eBay’s Network Engineering team operates a large-scale network infrastructure with a presence across the globe. Our mission is to provide a seamless experience connecting buyers and sellers wherever they may be. The network we created to support that goal is comprised of different vendors and designs that have evolved over time. Networks require care and feeding on a regular basis in order to ensure that performance targets are met. How can we make the numerous weekly changes required while minimizing the risk of an impact?
One way in which we accomplish our goal is by making all change management procedures as standard and reproducible as possible. Common tasks such as line card installations, BGP changes, or the turn up of new ports are formalized into Standard Operating Procedures (SOPs). A SOP lays out all of the needed pre-checks, change steps, and post-checks for a successful change to be executed. Our SOPs are put through an engineering review process where we review and hone these steps so that the combined experience of all team members can be brought to bear on the problem.
As we went through this process of creating SOPs for most of our workload, we realized that we were doing many of the same things each time. Examples include things such as backing up the configuration, verifying that the console works, and executing commands that let us verify status before and after a change is executed. All of these steps, taken together, began to sound very much like a broken record to us as we created SOP after SOP.
Project Broken Record (PBR)
We determined that fully automating the creation of SOP-based change requests would be a worthwhile investment of our time. Now that we had the most common tasks well-documented in SOPs, we could actually run through most steps programmatically with some work invested. Because many steps were identical (such as collecting ‘show ip ospf neighbor’) from one type of change to another, bits of code would be reusable. Some challenges, such as how to detect different vendors, code versions, or design standards, would present themselves, but the important part for us was to get started and validate that the concept was workable before expanding it.
Our project outline for automating standard change requests was as follows:
- Preparation and Planning
- Design the System
- Develop Proof of Concept
- Document the System
- Execute Pilot
- Evaluation
Preparation and Planning
We decided to focus on a few common and relatively easier tasks with already defined SOPs. The tasks selected were:
- Costing links in or out for maintenance
- Enabling or disabling ports
- Decommissioning switches
