Co-Authors: Chaitali Gupta and Edward Zhang
Update: Eagle was accepted as an Apache Incubator project on October 26, 2015.
Today’s successful organizations are data driven. At eBay we have thousands of engineers, analysts, and data scientists who crunch petabytes of data everyday to provide a great experience for our users. We execute at massive scale using data to connect our millions of users in global commerce.
In recent years, Hadoop has become one of the most popular choices for Big Data analytics. eBay uses Hadoop to generate value from data for improving search experience, identifying and optimizing relevant advertisements, enriching our product catalogs, and performing click stream analysis to understand how eBay customers leverage our marketplace. Accordingly, we have a wide variety of workloads that include Hive, MapReduce, Spark, HBase, and hundreds of petabytes of data.
In this era of Big Data, security is ever more critical. At eBay, Hadoop data is secured. Our security approach follows these four pillars: access control, perimeter security, data classification, and data activity monitoring. Early in our journey, we recognized there was no product or solution that adequately supported our data activity monitoring needs given the scale and variety of use cases at eBay. To address this gap, eBay built Eagle.

Eagle is an open-source Data Activity Monitoring solution for Hadoop to instantly detect access to sensitive data or malicious activities, and to take appropriate actions.
We believe Eagle is a core component of Hadoop data security, and we want to share this capability with the open-source community. We will be open sourcing Eagle through the Apache Software Foundation. We are looking forward to working with the open-source development community.
Here are some of the Eagle data activity monitoring use cases:
- Anomalous data access detection based on user behavior
- Discovery of intrusions and security breaches
- Discovery and prevention of sensitive data loss
- Policy-based detection and alerting
Key Eagle qualities include the following:
- Real time: We understand the importance of timing and acting fast in case of a security breach. So we designed Eagle to make sure that the alerts are generated in a sub-second and that the anomalous activity is stopped if it’s a real threat.
- Scalability: At eBay, Eagle is deployed on multiple large Hadoop clusters with petabytes of data and 800 million access events every day.
- Ease of use: Usability is one of our core design principles. We have made it easy to get started. It takes only a few minutes to get up and running with Eagle sandbox, and examples and policies can be added with a few clicks.
- User profiles: Eagle provides capabilities to create user profiles based on user behavior in Hadoop. We have out-of-the box machine-learning algorithms that you can leverage to build models with different HDFS features and get alerted on anomalies.
- Open source: Eagle is built ground up using open-source standards and various products from the Big Data space. We decided to open-source Eagle to help the community, and we are looking forward to your feedback, collaboration, and support.
- Extensibility: Eagle is designed with extensibility in mind. You can easily integrate Eagle with existing data classification and monitoring tools.
Eagle at a glance
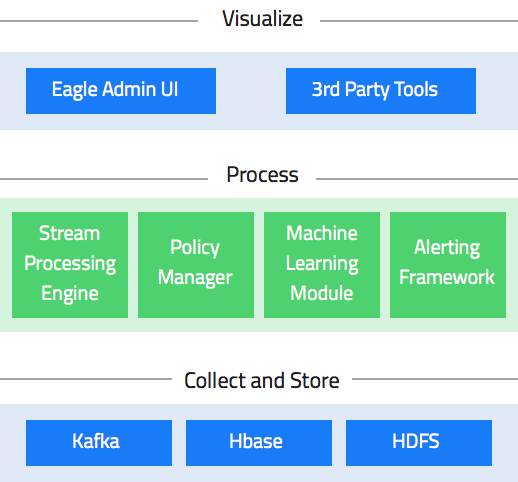
1.a Eagle Architecture
1. Data collection
Eagle provides a programming API for extending Eagle to integrate any data source into the Eagle policy evaluation framework. For example, Eagle HDFS audit monitoring collects data from Kafka, which is populated from the NameNode log4j appender or from the logstash agent. Eagle Hive monitoring collects Hive query logs from running jobs through the YARN API, which is designed to be scalable and fault-tolerant.
2. Data processing
2.1 Stream processing API:Eagle provides a stream processing API which is an abstraction on Apache Storm, but is also extensible to other streaming engines. This abstraction allows developers to easily assemble data transformation, filtering, external data join, etc. without being physically bound to a specific streaming platform. The Eagle streaming API also allows developers to easily integrate business logic with the Eagle policy engine. Internally, the Eagle framework compiles business logic execution DAG into program primitives of the underlying stream infrastructure—for example, Apache Storm.
