Around 1500 A/B tests are performed on eBay across different sites and devices on a yearly basis. Experimentation forms a key business process at eBay and plays an important role in the continual improvement of business performance through the optimization of the user experience. Different data insights from these tests enable users to answer important questions such as “How will this new product feature benefit eBay?” or “Does this new page layout improve user engagement and increase GMB?”
Testing allows business units to conceptually explore new ideas with respect to page content and style, search algorithms, product features, etc., which can vary from subtle to radical variations. Such test variations can be easily targeted to segments of the total customer population based on the desired percentage/ramp up and contextual criteria (geographic, system or app-specific), providing a level of assurance before launching to a broader audience.
Experiment Lifecycle

Lifecycle of an experiment at eBay
All the experiments begin with an idea. The first step is to prepare a test proposal document, which has the summary of what is being tested, why it’s being tested, the amount of traffic assigned, and what action is going to be taken once the results are published. This document will be reviewed and approved in TPS council meetings every week.
The next step is for the test operations team to interact with the product development team to find the right slot for the test schedule, understand the impact of interaction with other tests, and then set up the experiment, assigning necessary traffic to treatment and control, and launch it after smoke testing (a minimal amount of traffic is assigned to make sure everything is working as expected) is successful and necessary validation steps are completed.
The next step is the launch of the experiment. Tracking the experiment will immediately begin, and data is collected. Different reports providing necessary insights will be generated on a daily basis and for the cumulative period through the data collection period. The final results will be published to a wider audience after the experiment is complete. This completes the life cycle of an experiment.
Experimentation reporting
This post will provide a quick overview of the reporting process. Before going further, let’s define some basic terms related to experimentation.
Definitions
- Guid: A visitor is uniquely identified with a GUID (Global Unique ID). This is a fundamental unit of our traffic that represents the browser on a machine (PC or handheld) visiting the site. It is identified from the cookies that a particular eBay site drops on the user’s browser cache.
- UserId: A unique ID assigned to each registered user on the site.
- Event: Every activity of the user captured on the site.
- Session: All the activity of the user until 30 minutes of inactivity elapses within a day. The aggregate of many events constitute a session.
- GUID MOD: 100% of the eBay population is divided into 100 different buckets. A Java hash will convert the GUID into a 10-digit hash, and the modulo of the GUID is extracted from this hash, which represents the bucket that the GUID is assigned. A specific GUID will never fall into two different GUID MODs.
- Treatment and control: The feature to be tested is referred as “treatment,” and “control” is the default behavior.
- Versions: Any change in the experiment during the active state will create a new version of the experiment. Major and Minor versions are created based on the change’s impact on the experiment.
-
Classifier: A classifier is one of the primary dimensions on which we slice the data and report for different dimensions and metrics under it:
- Total GUID Inclusive (TGI) — All the GUIDS that are qualified for a particular treatment or control
- Treated — All the GUIDS that have seen the experience of the treatment
- Untreated — All the GUIDS that are qualified but have not seen the experience of the treatment
Overview
The following figure shows a simplified view of the reporting process.
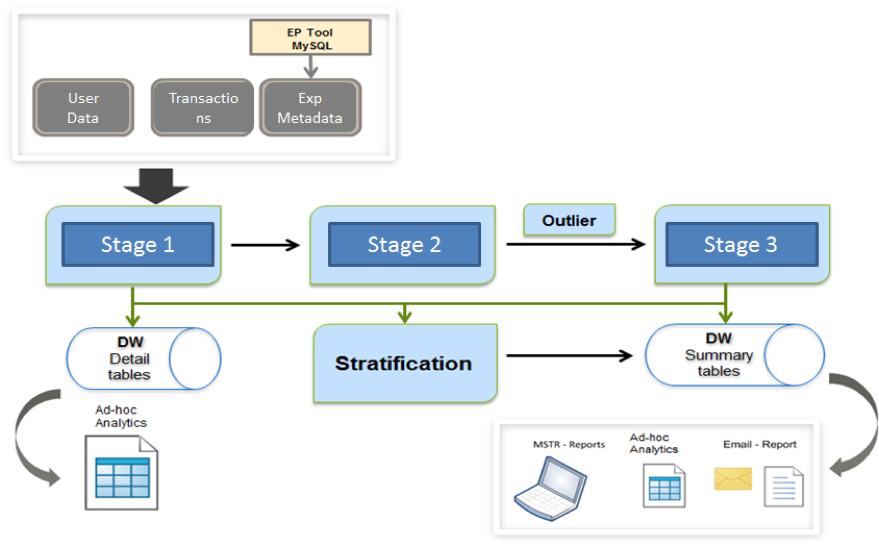
Upstream data sets
Let us outline the upstream data sets that the process depends on. The data is stored in Hadoop and Teradata systems.
- User data: Event-level raw data of the user activity on the site, updated every hour.
- Transaction and activity data: Data sets that capture the metric-level activity of the user such as bid, offer, watch, and many more.
- Experiment metadata: Metadata tables that provide information about the experiments, treatments, GUID MOD, and various other parameters.
Stage 1
Every day the process first checks for the upstream data sets to be loaded, and stage 1 will be triggered after all the data sets are available. In this stage, detail data sets at the GUID and Session levels are generated from the event level data.
Treatment session: This is one of the primary data set which has GUID and Session-level data at the treatment and version levels. There are various indicators of different dimensions that we will not cover in this post.
Transaction detail data set: All the activity of GUID and Sessions related to transaction metrics such as revenue are captured here. This data set will not have any treatment-level data.
Activity Detail data set: Same as the transaction detail data set but for activity-level metrics such as bid, offer, bin, watch and so on, which are captured here.
There are around six more data sets we generate on a daily basis. We will not go in details about them in this post. All the processing happens on Hadoop, and the data will be copied to Teradata for analysts to access them.
Stage 2 and Outlier Capping
The data sets generated in stage 1 act as upstream data sets for stage 2. In this stage, lots of data transformations and manipulations happen. Data is stored at the GUID, treatment, and dimension levels and stored in Hadoop. This data will not be moved to Teradata, because this stage acts like an intermediate step for our process. Outlier capping is applied to the metrics from the data sets populated from stage 2 to handle extreme values.
Stage 3
The output from the stage 2 is fed into the stage 3, which is the summary process. The data will be aggregated at the treatment, version, and dimension levels, and all the summary statistics are calculated in this step. The data is stored in Hadoop and copied over to Teradata for MicroStrategy to access this information and publish different reports.
Stratification
Post-stratification is an adjustment method in data analysis. It is used to reduce the variance of estimations. In stratification, subjects are randomized to treatment and control at the beginning of the experiment. After data collection, they are stratified according to pre-experiment features, so that subjects are more similar within a stratum than outside that stratum.
The overall treatment effect is then estimated by the weighted average of treatment effects within individual strata. Because the variance of the overall treatment effect estimation consists of variance due to noise and variance due to differences across strata, stratifying experiment subjects removes variance due to strata difference, and thus variance of the estimated overall treatment effect is reduced.
This process runs in parallel and generates stratified transactional metrics. The processing happens in Hadoop, and data is copied over to Teradata for access to different reports.
Scala, Hive, SQL, SAS, R, and MicroStrategy are some of the technologies and statistical packages we use throughout the process. Most of the processing happens in Hadoop, and minor manipulations occur in Teradata.
This concludes the main topic of this post. One of the critical aspects during this process is data quality, as inaccurate results can have impact on the decisions to be made. In the next post, we will talk about different data quality initiatives and how we are tackling them.
Happy Testing!