In the first part, we covered a few fundamental practices and walked through a detailed example to help you get started with Cassandra data model design. You can follow Part 2 without reading Part 1, but I recommend glancing over the terms and conventions I’m using. If you’re new to Cassandra, I urge you to read Part 1.
September 2014 Update: Readers should note that this article describes data modeling techniques based on Cassandra’s Thrift API. Please see https://wiki.apache.org/cassandra/DataModel for CQL API based techniques.
August 2015 Update: Readers can also sign up a free online self-paced course on how to model their data in Apache Cassandra from https://academy.datastax.com/courses/ds220-data-modeling?dxt=blogposting.
Some of the practices listed below might evolve in the future. I’ve provided related JIRA ticket numbers so you can watch any evolution.
With that, let’s get started with some basic practices!
Storing values in column names is perfectly OK
Leaving column values empty (“valueless” columns) is also OK.
It’s a common practice with Cassandra to store a value (actual data) in the column name (a.k.a. column key), and even to leave the column value field empty if there is nothing else to store. One motivation for this practice is that column names are stored physically sorted, but column values are not.
Notes:
- The maximum column key (and row key) size is 64KB. However, don’t store something like ‘item description’ as the column key!
- Don’t use timestamp alone as a column key. You might get colliding timestamps from two or more app servers writing to Cassandra. Prefer timeuuid (type-1 uuid) instead.
- The maximum column value size is 2 GB. But becuase there is no streaming and the whole value is fetched in heap memory when requested, limit the size to only a few MBs. (Large objects are not likely to be supported in the near future – Cassandra-265. However, the Astyanax client library supports large objects by chunking them.)
Leverage wide rows for ordering, grouping, and filtering
But don’t go too wide.
This goes along with the above practice. When actual data is stored in column names, we end up with wide rows.
Benefits of wide rows:
- Since column names are stored physically sorted, wide rows enable ordering of data and hence efficient filtering (range scans). You’ll still be able to efficiently look up an individual column within a wide row, if needed.
- If data is queried together, you can group that data up in a single wide row that can be read back efficiently, as part of a single query. As an example, for tracking or monitoring some time series data, we can group data by hour/date/machines/event types (depending on the requirements) in a single wide row, with each column containing granular data or roll-ups. We can also further group data within a row using super or composite columns as discussed later.
- Wide row column families are heavily used (with composite columns) to build custom indexes in Cassandra.
- As a side benefit, you can de-normalize a one-to-many relationship as a wide row without data duplication. However, I would do this only when data is queried together and you need to optimize read performance.
Example:
Let’s say we want to store some event log data and retrieve that data hourly. As shown in the model below, the row key is the hour of the day, the column name holds the time when the event occurred, and the column value contains payload. Note that the row is wide and the events are ordered by time because column names are stored sorted. Granularity of the wide row (for this example, per hour rather than every few minutes) depends on the use case, traffic, and data size, as discussed next.

But not too wide, as a row is never split across nodes:
It’s hard to say exactly how wide a wide row should be, partly because it’s dependent upon the use case. But here’s some advice:
Traffic: All of the traffic related to one row is handled by only one node/shard (by a single set of replicas, to be more precise). Rows that are too “fat” could cause hot spots in the cluster – usually when the number of rows is smaller than the size of the cluster (hope not!), or when wide rows are mixed with skinny ones, or some rows become hotter than others. However, cluster load balancing ultimately depends on the row key selection; conversely, the row key also defines how wide a row will be. So load balancing is something to keep in mind during design.
Size: As a row is not split across nodes, data for a single row must fit on disk within a single node in the cluster. However, rows can be large enough that they don’t have to fit in memory entirely. Cassandra allows 2 billion columns per row. At eBay, we’ve not done any “wide row” benchmarking, but we model data such that we never hit more than a few million columns or a few megabytes in one row (we change the row key granularity, or we split into multiple rows). If you’re interested, Cassandra Query Plans by Aaron Morton shows some performance concerns with wide rows (but note that the results can change in new releases).
However, these caveats don’t mean you should not use wide rows; just don’t go extra wide.