- VLAN add/change
- Code upgrades (various vendors)
A smaller set of tasks like this kept the scope contained to a reasonable size while still allowing the opportunity to bump into a few challenges and solve problems that might be encountered when the project is expanded to cover all of our SOPs.
Dividing the work among several people allowed us to build components in parallel. All coding was stored in a Git repository to facilitate group participation.
Design the System
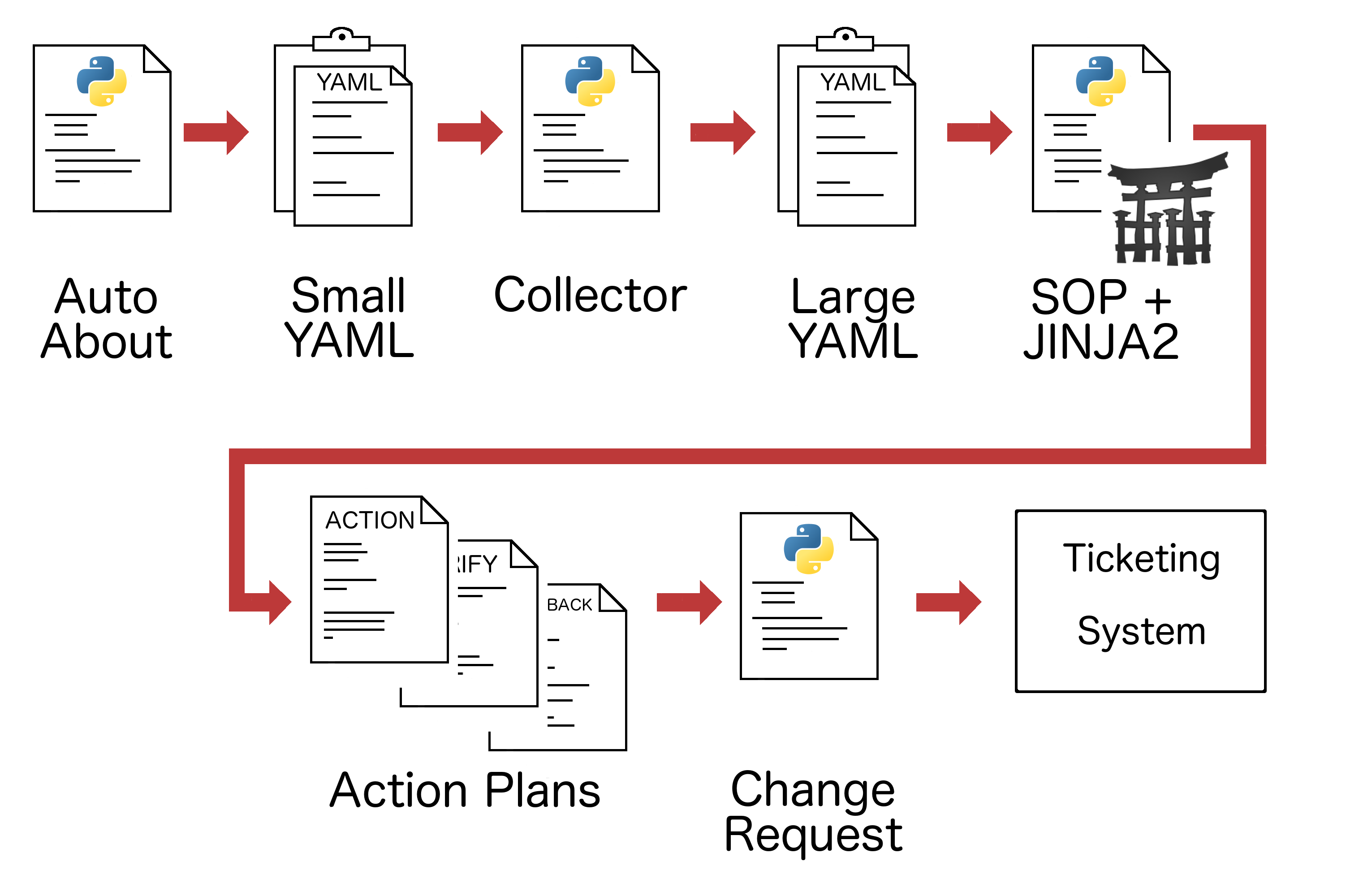
The system is built out of various building blocks. The foundation is a Python script named ‘Auto About.’ This script contains functions that lay out the high-level outline of the pending change request. It defines specific devices, interfaces, or neighbors that are involved in the pending change. It gathers the most basic information, “What is this maintenance about?”, hence the name. A few examples of functions within Auto About are ‘get_routing_instances,’ ‘collect_vlan_info,’ and ‘collect_power_supply_data.’ Feeding Auto About the arguments of a device name and the type of maintenance is all that is required to gather information. The output of Auto About is a small YAML file that contains the information collected at this step.
This small file is fed into the Collector script. This component gathers information from the network devices. Collector is written in Python and is a stateless system. There is no database or long-term storage of information at this point. Collector’s output is a YAML file, much longer than Auto About’s file, with everything we need to know about the change we’re about to execute.
At this point, we have all of the information we need, but reading a YAML is not very friendly for humans. We still track changes in a ticketing system, and we want to be able to review them.
A separate Python script, sop.py, combined with a Jinja2 template that matches the specific type of maintenance desired, takes that long YAML file and generates a few plain text files for us. Each step or check from our original SOP is broken down in the same way within the script, and the output lists each step and sub-step in the proper order. Any device-collected information is added where it is required. Output files created include an Action plan (your “forward” steps), a Verification plan where changes are tested, and a Rollback plan (your “backwards” steps in case you need to undo your changes). These plain text, human-readable files are used to create the Change Request (CR) in our in-house ticketing system. They represent a step-by-step and line-by-line plan to execute the work.
