Defining an Elasticsearch cluster lifecycle
eBay’s Pronto, our implementation of the “Elasticsearch as service” (ES-AAS) platform, provides fully managed Elasticsearch clusters for various search use cases. Our ES-AAS platform is hosted in a private internal cloud environment based on OpenStack. The platform currently manages around 35+ clusters and supports multiple data center deployments. This blog provides guidelines on all the different pieces for creating a cluster lifecycle to allow streamlined management of Elasticsearch clusters. All Elasticsearch clusters deployed within the eBay infrastructure follow our defined Elasticsearch lifecycle depicted in the figure below.

Cluster preparation
This lifecycle stage begins when a new use case is being onboarded onto our ES-AAS platform.
On-boarding information
Customers’ requirements are captured onto an onboarding template that contains information such as document size, retention policy, and read/write throughput requirement. Based on the inputs provided by the customer, infrastructure sizing is performed. The sizing uses historic learnings from our benchmarking exercises. On-boarding information has helped us in cluster planning and defining SLA for customer commitments.
We collect the following information from customers before any use case is onboarded:
- Use case details: Consists of queries relating to use case description and significance.
- Sizing Information: Captures the number of documents, their average document size, and year-on-year growth estimation.
- Data read/write information: Consists of expected indexing/search rate, mode of ingestion (batch mode or individual documents), data freshness, average number of users, and specific search queries containing any aggregation, pagination, or sorting operations.
- Data source/retention: Original data source information (such as Oracle, MySQL, etc.) is captured on an onboarding template. If the indices are time-based, then an index purge strategy is logged. Typically, we do not use Elasticsearch as the source of data for critical applications.
Benchmarking strategy
Before undertaking any benchmarking exercise, it’s really important to understand the underlying infrastructure that hosts your VMs. This is especially true in a cloud-based environment where such information is usually abstracted from end users. Be aware of different potential noisy-neighbors issues, especially on a multi-tenant-based infrastructure.
Like most folks, we have also performed extensive benchmarking exercise on existing hardware infrastructure and image flavors. Data stored in Elasticsearch clusters are specific to customer use cases. It is near to impossible to perform benchmarking runs on all data schemas used by different customers. Therefore, we made assumptions before embarking on any benchmarking exercise, and the following assumptions were key.
- Clients will use a REST path for any data access on our provisioned Elasticsearch clusters. (No transport client)
- To start with, we kept a mapping of 1GB RAM to 32GB disk space ratio. (This was later refined as we learnt from benchmarking)
- Indexing numbers were carefully profiled for different numbers of replicas (1, 2, and 3 replicas).
- Search benchmarking was done always on
GetByIdqueries (as search queries are custom and profiling different custom search queries was not viable). - We used fixed-size 1KB, 2KB, 5KB, and 10 KB documents
Working from these assumptions, we derived at a maximum shard size for performance (around 22GB), right payload size for _bulk requests (~5MB), etc. We used our own custom JMeter scripts to perform benchmarking. Recently Elasticsearch has developed and open-sourced the Rally benchmarking tool, which can be used as well. Additionally, based on our benchmarking learnings, we created a capacity-estimation calculator tool that can take in customer requirement inputs and calculate the infrastructure requirement for a use case. We avoided a lot of conversation with our customers on infrastructure cost by sharing this tool directly with end users.
VM cache pool
Our ES clusters are deployed by leveraging an intelligent warm-cache layer. The warm-cache layer consists of ready-to-use VM nodes that are prepared over a period of time based on some predefined rules. This ensures that VMs are distributed across different underlying hardware uniformly. This layer has allowed us to quickly spawn large clusters within seconds. Additionally, our remediation engine leverages this layer to flex up nodes on existing clusters without errors or any manual intervention. More details on our cache pool are available in another eBay tech blog at Ready-to-use Virtual-machine Pool Store via warm-cache
Cluster deployment
Cluster deployment is fully automated via a Puppet/Foreman infrastructure. We will not talk in detail about how Elasticsearch Puppet module was leveraged for provisioning Elasticsearch clusters. This is well documented at Elasticsearch puppet module. Along with every release of Elasticsearch, a corresponding version of the Puppet module is generally made publically available. We have made minor modifications to these Puppet scripts to suit eBay-specific needs. Different configuration settings for Elasticsearch are customized based on our benchmarking learnings. As a general guideline, we do not set the JVM heap memory size to more than 28 GB (because doing so leads to long garbage collection cycles), and we always disable in-memory swapping for the Elasticsearch JVM process. Independent clusters are deployed across data centers, and load balancing VIPs (Virtual IP addresses) are provisioned for data access.
