Deployment to the cloud is an evolving area. While many tools are available that deploy applications to nodes (machines) in the cloud, zero deployment downtime is rare or nonexistent. In this post, we’ll take a look at this problem and propose a solution. The focus of this post is on web applications—specifically, the server-side applications that run on a port (or a shared resource).
In traditional deployment environments, when switching a node in the cloud from the current version to a new version, there is a window of time when the node is unusable in terms of serving traffic. During that window, the node is taken out of traffic, and after the switch it is brought back into traffic.
In a production environment, this downtime is not trivial. Capacity planning in advance usually accommodates the loss of nodes by adding a few more machines. However, the problem becomes magnified where principles like continuous delivery and deployment are adopted.
To provide effective and non-disruptive deployment and rollback, a Platform as a Service (PaaS) should possess these two characteristics:
- Best utilization of resources to minimize deployment downtime as much as possible
- Instantaneous deployment and rollback
Problem analysis
Suppose we have a node running Version1 and we are deploying Version2 to that node. This is how the lifecycle would look:
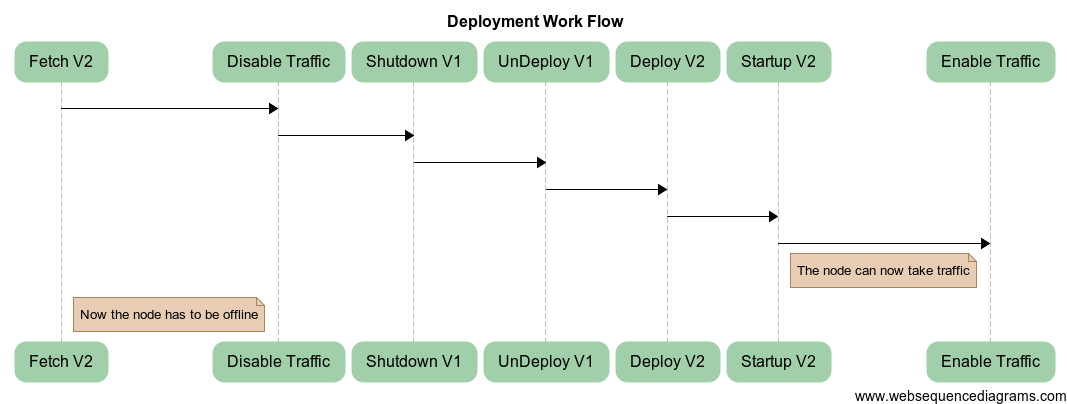
Every machine in the pool undergoes this lifecycle. The machine stops serving traffic right after the first step and cannot resume serving traffic until the very last step. During this time, the node is effectively offline.
At eBay, the deployment lifecycle takes a reasonably sized application about 9 minutes. For an organization of any size, many days of availability can be lost if every node must go into offline phase during deployment.
So, the more we minimize the off-traffic time, the closer we get to instant/zero-downtime deployment/rollback.
Proposed solutions
Now let’s look into a few options for achieving this goal.
A/B switch
In this approach, we have a set of nodes standing by. We deploy the new version to those nodes and switch the traffic to them instantly. If we keep the old nodes in their original state, we could do instant rollback as well. A load balancer fronts the application and is responsible for this switch upon request.
The disadvantage to this approach is that some nodes will be idle, and unless you have true elasticity, it will amplify the node wastage. When a lot of deployments are occurring at the same time, you may end up needing to double the capacity to handle the load.
Software load balancers
In this approach, we configure the software load balancer fronting the application with more than one end point so that it can effectively route the traffic to one or another. This solution is elegant and offers much more control at the software level. However, applications will have to be designed with this approach in mind. In particular, the load balancer’s contract with the application will be very critical to successful implementation.
From a resource standpoint, both this and the previous approach are similar; both use additional resources, like memory and CPU. The first approach needs the whole node, whereas the other one is accommodated inside the same node.
Zero downtime
With this approach, we don’t keep a set of machines; rather, we delay the port binding. Shared resource acquisition is delayed until the application starts up. The ports are switched after the application starts, and the old version is also kept running (without an access point) to roll back instantly if needed.
Similar solutions exist already for common servers.
Parallel deployment – Apache Tomcat
Apache Tomcat has added the parallel deployment feature to their version 7 release. They let two versions of the application run at the same time and take the latest version as default. They achieve this capability through their context container. The versioning is pretty simple and straightforward, appending ‘##’ to the war name. For example, webapp##1.war and webapp##2.war can coexist within the same context; and for rolling back to webapp##1, all that is required is to delete webapp##2.
Although this feature might appear to be a trivial solution, apps need to take special care with shared files, caches (as much write-through as possible), and lower-layer socket usage.
Delayed port binding
This solution is not available in web servers currently. A typical server first binds to the port, then starts the services. Apache lets you delay binding to some extent by overriding bindOnInit, but still the binding occurs after the connector is started.
What we propose here is the ability to start the server without binding the port and essentially without starting the connector. Later, a separate command will start and bind the connector. Version 2 of the software can be deployed while version 1 is running and already bound. When version 2 is started later, we can unbind version 1 and bind version 2. With this approach, the node is effectively offline only for a few seconds.