A final Python script called cr.py (‘cr’ indicating change request) handles the task of pushing the information files created by sop.py into Trace, our internally developed ticketing system that tracks changes. This saves engineer time by automating another piece of the CR puzzle for them. cr.py handles aspects of the change ticket process, such as filling in names of the people who submit or check tickets, setting the time and date of the proposed change, and requesting the creation of a new CR ticket.
Develop Proof of Concept
The proof of concept (PoC) involved creating the first versions of the components highlighted above and testing for functionality as well as interoperation of the individual pieces. A number of different people worked on this project, and the correct operation of all of the parts together was tested in the PoC phase. The PoC was a success, and we decided to press forward to a pilot phase.
Document the System
Documentation was created primarily within our Git repository. This was done so that everything a contributor would need was in one place and could be easily updated by anybody working on the project. A simple ‘readme’ file uploaded into the appropriate directory in Git provided a place to put higher level information about how a piece code was supposed to function. This was done in addition to good commenting within each file, of course! Some project tracking items were also hosted on a wiki page, where they were more easily accessed by stakeholders who were not directly involved in the coding aspects.
Execute Pilot
During the pilot phase, we saw a rapid expansion of the PBR program as we started onboarding more use cases and actually using this system in our live change management workflow.
Exposing the output from PBR to the wider group of engineers during our pilot phase was a great way to get additional feedback on how we could collect the right information that would be valuable for the change type being executed. During the pilot period of about six months, numerous small issues with the various CR templates were corrected. Many of these issues were uncovered in our regular change management meetings as we discussed pending CR tickets.
Where it was possible, we aimed to make the CR tickets have the same look and feel. For example, standardizing the sequence numbers for prechecks, change steps, and post checks is one way we found to make the CRs more readable and faster to evaluate at change management meetings. As a result of this feedback loop, our templates and methods quickly evolved to be more comprehensive and polished.
Evaluation
Project Broken Record took us approximately one year to complete from the initial meetings to a working product that had been successfully piloted. We found that all of the pieces of this product require updating and fine tuning from time to time as we strive to execute the perfect change. This type of regular time investment is a good tradeoff for eBay, because we are confident that this system has helped to avoid outages while streamlining the change process.
Our change management meetings were able to be run more efficiently, because we became familiar with the standard layout of change tickets. It was easier to review and approve very standard SOP-based things vs. the previous system of a queue of tickets all written differently by different engineers. Increasing the throughput of the review process directly benefited our internal customers waiting on change work to be completed.
We track all impacts to business availability and analyze what we could have done to avoid impact. One way that we sort this data is by root cause. Causes could be things such as hardware failure, vendor software bugs, change tickets gone wrong, etc. In 2017, impact time due to change tickets was very nearly zero. There were several parallel initiatives that contributed to this, but Project Broken Record was a part of that success story to be sure. Doing the same change the same way each time reduces the chance of unexpected consequences and builds our confidence in our procedures.
Where We’re Headed
We are happy with the progress we have made so far, but there are still a number of things we would like to improve upon.
We want to become more disciplined in our coding by creating development and master branches of our code. Currently, most portions of this system are in a development type state, but are also being used daily. We are also testing systems built up from this that will perform standard maintenances completely automatically by following the SOPs using the large YAML file information.
The larger goal we are pursuing here is minimal human interaction with the production network. Now that we have seen a return on our initial investment, we want to take this to a higher level of engineered solution. A ground-up rewrite of many of the pieces described above is already underway to consolidate functions and improve the way in which we gather information from the network. We are committed to this program, and we expect it to continue to evolve and grow.
Our team exists to help eBay’s business to be successful. As we explore this new automation-focused landscape, we are looking for the best ways to achieve that goal through solid uptime, delivery of projects, and a great user experience for everyone on the platform. The thought processes on our team have shifted from one in which we directly care for an ever-increasing number of network devices directly to one in which we create tools that can do that for us. This new way of approaching operations at eBay is much more scalable and is where we are placing a heavy emphasis as we march toward 2018 and beyond.