Typically, with each cluster provisioned we give out two VIPs, one for data read operations and another one for write operations. Read VIPs are always created over client nodes (or coordinating nodes), while write VIPs are configured over data nodes. We have observed improved throughput from our clusters with such a configuration.
Deployment diagram

We use a lot of open source on our platform such as OpenStack, MongoDB, href="https://airflow.incubator.apache.org/">Airflow, Grafana, InfluxDB (open version), openTSDB, etc. Our internal services, such as cluster provisioning, cluster management, and customer management services, allow REST API-driven management for deployment and configuration. They also help in tracking clusters as assets against different customers. Our cluster provisioning service relies heavily on OpenStack. For example, we use NOVA for managing compute resources (nodes), Neutron APIs for load balancer provisioning, and Keystone for internal authentication and authorization of our APIs.
We do not use federated or cross-region deployments for an Elasticsearch cluster. Network latency limits us from having such a deployment strategy. Instead, we host independent clusters for use cases across multiple regions. Clients will have to perform dual writes when clusters are deployed in multiple regions. We also do not use Tribe nodes.
Cluster onboarding
We create cluster topology during customer onboarding. This helps to track resources and cost associated with cluster infrastructure. The metadata stored as part of a cluster topology maintains region deployment information, SLA agreements, cluster owner information, etc. We use eBay’s internal configuration management system (CMS) to track cluster information in form of a directed graph. There are external tools that hook onto this topology. Such external integrations allow easy monitoring of our clusters from centralized eBay-specific systems.
Cluster topology example
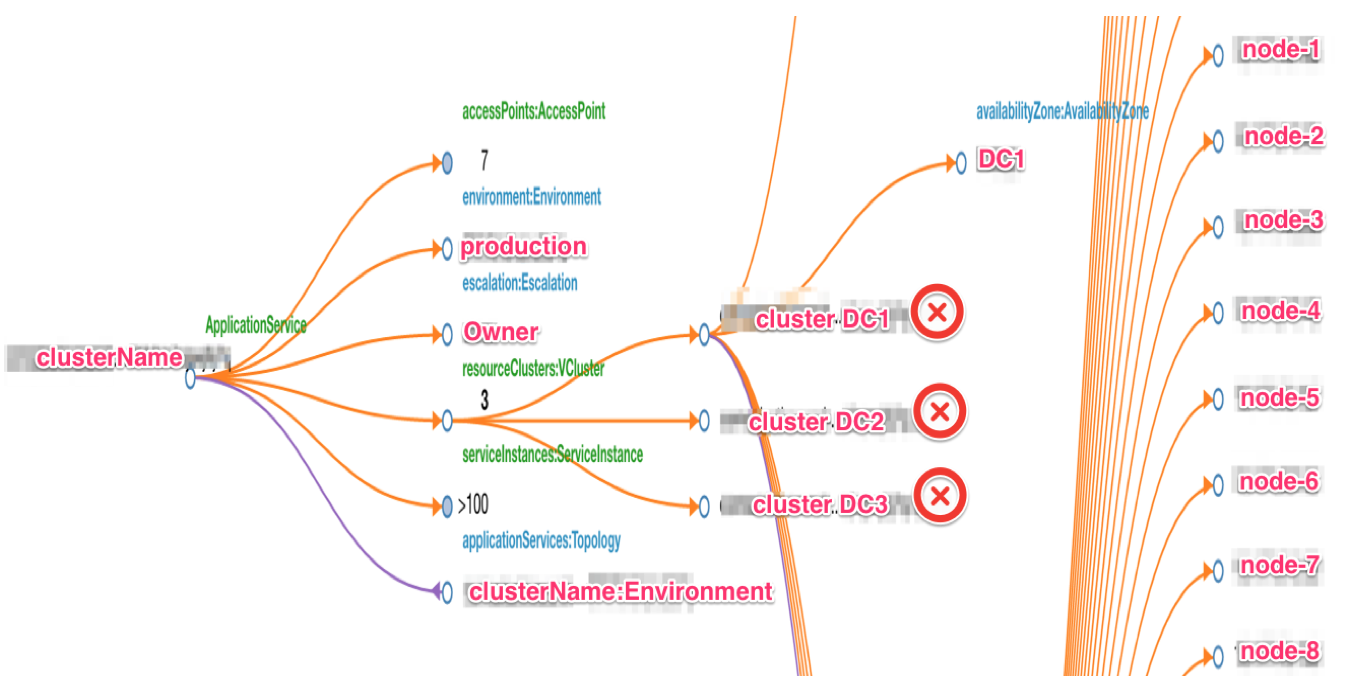
Cluster management
Cluster security
Security is provided on our clusters via a custom security plug-in that provides a mechanism to both authenticate and authorize the use of Elasticsearch clusters. Our security plug-in intercepts messages and then performs context-based authorization and authentication using an internal authentication framework. Explicit whitelisting based on client IP is supported. This is useful for configuring Kibana or other external UI dashboards. Admin (Dev-ops) are configured to have complete access to Elasticsearch cluster. We encourage using HTTPS (based on TLS 1.2) for securing communication between client and Elasticsearch clusters.
The following is a sample simple security rule that can configure be configured on our platform of provisioned clusters.
