At eBay, we have multiple large, multi-tenant clusters. Each of these clusters stores hundreds of petabytes of data. These clusters offer tens of thousands of cores to run computations on the data. We have thousands of internal users who use Hadoop in their roles, including data analysts, data scientists, engineers, and product managers. These users use multiple technologies like MapReduce, Hive, and Spark to process data. There are thousands of applications that push and pull data from Hadoop and run computations.
 Figure 1: Hadoop clusters, auxiliary components, users, applications, and services
Figure 1: Hadoop clusters, auxiliary components, users, applications, and services
Pains
The users normally interact with the cluster via the command line by SSHing to specialized gateway machines that reside in the same network zone as the cluster. To transfer job files and scripts, the users need to SCP over multiple hops.
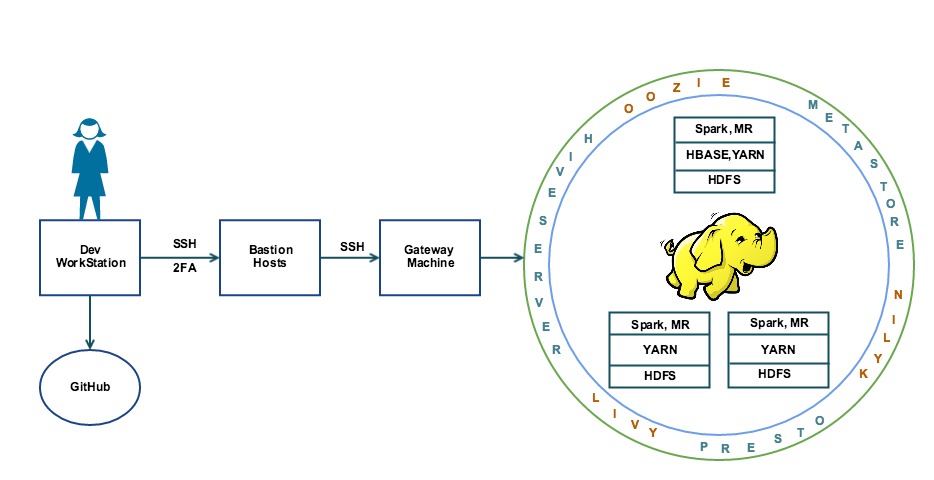 Figure 2: Old way of accessing a Hadoop cluster
Figure 2: Old way of accessing a Hadoop cluster
The need to traverse multiple hops as well as the command-line-only usage was a major hindrance to the productivity of our data users.
On the other side, our website applications and services need to access data and perform compute. These applications and services reside in a different network zone and hence need to set up network rules to access various services like HDFS, YARN, and Oozie. Since our clusters are secured with Kerberos, the applications need to be able to use Kerberos to authenticate to the Hadoop services. This was causing an extra burden for our application developers.
In this post, I will share the work in progress to facilitate access to our Hadoop clusters for data and compute resources by users and applications.
Requirements
We need better ways to achieve the following goals:
- Our engineers and other users need to use multiple clusters and related components.
- Data Analysts and other users need to run interactive queries and create shareable reports.
- Developers need to be able to develop applications and services without spending time on connectivity problems or Kerberos authentication.
- We can afford no compromise on security.
Solutions
To improve user experience and productivity, we added three open-source components:
Hue — to perform operations on Hadoop and related components.
Apache Zeppelin — to develop interactive notebooks with queries, programs, and reports.
Apache Knox — to serve as a single point for applications to access HDFS, Oozie, and other Hadoop services.
