is quick and easy and that can work with all of the eBay configurations. We looked at each problem and took a deep dive on it.
- How do we execute different workflows in a generic, coherent manner?
The best approach we came up with for this first problem was to use metadata services. Each of the workflows was defined as part of the metadata based on the trigger point type. So for instance, for the above diagram we defined metadata that explicitly stated these dependencies. There are multiple ways this approach can be accomplished. One way is to use the GraphML library. We can then define the above graph using GraphML XML to define all of the dependencies. If the use case is a lot simpler, another way might be to create a table of tasks, names, and sequence numbers showing the ordering to be followed. The actual representation of the graph-based workflow can be done in multiple ways, and then we need services to assemble the metadata and isolate the implementation details from all of the clients.
This first problem was the easier one to deal with.
- How do we scale our solution so that we have a system where we can run thousands or more arbitrary workflows concurrently in the cloud?
To deal with this second problem, we wanted to start by getting rid of the static bounding of tasks and nodes. The aim was to make the bounding dynamic based on load on the platform. So we wanted to come up with two things:
- A way of assigning and running tasks on a node
- A way of load-balancing the above assignment
The second item immediately prompted us towards a load balancer. It’s a fairly common approach now, and we needed just that: a load balancer that will know the state of the pool and allocate tasks to all nodes on the cloud. Therefore, we needed a way to describe the state of each node. We came up with a simple format consisting of node name, tasks to execute, each task’s current run status, etc. The load balancer then has to keep track of this data, which represents what’s happening within the pool. Based on this data, the load balancer can decide which nodes have fewer tasks or are overloaded, and can allocate accordingly.
Now onto the first item: once we have this data we can have a daemon service/task running on all of the nodes in the pool which will then just look for this data and spawn the given task that is assigned to it. The last thing we wanted was to form a queue of all incoming trigger types, which would result in a series of workflows, and then to dynamically come up with the workflow graph by reading this queue.
We were putting all of these dependencies in place and came up with a really simple, elegant, yet powerful solution that achieved what we wanted to do. The platform met all of our constraints and was scalable and, from an implementation perspective, easy to start with. Our project actually involved more business logic that corresponded to the specific workflows, but we also came up with this generic platform for putting it all together.
Our final design looked something like this:
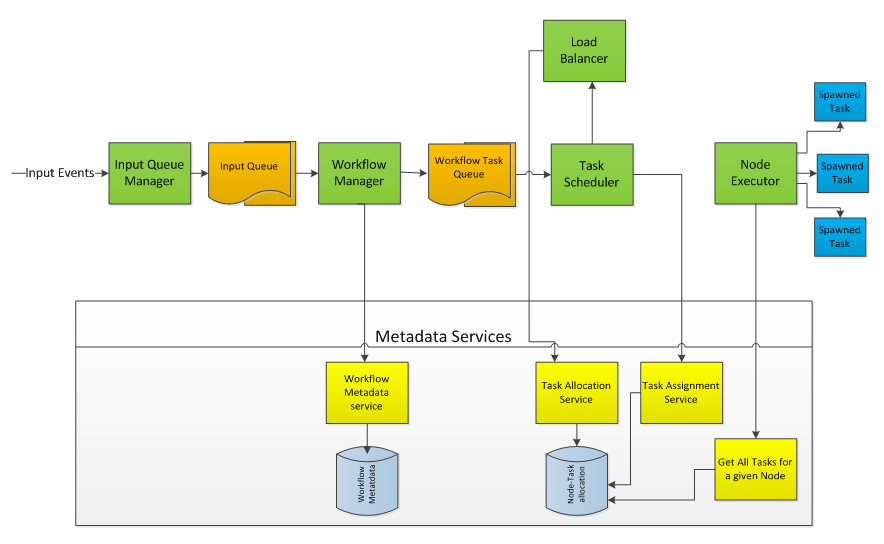
Diagram B
(For simplicity, other design aspects like monitoring, disaster recovery, and node provisioning are omitted from the above diagram.)
Let’s go through some details about each of the above components.
- Input Queue Manager — The role of an Input Queue Manager is to maintain a queue of what’s to be processed by taking the input events and sorting them by time of arrival. Note that these events can be input files, crontab-like scheduled tasks, or any set of external services/dependencies that need a workflow to be processed downstream. The role of the Input Queue Manager is also to avoid duplicates and discard invalid requests going into the pipeline.
- Workflow Manager — This is one of the core components of the platform. Given an input queue type, the Workflow Manager looks for the workflow metadata services to get an instance of workflow tasks to be executed. The metadata services have pre-configured data backed by all possible input types that result in the workflow. Again referring to Diagram A above, this sample workflow can be configured as an input to a given file, a service call, etc. The output is a queue of workflow task instances that need to be executed as per the graph ordering.
- Task Scheduler — The primary purpose of this component is to schedule tasks on any node in the pool. Figuring out a good node to schedule requires the help of a load balancer, which will return a healthy node back to the Task Scheduler. It then uses the Task Assignment Service to allocate a task to the selected node.
- Load Balancer — This component calls the Task Allocation Service, which constructs the complete graph of the state of the pool at any given instant. The Load Balancer then uses this graph to come up with the best possible node that can be assigned to process a given task. Load balancing can be implemented in multiple ways, from round robin to random to load-based. The Load Balancer can also be extended to have knowledge of all of the tasks in the system, and can use machine learning to extract average times, based on past performances, as training data. Again, depending on the use case, load balancing can be altered as the platform matures.
- Node Executor — This is a relatively simpler component. The primary function of this is to find out all the assigned tasks and then just spawn them as separate processes on that node. All the nodes in the pool need to have these executors as daemon processes which look out for any new tasks that need to be spawned. Each task that runs can do a heartbeat ping to these executors so that they can be made smarter in cases where things get stuck or node restarts.
The above model can easily be extended to provide better fault tolerance by putting master/slave dependencies on components. Also, cases like node restarts, nodes going down when tasks are running, etc. can be accommodated by adding a monitor to the pool to keep track of what is going on in the overall system, and then using the Load Balancer to perform the necessary steps for automatic failover/recovery.
Note that using the above system we were not only able to process DAG workflows in the cloud, but also were able to process simple crontab-scheduled tasks dynamically and not bounding it to any particular node in the cloud.
We are in the process of open-sourcing some of our solution. We’ll announce the GitHub location once we’re ready.