Note: Cassandra-4176 might add composite types for row key in CQL as a way to split a wide row into multiple rows. However, a single (physical) row is never split across nodes (and won’t be split across nodes in the future), and is always handled by a single set of replicas. You might also want to track Cassandra-3929, which would add row size limits for keeping the most recent n columns in a wide row.
Choose the proper row key – it’s your “shard key”
Otherwise, you’ll end up with hot spots, even with RandomPartitioner.
Let’s consider again the above example of storing time series event logs and retrieving them hourly. We picked the hour of the day as the row key to keep one hour of data together in a row. But there is an issue: All of the writes will go only to the node holding the row for the current hour, causing a hot spot in the cluster. Reducing granularity from hour to minutes won’t help much, because only one node will be responsible for handling writes for whatever duration you pick. As time moves, the hot spot might also move but it won’t go away!
Bad row key: “ddmmyyhh”
One way to alleviate this problem is to add something else to the row key – an event type, machine id, or similar value that’s appropriate to your use case.
Better row key: “ddmmyyhh|eventtype”
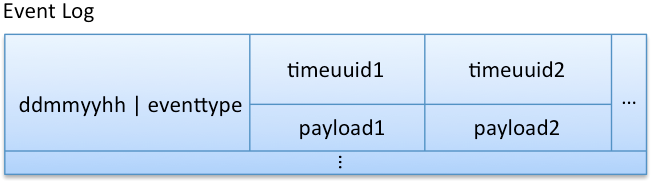
Note that now we don’t have global time ordering of events, across all event types, in the column family. However, this may be OK if the data is viewed (grouped) by event type later. If the use case also demands retrieving all of the events (irrespective of type) in time sequence, we need to do a multi-get for all event types for a given time period, and honor the time order when merging the data in the application.
If you can’t add anything to the row key or if you absolutely need ‘time period’ as a row key, another option is to shard a row into multiple (physical) rows by manually splitting row keys: “ddmmyyhh | 1”, “ddmmyyhh | 2”,… “ddmmyyhh | n”, where n is the number of nodes in the cluster. For an hour window, each shard will now evenly handle the writes; you need to round-robin among them. But reading data for an hour will require multi-gets from all of the splits (from the multiple physical nodes) and merging them in the application. (An assumption here is that RandomPartitioner is used, and therefore that range scans on row keys can’t be done.)
Keep read-heavy data separate from write-heavy data
This way, you can benefit from Cassandra’s off-heap row cache.
Irrespective of caching and even outside the NoSQL world, it’s always a good practice to keep read-heavy and write-heavy data separate because they scale differently.
Notes:
- A row cache is useful for skinny rows, but harmful for wide rows today because it pulls the entire row into memory. Cassandra-1956 and Cassandra-2864 might change this in future releases. However, the practice of keeping read-heavy data separate from write-heavy data will still stand.
- Even if you have lots of data (more than available memory) in a column family but you also have particularly “hot” rows, enabling a row cache might be useful.
Make sure column key and row key are unique
Otherwise, data could get accidentally overwritten.
- In Cassandra (a distributed database!), there is no unique constraint enforcement for row key or column key.
- Also, there is no separate update operation (no in-place updates!). It’s always an upsert (mutate) in Cassandra. If you accidentally insert data with an existing row key and column key, the previous column value will be silently overwritten without any error (the change won’t be versioned; the data will be gone).
Use the proper comparator and validator
Don’t just use the default BytesType comparator and validator unless you really need to.
In Cassandra, the data type for a column value (or row key) is called a Validator. The data type for a column name is called a Comparator. Although Cassandra does not require you to define both, you must at least specify the comparator unless your column family is static (that is, you’re not storing actual data as part of the column name), or unless you really don’t care about the sort order.
- An improper comparator will sort column names inappropriately on the disk. It will be difficult (or impossible) to do range scans on column names later.
- Once defined, you can’t change a comparator without rewriting all data. However, the validator can be changed later.
See comparators and validators in the Cassandra documentation for the supported data types.