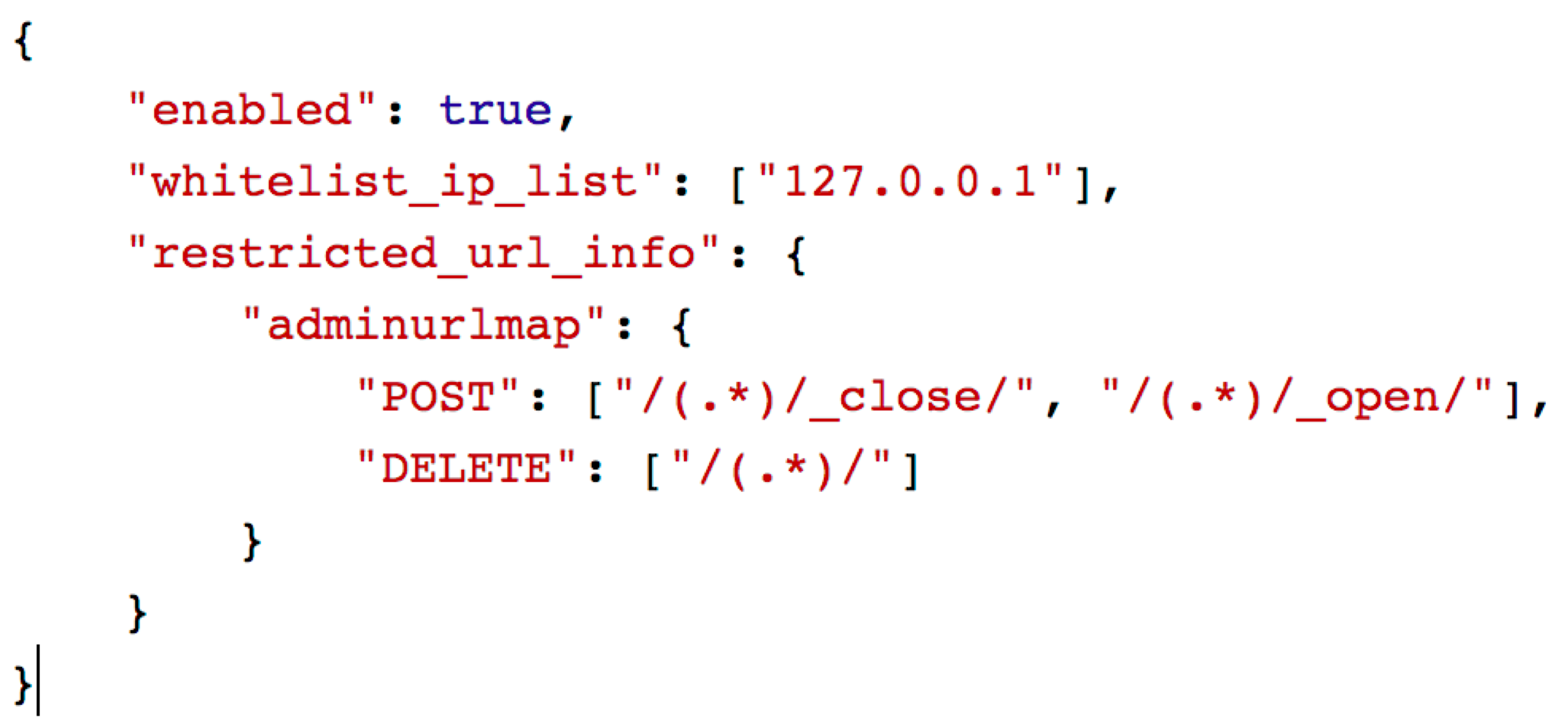
In the above sample rule, the enabled field controls if the security feature is enabled or not. whitelisted_ip_list is an array attribute for providing all whitelisted Client IPs. Any Open/Close index operations or delete index operations can be performed only by admin users.
Cluster monitoring
Cluster monitoring is done by custom monitoring plug-in that pushes 70+ metrics from each Elasticsearch node to a back-end TSDB-based data store. The plug-in works on a push-based design. External dashboards using Grafana consume the data on TSDB store. Custom templates are created on a Grafana dashboard, which allows easy centralized monitoring of our own clusters.
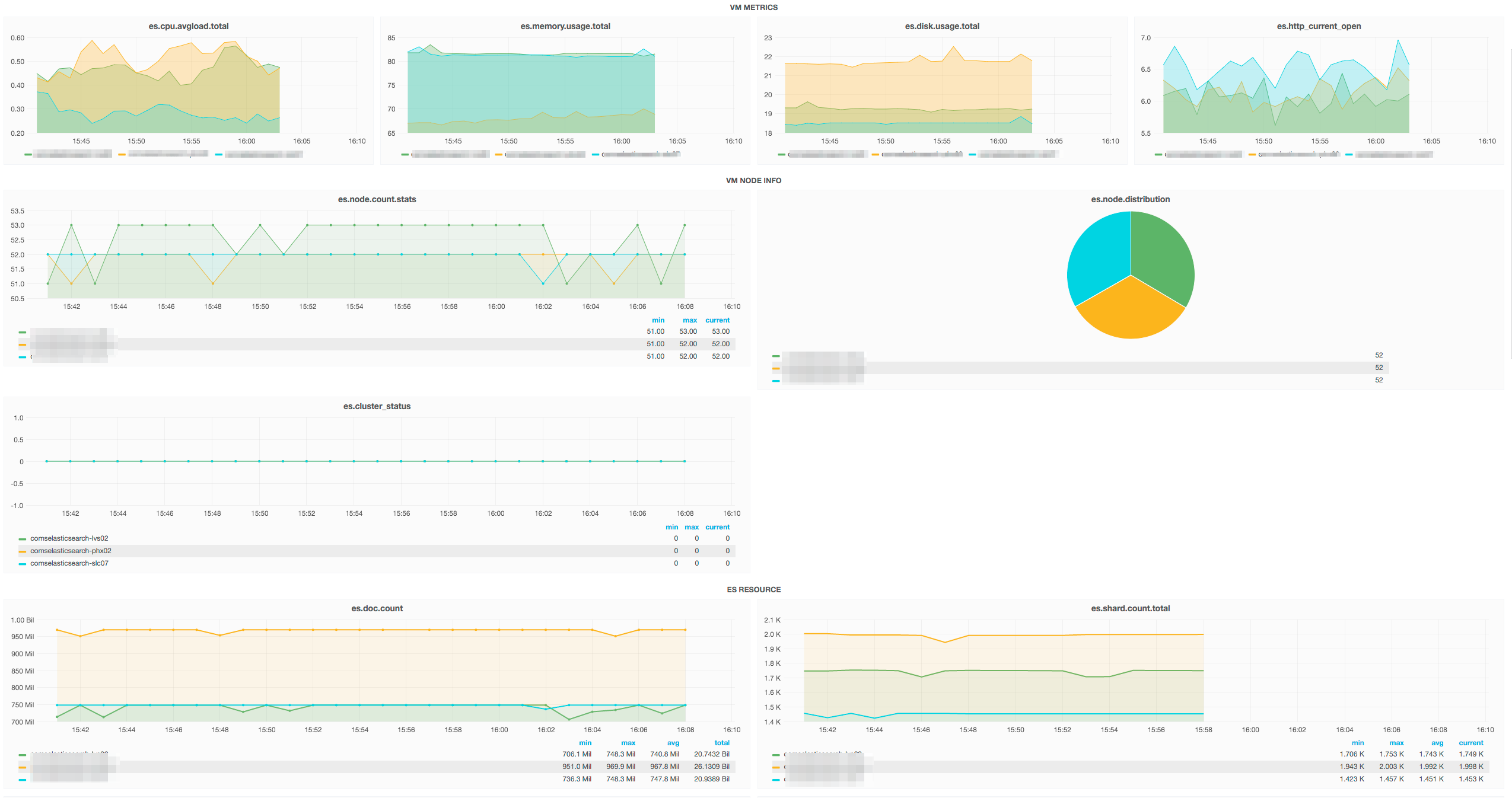
We leverage an internal alert system that can be used to configure threshold-based alerts on data stored on OpenTSDB. Currently, we have 500+ active alerts configured on our clusters with varying severity. Alerts are classified as ‘Errors’ or ‘Warnings’. Error alerts, when raised, are immediately attended to either by DevOps or by our internal auto-remediation engine, based on the alert rule configured.

Alerts are created during cluster provisioning based on various thresholds. For Example, if a cluster status turns RED, an ‘Error’ alert is raised or if CPU utilization of node exceeds 80% a ‘Warning’ alert is raised.
