This is the first in a series of posts on Cassandra data modeling, implementation, operations, and related practices that guide our Cassandra utilization at eBay. Some of these best practices we’ve learned from public forums, many are new to us, and a few still are arguable and could benefit from further experience.
September 2014 Update: Readers should note that this article describes data modeling techniques based on Cassandra’s Thrift API. Please see https://wiki.apache.org/cassandra/DataModel for CQL API based techniques.
August 2015 Update: Readers can also sign up a free online self-paced course on how to model their data in Apache Cassandra from https://academy.datastax.com/courses/ds220-data-modeling?dxt=blogposting.
In this part, I’ll cover a few basic practices and walk through a detailed example. Even if you don’t know anything about Cassandra, you should be able to follow almost everything.
A few words on Cassandra @ eBay
We’ve been trying out Cassandra for more than a year. Cassandra is now serving a handful of use cases ranging from write-heavy logging and tracking, to mixed workload. One of them serves our “Social Signal” project, which enables like/own/want features on eBay product pages. A few use cases have reached production, while more are in development.
Our Cassandra deployment is not huge, but it’s growing at a healthy pace. In the past couple of months, we’ve deployed dozens of nodes across several small clusters spanning multiple data centers. You may ask, why multiple clusters? We isolate clusters by functional area and criticality. Use cases with similar criticality from the same functional area share the same cluster, but reside in different keyspaces.
RedLaser, Hunch, and other eBay adjacencies are also trying out Cassandra for various purposes. In addition to Cassandra, we also utilize MongoDB and HBase. I won’t discuss these now, but suffice it to say we believe each has its own merit.
I’m sure you have more questions at this point. But I won’t tell you the full story yet. At the upcoming Cassandra summit, I’ll go into detail about each use case, the data model, multi-datacenter deployment, lessons learned, and more.
The focus of this post is Cassandra data modeling best practices that we follow at eBay. So, let’s jump in with a few notes about terminology and representations I’ll be using for each post in this series.
Terms and Conventions
- The terms “Column Name” and “Column Key” are used interchangeably. Similarly, “Super Column Name” and “Super Column Key” are used interchangeably.
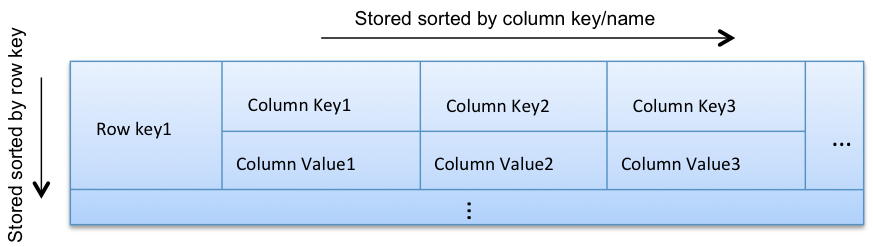
- The following layout represents a row in a Column Family (CF):


- The following layout represents a row in a Super Column Family (SCF):

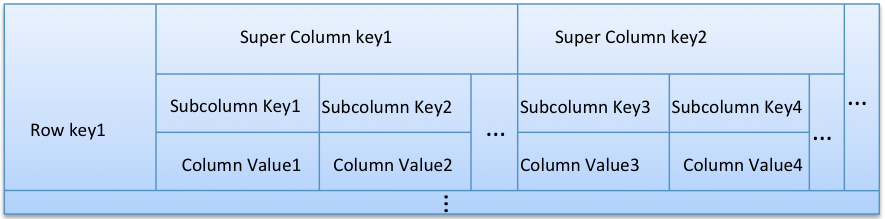
- The following layout represents a row in a Column Family with composite columns. Parts of a composite column are separated by ‘|’. Note that this is just a representation convention; Cassandra’s built-in composite type encodes differently, not using ‘|’. (BTW, this post doesn’t require you to have detailed knowledge of super columns and composite columns.)

With that, let’s start with the first practice!
Don’t think of a relational table
Instead, think of a nested, sorted map data structure.