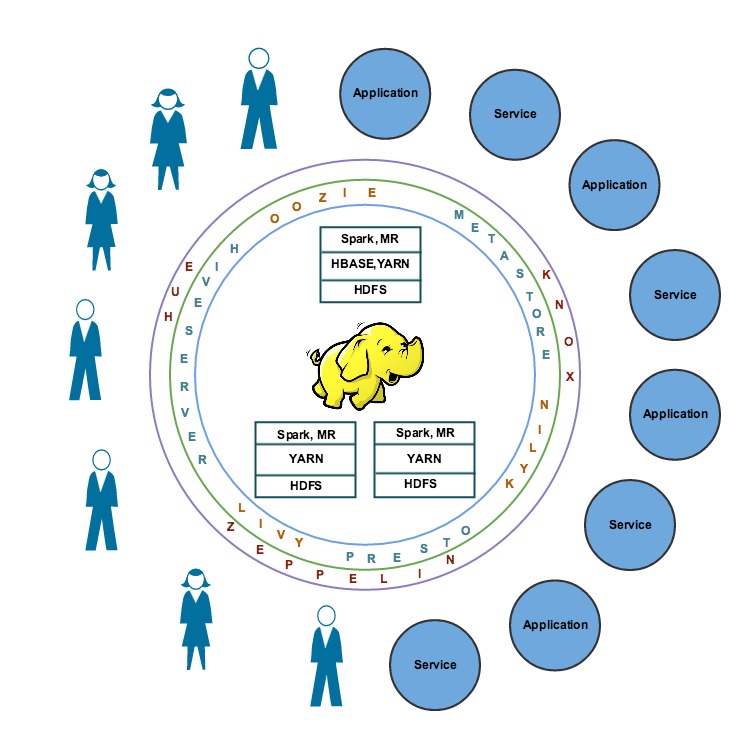 Figure 3: Enhanced user experience with Hue, Zeppelin, and Knox
Figure 3: Enhanced user experience with Hue, Zeppelin, and Knox
We will describe each product, the main use cases, a list of our customizations, and the architecture.
Hue
Hue is a user interface to the Hadoop ecosystem. It provides user interfaces to several components including HDFS, Oozie, Resource Manager, Hive, and HBase. It is a 100% open-source product, actively supported by Cloudera, and stored at the Hue GitHub site.
Similar products
Apache Airflow allows users to specify workflows in Python. Since we did not want a Python learning curve for our users, we chose Hue instead of Airflow. But we may find Airflow compelling enough to deploy it in future so that it can be used by people who prefer Airflow.
Use cases of Hue
Hue allows a user to work with multiple components of the Hadoop ecosystem. A few common use cases are listed below:
- To browse, manage, upload, and download HDFS files and directories
- To specify workflows comprising MapReduce, Hive, Pig, Spark, Java, and shell actions
- Schedule workflows and track SLAs
- To manage Hive metadata, run Hive queries, and share the queries with other users
- To manage HBase metadata and interact with HBase
- To view YARN applications and terminate applications if needed
Enhancements
Two-factor authentication — To ensure that the same security level is maintained as that of command-line access, we needed to integrate our custom SAML-based two-factor authentication in Hue. Hue supports plugging in new authentication mechanisms, using which we were able to plug in our two-factor authentication.
Ability to impersonate other users — At eBay, users sometimes operate on behalf of a team account. We added capability in Hue so that users can impersonate as another account as long as they are authorized to do so. The authorization is controlled by LDAP group memberships. The users can switch back between multiple accounts.
Working with multiple clusters — Since we have multiple clusters, we wanted to provide single Hue instance serving multiple Hadoop clusters and components. This enhancement required changes in HDFS File Browser, Job Browser, Hive Metastore Managers, Hive query editors, and work flow submissions.
Architecture
 Figure 4: Hue architecture at eBay
Figure 4: Hue architecture at eBay
Zeppelin
A lot of our users, especially data scientists, want to run interactive queries on the data stored on Hadoop clusters. They run one query, check its results, and, based on the results, form the next query. Big data frameworks like Spark, Presto, Kylin, and to some extent, HiveServer2 provide this kind of interactive query support.
Apache Zeppelin (GitHub repo) is a user interface that integrates well with products like Spark, Presto, Kylin, among others. In addition, Zeppelin provides an interface where users can develop data notebooks. The notebooks can express data processing logic in SQL or Scala or Python or R. Zeppelin also supports data visualization in notebooks in the form of tables and charts.
Zeppelin is an Apache project and is 100% open source.