Keep the column name short
Because it’s stored repeatedly.
This practice doesn’t apply if you use the column name to store actual data. Otherwise, keep the column name short, since it’s repeatedly stored with each column value. Memory and storage overhead can be significant when the size of the column value is not much larger than the size of the column name – or worse, when it’s smaller.
For example, favor ‘fname’ over ‘firstname’, and ‘lname’ over ‘lastname’.
Note: Cassandra-4175 might make this practice obsolete in the future.
Design the data model such that operations are idempotent
Or, make sure that your use case can live with inaccuracies or that inaccuracies can be corrected eventually.
In an eventually consistent and fully distributed system like Cassandra, idempotent operations can help – a lot. Idempotent operations allow partial failures in the system, as the operations can be retried safely without changing the final state of the system. In addition, idempotency can sometimes alleviate the need for strong consistency and allow you to work with eventual consistency without causing data duplication or other anomalies. Let’s see how these principles apply in Cassandra. I’ll discuss partial failures only, and leave out alleviating the need for strong consistency until an upcoming post, as it is very much dependent on the use case.
Because of Cassandra’s fully distributed (and multi-master) nature, write failure does not guarantee that data is not written, unlike the behavior of relational databases. In other words, even if the client receives a failure for a write operation, data might be written to one of the replicas, which will eventually get propagated to all replicas. No rollback or cleanup is performed on partially written data. Thus, a perceived write failure can result in a successful write eventually. So, retries on write failure can yield unexpected results if your model isn’t update idempotent.
Notes:
- “Update idempotent” here means a model where operations are idempotent. An operation is called idempotent if it can be applied one time or multiple times with the same result.
- In most cases, idempotency won’t be a concern, as writes into regular column families are always update idempotent. The exception is with the Counter column family, as shown in the example below. However, sometimes your use case can model data such that write operations are not update idempotent from the use case perspective. For instance, in part 1, User_by_Item and Item_by_User in the final model are not update idempotent if the use case operation ‘user likes item’ gets executed multiple times, as the timestamp might differ for each like. However, note that a specific instance of the use case operation ‘user likes item’ is still idempotent, and so can be retried multiple times in case of failures. As this is more use-case specific, I might elaborate more in future posts.
- Even with a consistency level ONE, write failure does not guarantee data is not written; the data still could get propagated to all replicas eventually.
Example
Suppose that we want to count the number of users who like a particular item. One way is to use the Counter column family supported by Cassandra to keep count of users per item. Since the counter increment (or decrement) is not update idempotent, retry on failure could yield an over-count if the previous increment was successful on at least one node. One way to make the model update idempotent is to maintain a list of user ids instead of incrementing a count, as shown below. Whenever a user likes an item, we write that user’s id against the item; if the write fails, we can safely retry. To determine the count of all users who like an item, we read all user ids for the item and count manually.
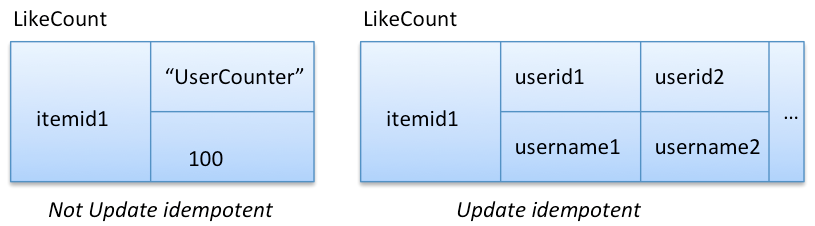
In the above update idempotent model, getting the counter value requires reading all user ids, which will not perform well (there could be millions). If reads are heavy on the counter and you can live with an approximate count, the counter column will be efficient for this use case. If needed, the counter value can be corrected periodically by counting the user ids from the update idempotent column family.
Note: Cassandra-2495 might add a proper retry mechanism for counters in the case of a failed request. However, in general, this practice will continue to hold true. So make sure to always litmus-test your model for update idempotency.
Model data around transactions, if needed
But this might not always be possible, depending on the use case.