Cluster remediation
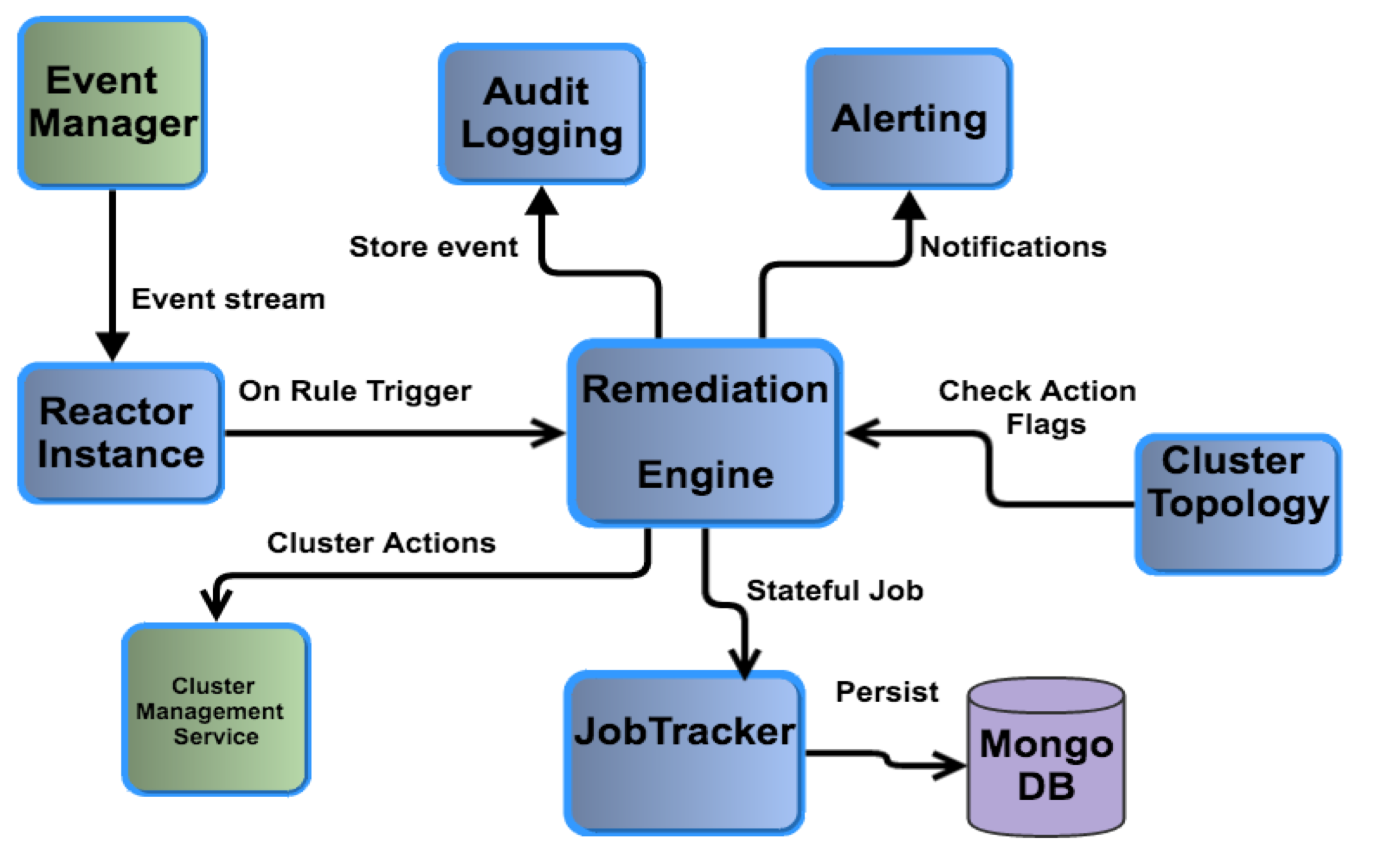
Our ES-AAS platform can perform an auto-remediation action on receiving any cluster anomaly event. Such actions are enabled via our custom Lights-Out-Management (LOM) module. Any auto-remediation module can significantly reduce manual intervention for DevOps. Our LOM module uses a rule-based engine which listens to all alerts raised on our cluster. The reactor instance maintains a context of the alerts raised and, based on cluster topology state (AUTO ON/OFF), takes remediation actions. For example, if a cluster loses a node and if this node does not return to its cluster within the next 15 minutes, the remediation engine replaces that node via our internal cluster management services. Optionally, alerts can be sent to the team instead of taking a cluster remediation action. The actions of the LOM module are tracked as stateful jobs that are persisted on a back-end MongoDB store. Due to the stateful nature of these jobs, they can be retried or rolled back as required. Audit logs are also maintained to capture the history or timeline of all remediation actions that were initiated by our custom LOM module.
Cluster logging
Along with the standard Elasticsearch distribution, we also ship our custom logging library. This library pushes all Elasticsearch application logs onto a back-end Hadoop store via an internal system called Sherlock. All centralized application logs can be viewed at both cluster and node levels. Once Elasticsearch log data is available on Hadoop, we run daily PIG jobs on our log store to generate reports for error log or slow log counts. We generally have our logging settings as INFO, and whenever we need to triage issues, we use transient a logging setting of DEBUG, which collects detailed logs onto our back-end Hadoop store.
Cluster decommissioning
We follow a cluster decommissioning process for major version upgrades of Elasticsearch. For major upgrades for Elasticsearch clusters, we spawn a new cluster with our latest offering of the Elasticsearch version. We replay all documents from old or existing version of Elasticsearch clusters to the newly created cluster. Client (user applications) starts using both cluster endpoints for all future ingestion until data catches up on the new cluster. Once data parity is achieved, we decommission the old cluster. In addition to freeing up infrastructure resources, we also clean up the associated cluster topology. Elasticsearch also provides a migration plug-in that can be used to check if direct, in-place upgrades can be done on major Elasticsearch versions. Minor Elasticsearch upgrades are done on an as-needed basis and are usually done in-place.