Use cases
Zeppelin allows a user to develop visually appealing interactive notebooks using multiple components of the Hadoop ecosystem. A few common use cases are listed below:
- Run a quick Select statement on a Hive table using Presto.
- Develop a report based on a dataset by reading files from HDFS and persisting them in memory as Spark data frames.
- Create an interactive dashboard that allows users to search through a specific set of log files with custom format and schema.
- Inspect the schema of a Hive table.
Enhancements
Two-factor authentication — To maintain security parity with that command-line access, we plugged in our custom two-factor authentication mechanism in Zeppelin. Zeppelin uses Shiro for security, and Shiro allows one to plug in a custom authentication with some difficulty.
Support for multiple clusters — We have multiple clusters and multiple instances of components like Hive. To support multiple instances in one Zeppelin server, we created different interpreters for different clusters or server instances.
Capability to override interpreter settings at the user level — Some of the interpreter settings, such as job queues and memory values, among others, need to be customized by users for their specific use cases. To support this, we added a feature in Zeppelin so that users can override certain Interpreter settings by setting properties. This is described in detail in this Apache JIRA ticket ZEPPELIN-1625
Architecture
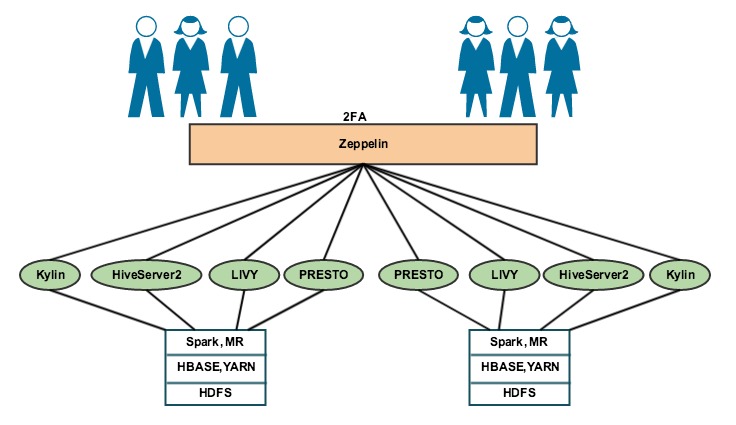 Figure 5: Zeppelin Architecture at eBay
Figure 5: Zeppelin Architecture at eBay
Knox
Apache Knox (GitHub repo) is an HTTP reverse proxy, and it provides a single endpoint for applications to invoke Hadoop operations. It supports multiple clusters and multiple components like webHDFS, Oozie, WebHCat, etc. It can also support multiple authentication mechanisms so that we can hook up custom authentication along with Kerberos authentication
It is an Apache top-level project and is 100% open source.
Use cases
Knox allows an application to talk to multiple Hadoop clusters and related components through a single entry point using any application-friendly non-Kerberos authentication mechanism. A few common use cases are listed below:
- To authenticate using an application token and put/get files to/from HDFS on a specific cluster
- To authenticate using an application token and trigger an Oozie job
- To run a Hive script using WebHCat
Enhancements
Authentication using application tokens — The applications and services in the eBay backend use a custom token-based authentication mechanism. To take advantage of the existing application credentials, we enhanced Knox to support our application token-based authentication mechanism in addition to Kerberos. Knox utilizes the Hadoop Authentication framework, which is flexible enough to plug in new authentication mechanisms. The steps to plug in an authentication mechanism on Hadoop’s HTTP interface is described in Multiple Authentication Mechanisms for Hadoop Web Interfaces
Architecture
 Figure 6: Knox Architecture at eBay
Figure 6: Knox Architecture at eBay
Summary
In this blog post, we describe the approach taken to improve user experience and developer productivity in using our multiple Hadoop clusters and related components. We illustrate the use of three open-source products to make Hadoop users’ life a lot simpler. The products are Hue, Zeppelin, and Knox. We evaluated these products, customized them for eBay’s purpose, and made them available for our users to carry out their projects efficiently.