The following relational model analogy is often used to introduce Cassandra to newcomers:
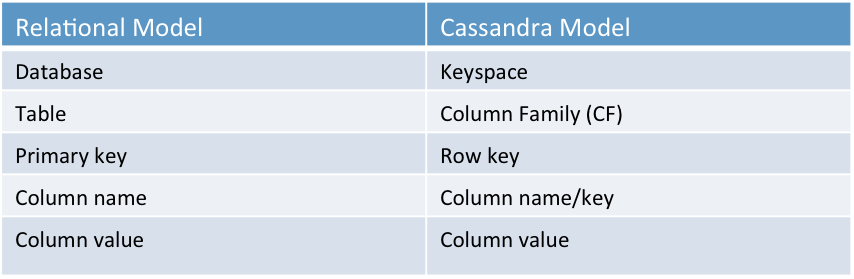
This analogy helps make the transition from the relational to non-relational world. But don’t use this analogy while designing Cassandra column families. Instead, think of the Cassandra column family as a map of a map: an outer map keyed by a row key, and an inner map keyed by a column key. Both maps are sorted.
SortedMap<RowKey, SortedMap<ColumnKey, ColumnValue>>
Why?
A nested sorted map is a more accurate analogy than a relational table, and will help you make the right decisions about your Cassandra data model.
How?
- A map gives efficient key lookup, and the sorted nature gives efficient scans. In Cassandra, we can use row keys and column keys to do efficient lookups and range scans.
- The number of column keys is unbounded. In other words, you can have wide rows.
- A key can itself hold a value. In other words, you can have a valueless column.
Range scan on row keys is possible only when data is partitioned in a cluster using Order Preserving Partitioner (OOP). OOP is almost never used. So, you can think of the outer map as unsorted:
Map<RowKey, SortedMap<ColumnKey, ColumnValue>>
As mentioned earlier, there is something called a “Super Column” in Cassandra. Think of this as a grouping of columns, which turns our two nested maps into three nested maps as follows:
Map<RowKey, SortedMap<SuperColumnKey, SortedMap<ColumnKey, ColumnValue>>>
Notes:
- You need to pass the timestamp with each column value, for Cassandra to use internally for conflict resolution. However, the timestamp can be safely ignored during modeling. Also, do not plan to use timestamps as data in your application. They’re not for you, and they do not define new versions of your data (unlike in HBase).
- The Cassandra community has heavily criticized the implementation of Super Column because of performance concerns and the lack of support for secondary indexes. The same “super column like” functionality (or even better) can be achieved by using composite columns.
Model column families around query patterns
But start your design with entities and relationships, if you can.
- Unlike in relational databases, it’s not easy to tune or introduce new query patterns in Cassandra by simply creating secondary indexes or building complex SQLs (using joins, order by, group by?) because of its high-scale distributed nature. So think about query patterns up front, and design column families accordingly.
- Remember the lesson of the nested sorted map, and think how you can organize data into that map to satisfy your query requirements of fast look-up/ordering/grouping/filtering/aggregation/etc.
However, entities and their relationships still matter (unless the use case is special – perhaps storing logs or other time series data?). What if I gave you query patterns to create a Cassandra model for an e-commerce website, but didn’t tell you anything about the entities and relationships? You might try to figure out entities and relationships, knowingly or unknowingly, from the query patterns or from your prior understanding of the domain (because entities and relationships are how we perceive the real world). It’s important to understand and start with entities and relationships, then continue modeling around query patterns by de-normalizing and duplicating. If this sounds confusing, make sure to go through the detailed example later in this post.
Note: It also helps to identify the most frequent query patterns and isolate the less frequent. Some queries might be executed only a few thousand times, while others a billion times. Also consider which queries are sensitive to latency and which are not. Make sure your model first satisfies the most frequent and critical queries.
De-normalize and duplicate for read performance
But don’t de-normalize if you don’t need to. It’s all about finding the right balance.
In the relational world, the pros of normalization are well understood: less data duplication, fewer data modification anomalies, conceptually cleaner, easier to maintain, and so on. The cons are also understood: that queries might perform slowly if many tables are joined, etc. The same holds true in Cassandra, but the cons are magnified since it’s distributed and of course there are no joins (since it’s high-scale distributed!). So with a fully normalized schema, reads may perform much worse.
This and the previous practice (modeling around query patterns) are so important that I would like to further elaborate by devoting the rest of the post to a detailed example.