The lifecycle for delayed port binding would look like this:
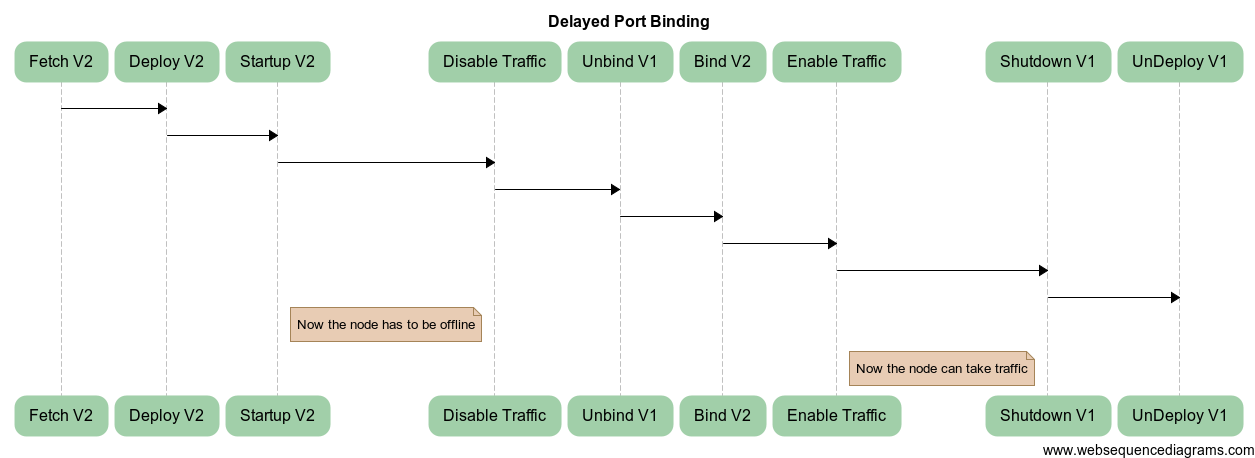
However, there is still a few-second glitch, so we will look at the next solution.
Advanced port binding
Now that we have minimized the window of unavailability to a few seconds, we will see if we can reduce it to zero. The only way to do that would be to bring version 2 up before version 1 goes down. But first:
Breaking the myth: ‘Address already in use’
If you’ve used a server to run an application, I am sure you’ve seen this exception at least once. Let’s consider this scenario: We start the server and bind to the port. If we try to start another instance (or another server with the same port), the process fails with the error ‘Address already in use’. We kill the old server and start it again, and it works.
But have you ever given a thought as to why we cannot have two processes listening to the same port? What could be preventing it? The answer is “nothing”! It is indeed possible to have two processes listening to the same port.
SO_REUSEPORT
The reason we see this error in typical environments is because most servers bind with the SO_REUSEPORT option off. This option lets two (or more) processes bind to the same port, provided the application that bound the first process had this option set while binding. If this option is off, the OS interprets the setting to mean that the port is not to be shared, and it blocks subsequent processes from binding to that port.
The SO_REUSEPORT option also provides fair distribution of requests (important since threading suffers from bottlenecks in multi-cores). Both of the threading approaches—one thread listening and then dispatching, as well as multiple threads listening—suffer from the under/over utilization of cycles. An additional advantage of SO_REUSEPORT is that it takes care of sending the datagram from the same client to the same server process. However, it has a shortcoming: packets might be dropped if new processes are added or removed on the fly. This shortcoming is being addressed.
You can find a good article about SO_REUSEPORT at this link on LWN.net. If you want to try this out yourself, see this post on the Free-Programmer’s Blog.
The SO_REUSEPORT option address two issues:
- The small glitch between the application version switching: The node can serve traffic all the time, effectively giving us zero downtime.
- Improved scheduling: Data indicates (see this article on LWN.net) that thread scheduling is not fair; the ratio between the busiest thread versus the one with the least connections is 3:1.
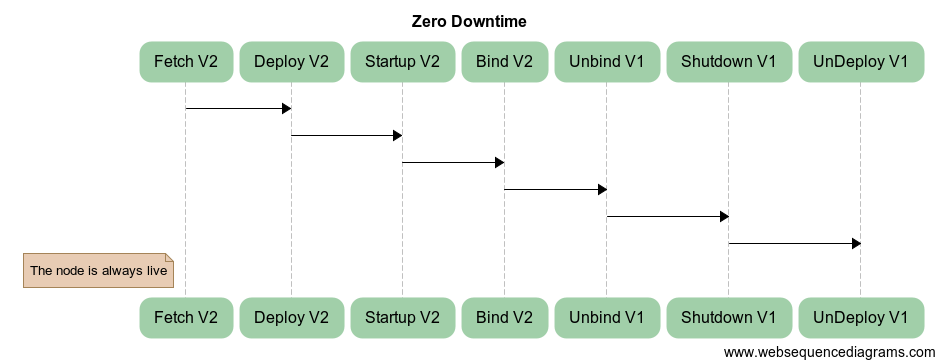
Please note that SO_REUSEPORT is not the same as SO_REUSEADDRESS, and that it is not available in Java as not all operating systems support it.
Conclusion
Applications can successfully serve traffic during deployment, if we carefully design and manage those applications to do so. Combining both late binding and port reuse, we can effectively achieve zero downtime. And if we keep the standby process around, we will be able to do an instant rollback as well.