Here is an example of events and alerts processing in Eagle:
StormExecutionEnvironment env = ExecutionEnvironmentFactory.getStorm(config); // storm
StreamProducer producer = env.newSource(new KafkaSourcedSpoutProvider().getSpout(config)).renameOutputFields(1) // declare kafka source
.flatMap(new AuditLogTransformer()) //transform event
.groupBy(Arrays.asList(0)) //group by 1st field
.flatMap(new UserProfileAggregatorExecutor()); //aggregate one-hour data by user
.alertWithConsumer(“userActivity“,”userProfileExecutor“) // ML policy evaluate
env.execute(); // execute stream processing and alert2.2 Alerting framework: The Eagle alerting framework includes a stream metadata API, a policy engine provider API for extensibility, and a policy partitioner interface for scalability.
The stream metadata API allows developers to declare the event schema including what attributes constitute an event, what each attribute’s type is, and how to dynamically resolve attribute values at runtime when the user configures a policy.
The policy engine provider API allows developers to plug in a new policy engine easily. The WSO2 Siddhi CEP engine is the policy engine that Eagle supports as a first-class citizen. A machine-learning algorithm is also wrapped into the framework as one type of policy engine.
Eagle’s extensible interface allows you to plug in different policy engines:
public interface PolicyEvaluatorServiceProvider {
public String getPolicyType(); // literal string to identify one type of policy
public Class getPolicyEvaluator(); // get policy evaluator implementation
public List getBindingModules(); // policy text with json format to object mapping
}
public interface PolicyEvaluator {
public void evaluate(ValuesArray input) throws Exception; // evaluate input event
public void onPolicyUpdate(AlertDefinitionAPIEntity newAlertDef);// policy update
public void onPolicyDelete(); // invoked when policy is deleted
}
The policy partitioner interface allows policies to be executed on different physical nodes in parallel. It also allows you to define your own policy partitioner class. These capabilities enable policy and event evaluation in a fully distributed fashion.
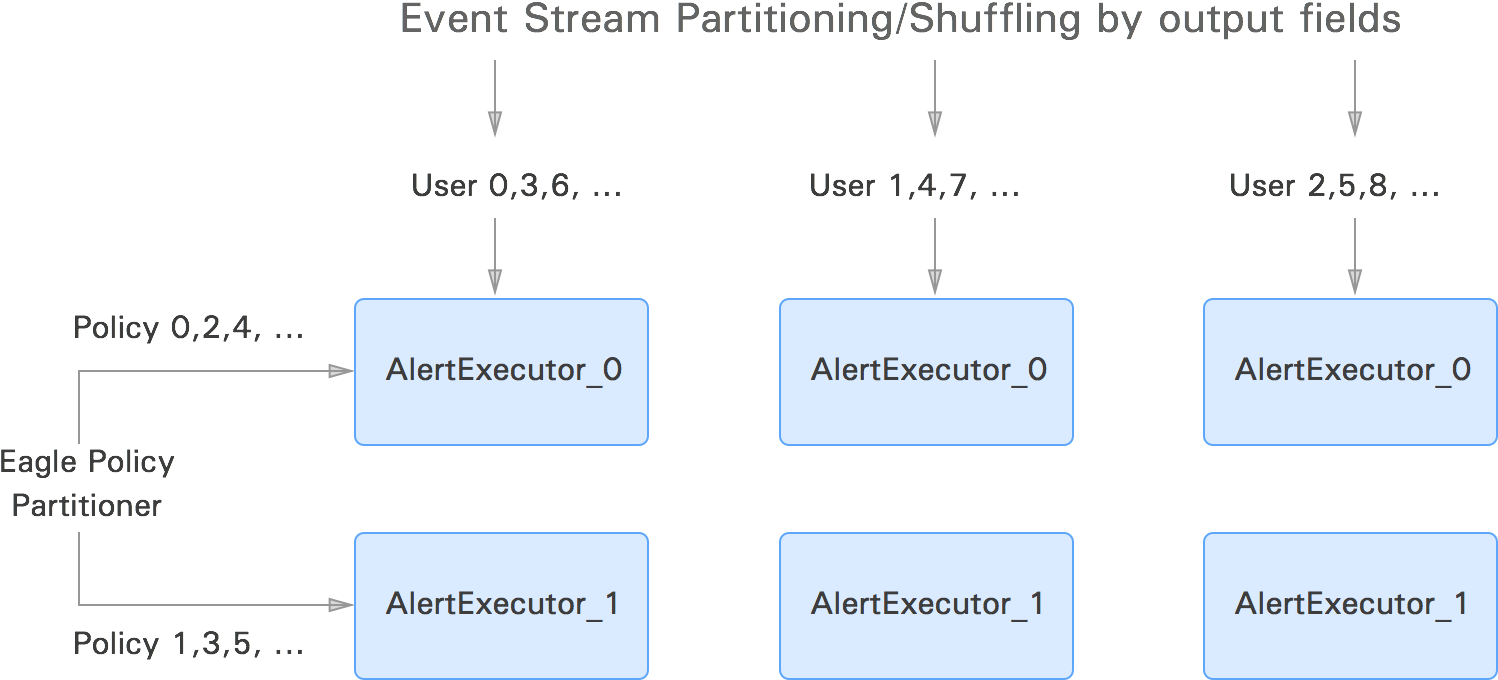
1.b Scalable Eagle policy execution framework
Scalability: Eagle supports policy partitioning to support a large number of policies.