Note: The example discussed below is just for demonstration purposes, and does not represent the data model used for Cassandra projects within eBay.
Example: ‘Like’ relationship between User & Item
This example concerns the functionality of an e-commerce system where users can like one or more items. One user can like multiple items and one item can be liked by multiple users, leading to a many-to-many relationship as shown in the relational model below:
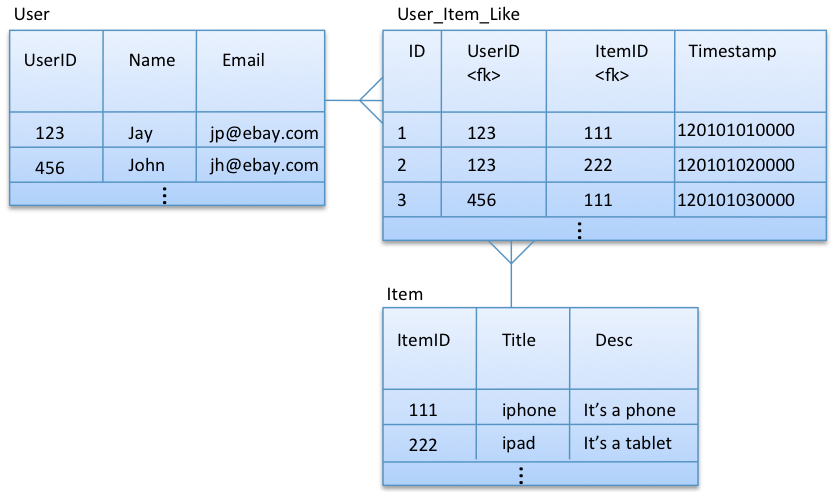
For this example, let’s say we would like to query data as follows:
- Get user by user id
- Get item by item id
- Get all the items that a particular user likes
- Get all the users who like a particular item
Below are some options for modeling the data in Cassandra, in order of the lowest to the highest de-normalization. The best option depends on the query patterns, as you’ll soon see.
Option 1: Exact replica of relational model
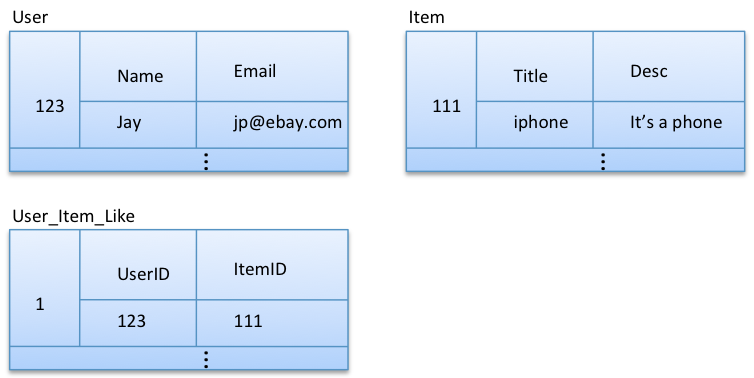
This model supports querying user data by user id and item data by item id. But there is no easy way to query all the items that a particular user likes or all the users who like a particular item.
This is the worst way of modeling for this use case. Basically, User_Item_Like is not modeled correctly here.
Note that the ‘timestamp’ column (storing when the user liked the item) is dropped from User_Item_Like for simplicity. I’ll introduce that column later.
Option 2: Normalized entities with custom indexes
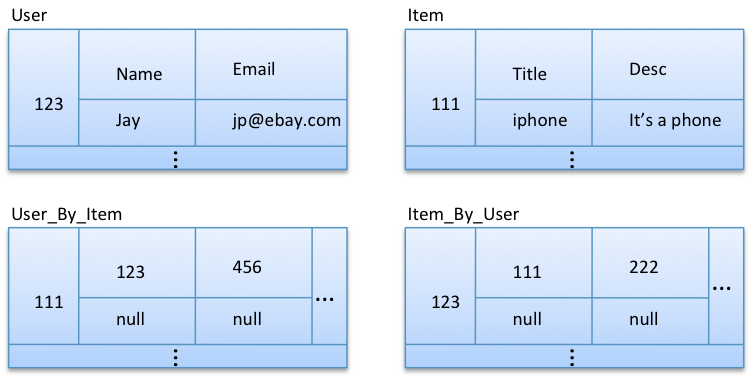
This model has fairly normalized entities, except that user id and item id mapping is stored twice, first by item id and second by user id.
