Business Benefits
As a recommender system team at eBay, we stress the user behavior during the recommendation process. The more user behavior we grasp, the more beneficial items we can recommend to each specific individual buyer. Flink is a very powerful tool to do real-time streaming data collection and analysis. The near real-time data inferencing can especially benefit the recommendation items and, thus, enhance the PL revenues.
Architecture
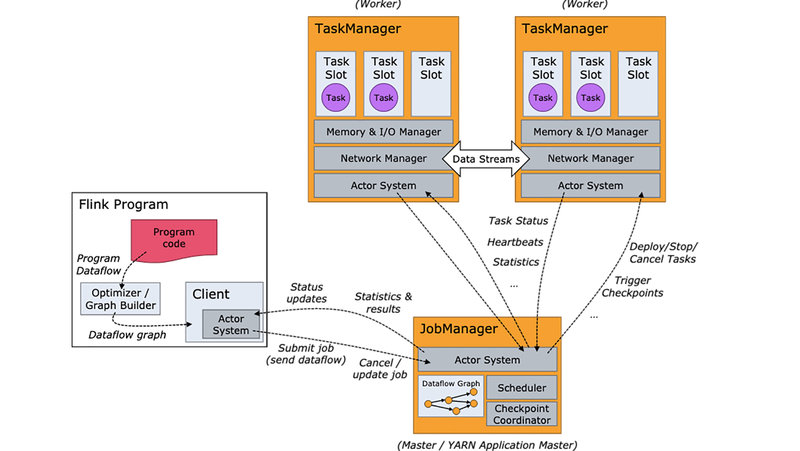
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.
JobManager
The JobManager has a number of responsibilities related to coordinating the distributed execution of Flink Applications: It decides when to schedule the next task (or set of tasks), reacts to finished tasks or execution failures, coordinates checkpoints and coordinates recovery on failures, among others.
TaskManager
The TaskManagers (also called workers) execute the tasks of a dataflow and buffer and exchange the data streams.
Task Slot
Each worker (TaskManager) is a JVM process and may execute one or more subtasks in separate threads. To control how many tasks a TaskManager accepts, it has so-called task slots.
Operators
Operators transform one or more DataStreams into a new DataStream. Programs can combine multiple transformations into sophisticated data flow topologies.
Basic Transformation
Map
Takes one element and produces one element.
![]()
FlatMap
Takes one element and produces zero, one or more elements.
![]()
Filter
Evaluates a boolean function for each element and retains those for which the function returns true.
![]()
KeyBy
Logically partitions a stream into disjoint partitions, each partition containing elements of the same key.
![]()
Reduce
A "rolling" reduce on a keyed data stream. Combines the current element with the last reduced value and emits the new value.
![]()
Fold
A "rolling" fold on a keyed data stream with an initial value. Combines the current element with the last folded value and emits the new value.
![]()
Aggregations
Rolling aggregations on a keyed data stream.

Window
Windows can be defined on already partitioned KeyedStreams. Windows group the data in each key according to some characteristic.
![]()
Physical Partitioning
Random Partitioning
Partitions elements randomly according to a uniform distribution.
![]()
Rebalancing (Round-robin partitioning)
Partitions elements round-robin, creating equal load per partition. Useful for performance optimization in the presence of data skew.
![]()
Rescaling
Partitions elements, round-robin, to a subset of downstream operations.
![]()
Broadcasting
Broadcasts elements to every partition.
![]()
Task Chaining and Resource Groups
Start New Chain
Begin a new chain, starting with this operator. The two mappers will be chained, and the filter will not be chained to the first mapper.
![]()
Disable Chaining
Do not chain the map operator
![]()
Windows
Windows are at the heart of processing infinite streams. Windows split the stream into “buckets” of finite size over which we can apply computations.
Window Assigners

Tumbling Windows
A tumbling windows assigner sets each element to a window of a specified window size. Tumbling windows have a fixed size and do not overlap.

Sliding Windows
The sliding windows assigner sets elements to windows of fixed length. Similar to a tumbling windows assigner, the size of the windows is configured by the window size parameter. An additional window slide parameter controls how frequently a sliding window is started.

Session Windows
The session windows assigner groups elements by sessions of activity. Session windows do not overlap and do not have a fixed start and end time, in contrast to tumbling windows and sliding windows. Instead a session window closes when it does not receive elements for a certain period of time, i.e., when a gap of inactivity occurs.
Window Functions
ReduceFunction
A ReduceFunction specifies how two elements from the input are combined to produce an output element of the same type.

AggregateFunction
An AggregateFunction is a generalized version of a ReduceFunction that has three types: an input type (IN), accumulator type (ACC) and an output type (OUT).

FoldFunction
A FoldFunction specifies how an input element of the window is combined with an element of the output type.

ProcessWindowFunction
A ProcessWindowFunction gets an Iterable containing all the elements of the window, and a Context object with access to time and state information, which enables it to provide more flexibility than other window functions.

Allowed Lateness
Flink allows to specify a maximum allowed lateness for window operators. Allowed lateness specifies by how much time elements can be late before they are dropped.

Joining
Window Join
Tumbling Window Join

When performing a tumbling window join, all elements with a common key and a common tumbling window are joined as pairwise combinations and passed on to a JoinFunction or FlatJoinFunction.

Sliding Window Join

When performing a sliding window join, all elements with a common key and common sliding window are joined as pairwise combinations and passed on to the JoinFunction or FlatJoinFunction.