Cassandra has no multi-row, cluster-wide transaction or rollback mechanism; instead, it offers row-level atomicity. In other words, a single mutation operation of columns for a given row key is atomic. So if you need transactional behavior, try to model your data such that you would only ever need to update a single row at once. However, depending on the use case, this is not always doable. Also, if your system needs ACID transactions, you might re-think your database choice.
Note: Cassandra-4285 might add an atomic, eventually consistent batch operation.
Decide on the proper TTL up front, if you can
Because it’s hard to change TTL for existing data.
In Cassandra, TTL (time to live) is not defined or set at the column family level. It’s set per column value, and once set it’s hard to change; or, if not set, it’s hard to set for existing data. The only way to change the TTL for existing data is to read and re-insert all the data with a new TTL value. So think about your purging requirements, and if possible set the proper TTL for your data upfront.
Note: Cassandra-3974 might introduce TTL for the column family, separate from column TTL.
Don’t use the Counter column family to generate surrogate keys
Because it’s not intended for this purpose.
The Counter column family holds distributed counters meant (of course) for distributed counting. Don’t try to use this CF to generate sequence numbers for surrogate keys, like Oracle sequences or MySQL auto-increment columns. You will receive duplicate sequence numbers! Most of the time you really don’t need globally sequential numbers. Prefer timeuuid (type-1 uuid) as surrogate keys. If you truly need a globally sequential number generator, there are a few possible mechanisms; but all will require centralized coordination, and thus can impact the overall system’s scalability and availability.
Favor composite columns over super columns
Otherwise, you might hit performance bottlenecks with super columns.
A super column in Cassandra can be used to group column keys, or to model a two-layer hierarchy. However, super columns have the following implementation issues and are therefore becoming less favorable.
Issues:
- Sub-columns of a super column are not indexed. Reading one sub-column de-serializes all sub-columns.
- Built-in secondary indexing does not work with sub-columns.
- Super columns cannot encode more than two layers of hierarchy.
Similar (even better) functionality can be achieved by the use of the Composite column. It’s a regular column with sub-columns encoded in it. Hence, all of the benefits of regular columns, such as sorting and range scans, are available; and you can encode more than two layers of hierarchy.
Note: Cassandra-3237 might change the underlying super column implementation to use composite columns. However, composite columns will still remain preferred over super columns.
The order of sub-columns in composite columns matters
Because order defines grouping.
For example, a composite column key like <state|city> will be stored ordered first by state and then by city, rather than first by city and then by state. In other words, all the cities within a state are located (grouped) on disk together.
Favor built-in composite types over manual construction
Because manual construction doesn’t always work.
Avoid manually constructing the composite column keys using string concatenation (with separators like “:” or “|”). Instead, use the built-in composite types (and comparators) supported by Cassandra 0.8.1 and above.
Why?
- Manual construction won’t work if sub-columns are of different data types. For example, the composite key <state|zip|timeuuid> will not be sorted in a type-aware fashion (state as string, zip code as integer, and timeuuid as time).
- You can’t reverse the sort order on components in the type – for instance, with the state ascending and the zip code descending in the above key.
Note: Cassandra built-in composite types come in two flavors:
- Static composite type: Data types for each part of a composite column are predefined per column family. All the column names/keys within a column family must be of that composite type.
- Dynamic composite type: This type allows mixing column names with different composite types in a column family or even in one row.
Find more information about composite types at Introduction to composite columns.
Favor static composite types over dynamic, whenever possible
Because dynamic composites are too dynamic.
If all column keys in a column family are of the same composite type, always use static composite types. Dynamic composite types were originally created to keep multiple custom indexes in one column family. If possible, don’t mix different composite types in one row using the dynamic composite type unless absolutely required. Cassandra-3625 has fixed some serious issues with dynamic composites.
Note: CQL 3 supports static composite types for column names via clustered (wide) rows. Find more information about how CQL 3 handles wide rows at DataStax docs.
Enough for now. I would appreciate your inputs to further enhance these modeling best practices, which guide our Cassandra utilization today.
— Jay Patel, architect@eBay.