Here, we can easily query all the items that a particular user likes using Item_By_User, and all the users who like a particular item using User_By_Item. We refer to these column families as custom secondary indexes, but they’re just other column families.
Let’s say we always want to get the item title in addition to the item id when we query items liked by a particular user. In the current model, we first need to query Item_By_User to get all the item ids that a given user likes; and then for each item id, we need to query Item to get the title. Similarly, let’s say we always want to get all the usernames in addition to user ids when we query users who like a particular item. With the current model, we first need to query User_By_Item to get the ids for all users who like a given item; and then for each user id, we need to query User to get the username. It’s possible that one item is liked by a couple hundred users, or an active user has liked many items — which will cause many additional queries when we look up usernames who like a given item and vice versa. So, it’s better to optimize by de-normalizing item title in Item_by_User, and username in User_by_Item, as shown in option 3.
Note: Even if you can batch your reads, they will still be slower because Cassandra (Coordinator node, to be specific) has to query each row separately underneath (usually from different nodes). Batch read will help only by avoiding the round trip — which is good, so you should always try to leverage it.
Option 3: Normalized entities with de-normalization into custom indexes
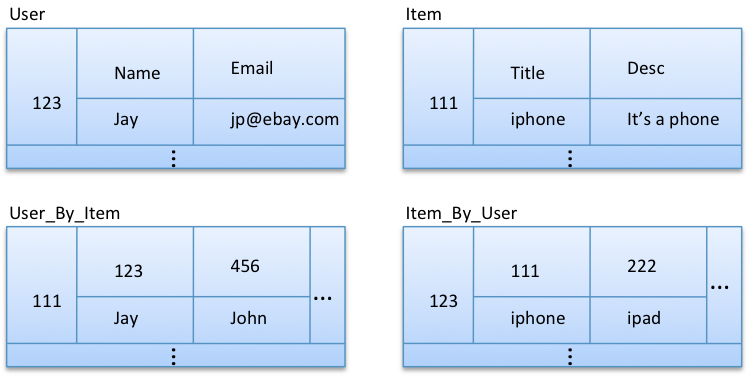
In this model, title and username are de-normalized in User_By_Item and Item_By_User respectively. This allows us to efficiently query all the item titles liked by a given user, and all the user names who like a given item. This is a fair amount of de-normalization for this use case.
What if we want to get all the information (title, desc, price, etc.) about the items liked by a given user? But we need to ask ourselves whether we really need this query, particularly for this use case. We can show all the item titles that a user likes and pull additional information only when the user asks for it (by clicking on a title). So, it’s better not to do extreme de-normalization for this use case. (However, it’s common to show both title and price up front. It’s easy to do; I’ll leave it for you to pursue if you wish.)
Let’s consider the following two query patterns:
- For a given item id, get all of the item data (title, desc, etc.) along with the names of the users who liked that item.
- For a given user id, get all of the user data along with the item titles liked by that user.
These are reasonable queries for item detail and user detail pages in an application. Both will perform well with this model. Both will cause two lookups, one to query item data (or user data) and another to query user names (or item titles). As the user becomes more active (starts liking thousands of items?) or the item becomes hotter (liked by a few million users?), the number of lookups will not grow; it will remain constant at two. That’s not bad, and de-normalization may not yield much benefit like we had when moving from option 2 to option 3. However, let’s see how we can optimize further in option 4.
Option 4: Partially de-normalized entities
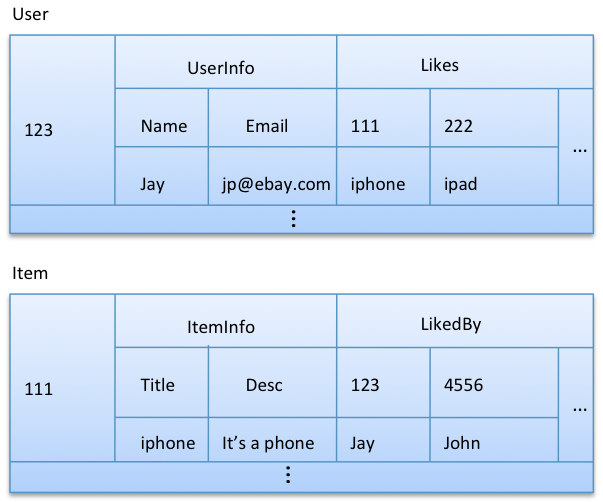
Definitely, option 4 looks messy. In terms of savings, it’s not like what we had in option 3.