public interface PolicyPartitioner extends Serializable {
// method to distribute policies
int partition(int numTotalPartitions, String policyType, String policyId);
}2.3 Machine-learning module: Eagle provides capabilities to define user activity patterns or user profiles for Hadoop users based on the user behavior in the platform. The idea is to provide anomaly detection capability without setting hard thresholds in the system. The user profiles generated by our system are modeled using machine-learning algorithms and used for detection of anomalous user activities, where users’ activity pattern differs from their pattern history. Currently Eagle uses two algorithms for anomaly detection: Eigen-Value Decomposition and Density Estimation. The algorithms read data from HDFS audit logs, slice and dice data, and generate models for each user in the system. Once models are generated, Eagle uses the Storm framework for near-real-time anomaly detection to determine if current user activities are suspicious or not with respect to their model. The block diagram below shows the current pipeline for user profile training and online detection.
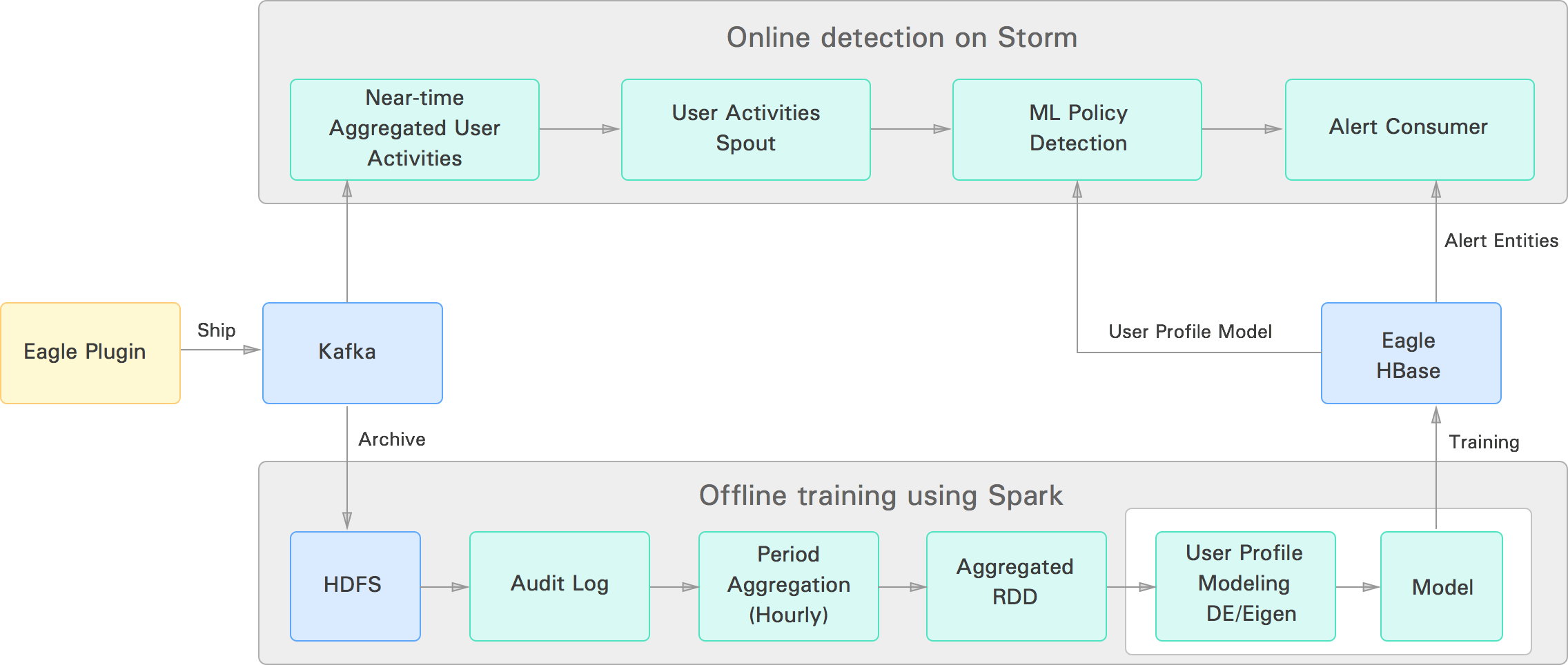
1.c User profile offline training & anomaly detection architecture
Eagle online anomaly detection uses the Eagle policy framework, and the user profile is defined as one of the policies in the system. The user profile policy is evaluated by a machine-learning evaluator extended from the Eagle policy evaluator. Policy definition includes the features that are needed for anomaly detection (same as the ones used for training purposes).