Session Window Join

When performing a session window join, all elements with the same key that when “combined” fulfill the session criteria are joined in pairwise combinations and passed on to the JoinFunction or FlatJoinFunction.
 Interval Join
Interval Join

The interval join connects elements of two streams (we’ll call them A & B for now) with a common key and where elements of stream B have timestamps that lie in a relative time interval to timestamps of elements in stream A.

Timers
Both types of timers (processing time and event time) are internally maintained by the TimerService and enqueued for execution.
The TimerService deduplicates timers per key and timestamp (i.e. there is at most one timer per key and timestamp). If multiple timers are registered for the same timestamp, the onTimer method will be called just once.
Asynchronous I/O for External Data Access
Flink’s Async I/O API allows users to use asynchronous request clients with DataStreams. The API handles the integration with DataStreams, as well as handling order, event time, fault tolerance, etc.
Assuming one has an asynchronous client for the target database, three parts are needed to implement a stream transformation with asynchronous I/O against the database:
-
An implementation of AsyncFunction that dispatches the requests
-
A callback that takes the result of the operation and hands it to the ResultFuture
-
Applying the async I/O operation on a DataStream as a transformation
The following two parameters control the asynchronous operations:
-
Timeout: The timeout defines how long an asynchronous request may take before it is considered failed. This parameter guards against dead/failed requests.
-
Capacity: This parameter defines how many asynchronous requests may be in progress at the same time.
Working with State
Using Keyed State
The keyed state interface provides access to different types of state that are all scoped to the key of the current input element. This means that this type of state can only be used on a KeyedStream.
-
ValueState<T>: This keeps a value that can be updated and retrieved (scoped to key of the input element as mentioned above, so there will possibly be one value for each key that the operation sees). The value can be set using update(T) and retrieved using T value().
-
ListState<T>: This keeps a list of elements. You can append elements and retrieve an Iterable over all currently stored elements. Elements are added using add(T) or addAll(List<T>), the Iterable can be retrieved using Iterable<T> get(). You can also override the existing list with update(List<T>)
-
ReducingState<T>: This keeps a single value that represents the aggregation of all values added to the state. The interface is similar to ListState but elements added using add(T) are reduced to an aggregate using a specified ReduceFunction.
-
AggregatingState<IN, OUT>: This keeps a single value that represents the aggregation of all values added to the state. Contrary to ReducingState, the aggregate type may be different from the type of elements that are added to the state. The interface is the same as for ListState but elements added using add(IN) are aggregated using a specified AggregateFunction.
-
MapState<UK, UV>: This keeps a list of mappings. You can put key-value pairs into the state and retrieve an Iterable over all currently stored mappings. Mappings are added using put(UK, UV) or putAll(Map<UK, UV>). The value associated with a user key can be retrieved using get(UK). The iterable views for mappings, keys and values can be retrieved using entries(), keys() and values() respectively. You can also use isEmpty() to check whether this map contains any key-value mappings.
State Time-To-Live (TTL)
A time-to-live (TTL) can be assigned to the keyed state of any type. If a TTL is configured and a state value has expired, the stored value will be cleaned up on a best effort basis.

Checkpointing
The central part of Flink’s fault tolerance mechanism is drawing consistent snapshots of the distributed data stream and operator state. These snapshots act as consistent checkpoints to which the system can fall back in case of a failure.
Barriers
A core element in Flink’s distributed snapshotting are the stream barriers. These barriers are injected into the DataStream and flow with the records as part of the DataStream. Barriers never overtake records, they flow strictly in line. A barrier separates the records in the DataStream into the set of records that goes into the current snapshot, and the records that go into the next snapshot.


Operators that receive more than one input stream need to align the input streams on the snapshot barriers. The figure above illustrates this:
-
As soon as the operator receives snapshot barrier n from an incoming stream, it cannot process any further records from that stream until it has received the barrier n from the other inputs as well. Otherwise, it would mix records that belong to snapshot n and with records that belong to snapshot n+1.
-
Once the last stream has received barrier n, the operator emits all pending outgoing records, and then emits snapshot n barriers itself.
-
It snapshots the state and resumes processing records from all input streams, processing records from the input buffers before processing the records from the streams.
-
Finally, the operator writes the state asynchronously to the state backend.
Snapshotting Operator State
Operators snapshot their state at the point in time when they have received all snapshot barriers from their input streams, and before emitting the barriers to their output streams. At that point, all updates to the state from records before the barriers have been made, and no updates that depend on records from after the barriers have been applied. After the state has been stored, the operator acknowledges the checkpoint, emits the snapshot barrier into the output streams and then proceeds.
The resulting snapshot now contains:
-
For each parallel stream data source, the offset/position in the stream when the snapshot was started
-
For each operator, a pointer to the state that was stored as part of the snapshot

Savepoints
All programs that use checkpointing can resume execution from a savepoint. Savepoints allow both updating your programs and your Flink cluster without losing any state.
Savepoints are manually triggered checkpoints, which take a snapshot of the program and write it out to a state backend. They rely on the regular checkpointing mechanism for this. Savepoints are similar to checkpoints except that they are triggered by the user and don’t automatically expire when newer checkpoints are completed.
Conclusions
Apache Flink is the most suited framework for real-time processing and use cases. Its single engine system is unique which can process both batch and streaming data with different APIs like Dataset and DataStream.
It does not mean Hadoop and Spark are out of the game, the selection of the most suited big data framework always depends and varies from use case to use case. There can be several use cases where a combination of Hadoop and Flink or Spark and Flink might be suited.
Nevertheless, Flink is the best framework for real time processing currently. The growth of Apache Flink has been amazing, and the number of contributors to its community is growing day by day.
Happy Flinking!