If User and Item are highly shared entities (similar to what we have at eBay), I would prefer option 3 over this option.
We’ve used the term “partially de-normalized” here because we’re not de-normalizing all item data into the User entity or all user data into the Item entity. I won’t even consider showing extreme de-normalization (keeping all item data in User and all user data in Item), as you probably agree that it doesn’t make sense for this use case.
Note: I’ve used Super Column here just for demonstration purposes. Almost all the time, you should favor composite columns over Super Column.
The best model
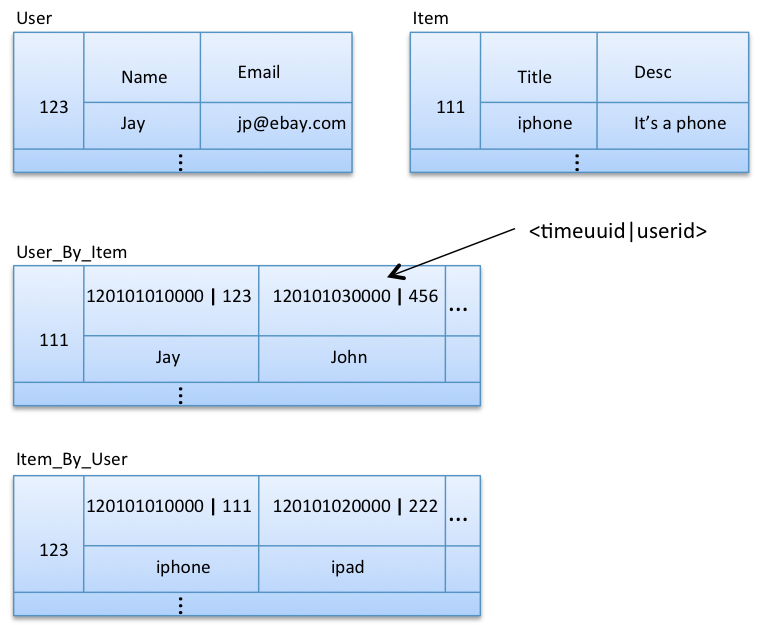
The winner is Option 3, particularly for this example. We’ve left out timestamp, but let’s include it in the final model below as timeuuid(type-1 uuid). Note that timeuuid and userid together form a composite column key in User_By_Item and Item_By_User column families.
Recall that column keys are physically stored sorted. Here our column keys are stored sorted by timeuuid in both User_By_Item and Item_By_User, which makes range queries on time slots very efficient. With this model, we can efficiently query (via range scans) the most recent users who like a given item and the most recent items liked by a given user, without reading all the columns of a row.
Summary
We’ve covered a few fundamental practices and walked through a detailed example to help you get started with Cassandra data model design. Here are the key takeaways:
- Don’t think of a relational table, but think of a nested sorted map data structure while designing Cassandra column families.
- Model column families around query patterns. But start your design with entities and relationships, if you can.
- De-normalize and duplicate for read performance. But don’t de-normalize if you don’t need to.
- Remember that there are many ways to model. The best way depends on your use case and query patterns.
What I’ve not mentioned here are special, but common, use cases such as logging, monitoring, real-time analytics (rollups, counters), or other time series data. However, practices discussed here do apply there. In addition, there are known common techniques or patterns used to model these time series data in Cassandra. At eBay, we also use some of those techniques and would love to share about them in upcoming posts. For more information on modeling time series data, I would recommend reading Advanced time series with Cassandra and Metric collection and storage. Also, if you’re new to Cassandra, make sure to scan through DataStax documentation on Cassandra.
UPDATE: Part 2 about Cassandra is now published.
— Jay Patel, architect@eBay