Introduction
Earlier this year in our Seller Hub, we added a new feature called Terapeak Product Research to help eBay sellers determine how to best price item listings, optimize their shipping policy and view sell-through rate and trends.
Keyword search is one of the most important elements powering the Terapeak Product Research tab. With Terapeak’s search functionality, sellers can locate items of interest among buyers; gain insight into the keywords that top-selling listings feature in their titles; see keyword suggestions that may surface their listings in the search results; and help place them in the buyer’s line of sight.
To provide these capabilities, a data storage must be selected, along with an indexing engine that provides full text search, performs well, has aggregation capabilities and scales well. It’s also important to make sure the delay is small between an event happening and the corresponding records of this event stored in the eBay database, making the system "near real-time." Using Elasticsearch for data storage, the next step is to implement a reliable and fault tolerant, data streaming ETL (Extract Transform Load) pipeline to catch and record the marketplace events.
Data Migration/Ingestion Architecture
The data pipeline has two major components: realtime and backfill data processing.
-
The realtime pipeline processes real-time data from transaction events (when someone buys an item on eBay) and closed unsold listings events (listings that did not sell and got closed).
-
Backfill pipeline is for the purposes of backfilling historical data (in case of bug fixes or retroactively adding new data points to historical data).
Realtime Pipeline
The realtime pipeline processes 6-8 million transaction records and 10-15+ million closed unsold listings records per day.

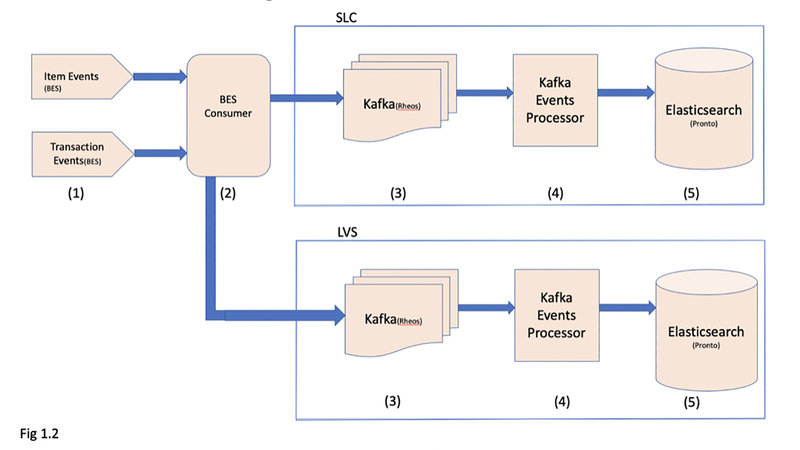
As the events occur in step 1, the BES Consumer (step 2) receives notifications and enriches the payloads before pushing them to Kafka (step 3). Kafka Events Processor (step 4) then loads these events into Elasticsearch (step 5). Step 3 and 4 are required so that documents can be loaded into Elasticsearch at a controlled rate so that its search performance is not impacted.
The system must satisfy the following constraints:
-
High availability: The system should be able to continue filling data in Elasticsearch despite disconnection between the components.
-
Failure detection: The system should be able to detect if any component stops functioning.
-
Idempotency: The system must always have the most recent version of the document. Replaying the log of events should not violate this rule. For instance, if the messages in Kafka (step 3) are reprocessed via (step 4), Elasticsearch should contain the most recent version.
High Availability
This is achieved by use of two parallel zones in different regions: Salt Lake City and Las Vegas. The BES Consumer writes the events to two Kafka clusters instead of just one, after which they end up within their respective Elasticsearch Cluster. The user traffic is directed to either of these clusters based on their geo-location.
Modified Architecture: Stage 1

(Fig 1.2) Architecture makes sure eBay receives data in both clusters without addressing redundancy or fault tolerance.
Modified Architecture: Stage 2

(Fig 1.3) The Kafka Events Processor (step 4) follows a primary-secondary configuration where two copies of the processor are run in each region. The first copy is called primary and writes to the Elasticsearch of the same region; the second copy is called secondary and writes to the Elasticsearch of the other region.
Therefore, if one part of the pipeline in a given region is broken for some time, Elasticsearch in that region will not see a data delay. BES Consumer (step 2) and Kafka Events Processor (step 4) are both deployed on multiple machines and hence highly available by design.
If the data from both primary and secondary processors is indexed in Elasticsearch, it can create unnecessary load on Elasticsearch. Therefore, data from secondary processors does not get indexed unless those documents (by id) do not exist yet (which means the primary component is falling behind) or existing documents have older versions (i.e. primary is writing stale documents).
Failure Detection in Kafka Events Processor
As mentioned in Fig 1.3, Kafka Events Processor runs in step 4 source-destination configurations. Each configuration runs on six hosts as a continuous batch job via an internal eBay tool called Altus. Altus is an Application Lifecycle Management system which provides the ability to create, manage and deploy applications in production. It also provides alerting and monitoring capabilities via another internal tool called SherlockIO (which uses Prometheus). The following failure scenarios are possible:
A. Single Host level failure: If the host goes down, Altus will send alerts. If the host is under heavy workload (high RAM, CPU), Sherlock will send alerts.
B. Record level failure: If Kafka Events Processor gets a corrupted payload that cannot be converted, it creates a new failure record that contains the original payload along with the error message and stack trace and writes it to a separate Elasticsearch index called failure index. This failure index is separately monitored.
C. Kafka events processor failure: The processor itself could fail due to a variety of reasons. Introducing a mechanism in the processor where, apart from writing the main payload to Elasticsearch, metadata is also written about the entire batch of messages and mitigates failure.
Example metadata document:

This metadata document is written to a separate monitored index. An alert is generated when the monitor does not see any new data with a recent timestamp (calculated by “end_time” in above example) in the metadata index.

The system must also act gracefully (e.g. not produce duplicate records) when the same record is sent multiple times by the events stream or one batch job fails part way, and another batch job processes the same message again. This is achieved by using listingId and transactionId as "id" and external versioning mechanism in Elasticsearch [1]. If a document with a given “id” is already stored, it will be accepted from primary (based on “external_gte” versioning setting) and not accepted from secondary, which uses “external_gt” versioning logic.

Backfill Pipeline
A backfill component is added to the pipeline to address the following cases:
-
When BES fails to provide an event, it is missed completely.
-
When there is a bug in data processing and the data in Elasticsearch needs to be corrected.
-
When a new data field needs to be added that will be available in new incoming data, but needs to be appended to old data in Elasticsearch retroactively.

The backfill component reads the data (using Spark SQL) from Hive tables in Data Warehouse (which is a different data source than Realtime Events generator) and loads data into Swift cloud storage (Openstack), from where it is finally loaded to Elasticsearch. This allows the system to address nearly any use case, which is not addressed directly by the realtime pipeline and retroactively backfill data in Elasticsearch.
Other Considerations
Troubleshooting
An important part of the system is being able to troubleshoot. This requires the system user to be able to distinguish between various data sources (primary, secondary, backfill) and data from different code versions (backfill cycles, real time code changes and milestone). Using the “origin” field as part of the Elasticsearch document addresses this need.
Metrics
There are two Elasticsearch clusters. Each individual cluster:
-
is processing 20 million documents per day (roughly 250 messages per second);
-
has around 900 indices, 146 Nodes (4.3 TB of RAM, 29 TB of disk space); and
-
is able to serve 200 requests per second (each request may hit different numbers of indices based on user input date range).
Final Architecture