A scheduler runs a Spark-based offline training program (to generate user profiles or models) at a configurable time interval; currently, the training program generates new models once every month.
The following are some details on the algorithms.
2.3.1 Density Estimation—In this algorithm, the idea is to evaluate, for each user, a probability density function from the observed training data sample. We mean-normalize a training dataset for each feature. Normalization allows datasets to be on the same scale. In our probability density estimation, we use a Gaussian distribution function as the method for computing probability density. Features are conditionally independent of one another; therefore, the final Gaussian probability density can be computed by factorizing each feature’s probability density. During the online detection phase, we compute the probability of a user’s activity. If the probability of the user performing the activity is below threshold (determined from the training program, using a method called Mathews Correlation Coefficient), we signal anomaly alerts.
1.d Showing user behavior histogram on one dimension
2.3.2 Eigen-Value Decomposition—Our goal in user profile generation is to find interesting behavioral patterns for users. One way to achieve that goal is to consider a combination of features and see how each one influences the others. When the data volume is large, which is generally the case for us, abnormal patterns among features may go unnoticed due to the huge number of normal patterns. As normal behavioral patterns can lie within very low-dimensional subspace, we can potentially reduce the dimension of the dataset to better understand the user behavior pattern. This method also reduces noise, if any, in the training dataset. Based on the amount of variance of the data we maintain for a user, which is usually 95% for our case, we seek to find the number of principal components k that represents 95% variance. We consider first k principal components as normal subspace for the user. The remaining (n-k) principal components are considered as abnormal subspace.
During online anomaly detection, if the user behavior lies near normal subspace, we consider the behavior to be normal. On the other hand, if the user behavior lies near the abnormal subspace, we raise an alarm as we believe usual user behavior should generally fall within normal subspace. We use the Euclidian distance method to compute whether a user’s current activity is near normal or abnormal subspace.

1.e Showing important user behavior components
3. Eagle services
3.1 Policy Manager: Eagle Policy Manager provides a UI and Restful API for users to define policies. The Eagle user interface makes it easy to manage policies with a few clicks, mark or import sensitivity metadata, perform HDFS or Hive resource browsing, access alert dashboards, etc.
Here is a single-event evaluation policy (one user accessing a sensitive column in Hive):
from hiveAccessStream[sensitivityType=='PHONE_NUM'] select * insert into outputStream;
Here is a window-based policy (one user accessing /tmp/private 5 times or more within 10 minutes):
hdfsAuditLogEventStream[(src == '/tmp/private')]#window.externalTime(timestamp,10 min) select user, count(timestamp) as aggValue group by user having aggValue >= 5 insert into outputStream;
3.2 Query Service: Eagle provides a SQL-like service API to support comprehensive computation for huge sets of data—comprehensive filtering, aggregation, histogram, sorting, top, arithmetical expression, pagination, etc. Although Eagle supports HBase for data storage as a first-class citizen, a relational database is supported as well. For HBase storage, the Eagle query framework compiles a user-provided SQL-like query into HBase native filter objects, and then executes it through the HBase coprocessor on the fly.
query=AlertDefinitionService[@dataSource="hiveQueryLog"]{@policyDef}&pageSize=100000Eagle at eBay
Eagle data activity monitoring is currently being used for monitoring the data access activities in a 2500-node Hadoop cluster, with plans to extend it to other Hadoop clusters covering 10,000 nodes by the end of this year. We started with a basic set of policies on HDFS/Hive data and will be ramping up more policies by the end of this year. Our policies range from access patterns, commonly accessed data sets, predefined queries, Hive tables, columns, and HBase tables, through to policies based on user profiles generated by ML models. We have a wide range of policies to stop data loss, data copying to unsecured location, sensitive data access from unauthorized zones, etc. The flexibility of creating policies in Eagle allows us to expand further and add more complex policies.
What’s next
In addition to data activity monitoring, at eBay the Eagle framework is used extensively to monitor the health of nodes, Hadoop apps, core services, and the entire Hadoop cluster. We have also built in a lot of automation around remediation of nodes, which helped us reduce our manual workload to a large extent.
Below are some of the features we are currently working on and will be releasing in the next version:
- Machine-learning models for Hive and HBase data access events
- Extensible API for integration with external tools for reporting and data classification
- New module for Hadoop cluster monitoring in the next version of Eagle
- HBase access monitoring
- Hadoop job performance monitoring
- Hadoop node monitoring
Please visit https://github.com/eBay/Eagle for more information.