In this post I finally get to the punch line and construct a set of approximations to  (actually
(actually  ) that cover a range of speeds and accuracies. As execution time decreases, so does the accuracy. You can choose an approximation with a tradeoff that meets your needs.
) that cover a range of speeds and accuracies. As execution time decreases, so does the accuracy. You can choose an approximation with a tradeoff that meets your needs.
When making a fast but approximate function, the design parameter is the form of the approximating function. Is it a polynomial of degree 3? Or the ratio of two linear functions? The table below has a systematic list of possibilities: the top half of the table uses only multiplication, the bottom half uses division.

Table 1: Approximating Functions
The rewritten column rewrites the expression in a more efficient form. The expressions are used in the approximation procedure as follows: to get the approximation to  , first
, first  is reduced to the interval
is reduced to the interval  , then
, then  is substituted into the expression. As I explained in Part I and Part II, this procedure gives good accuracy and avoids floating-point cancellation problems.
is substituted into the expression. As I explained in Part I and Part II, this procedure gives good accuracy and avoids floating-point cancellation problems.
For each form, the minimax values of  are determined—that is, the values that minimize the maximum relative error. The bits column gives the bits of accuracy, computed as
are determined—that is, the values that minimize the maximum relative error. The bits column gives the bits of accuracy, computed as  where
where  is the maximum relative error. This value is computed using the evaluation program from my Part II post, invoked as
is the maximum relative error. This value is computed using the evaluation program from my Part II post, invoked as  .
.
The “cost” column is the execution time. In olden days, floating-point operations were a lot more expensive than integer instructions, and they were executed sequentially. So cost could be estimated by counting the number of floating-point additions and multiplications. This is no longer true, so I estimate cost using the evaluation program. I put cost in quotes since the numbers apply only to my MacBook. The numbers are normalized so that the cost of log2f in the standard C library is 1.
It’s hard to grasp the cost and time numbers in a table. The scatter plot below is a visualization with lines 2–10 each represented by a dot.
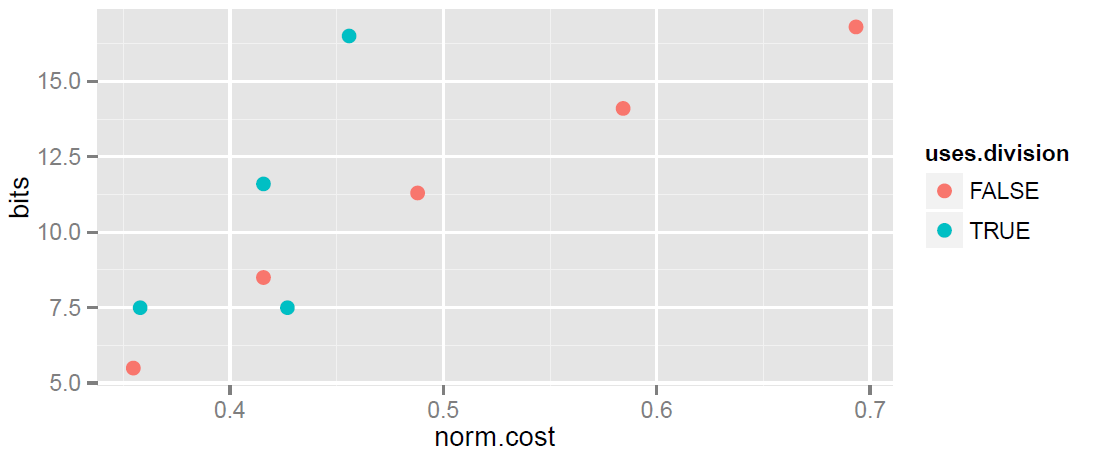
You can see one anomaly—the two blue dots that are (roughly) vertically stacked one above the other. They have similar cost but very different accuracy. One is the blue dot from line 9 with cost .43 and 7.5 bits of accuracy. The other is from line 3 which has about the same cost (0.42) but 8.5 bits of accuracy. So clearly, line 9 is a lousy choice. I’m not sure I would have guessed that without doing these calculations.
 . If
. If  is approximated by
is approximated by  on
on  , then
, then  in
in  , and this works out to be
, and this works out to be
![\[ \textstyle \frac{Ax - A}{x^2 + Bx + C} = \frac{Ax - A}{Cx + B + 1/x} } \]](assets/Uploads/Blog/Imported/quicklatex.com-60a9e1d3753a70040a7c24c28f808750_l3.svg "Rendered by QuickLaTeX.com")
which means that the denominators must be roughly equal. Multiplying each by  , this becomes
, this becomes  . The only way this can be true is if
. The only way this can be true is if  and
and  are very large, so that it’s as if the
are very large, so that it’s as if the  term doesn’t exist and the approximation
term doesn’t exist and the approximation  reduces to the quotient of two linear functions. And that is what happens. The optimal coefficients are on the order of
reduces to the quotient of two linear functions. And that is what happens. The optimal coefficients are on the order of  , which makes (now writing in terms of
, which makes (now writing in terms of  )
)  . Plugging in the optimal values
. Plugging in the optimal values  ,
,  ,
,  gives
gives  ,
,  , which are very similar to the coefficients in line 7 shown in Table 2 later in this post. In other words, the optimal rational function in line 9 is almost identical to the one in line 7. Which explains why the bit accuracy is the same.
, which are very similar to the coefficients in line 7 shown in Table 2 later in this post. In other words, the optimal rational function in line 9 is almost identical to the one in line 7. Which explains why the bit accuracy is the same.
In the next plot I remove line 9, and add lines showing the trend.
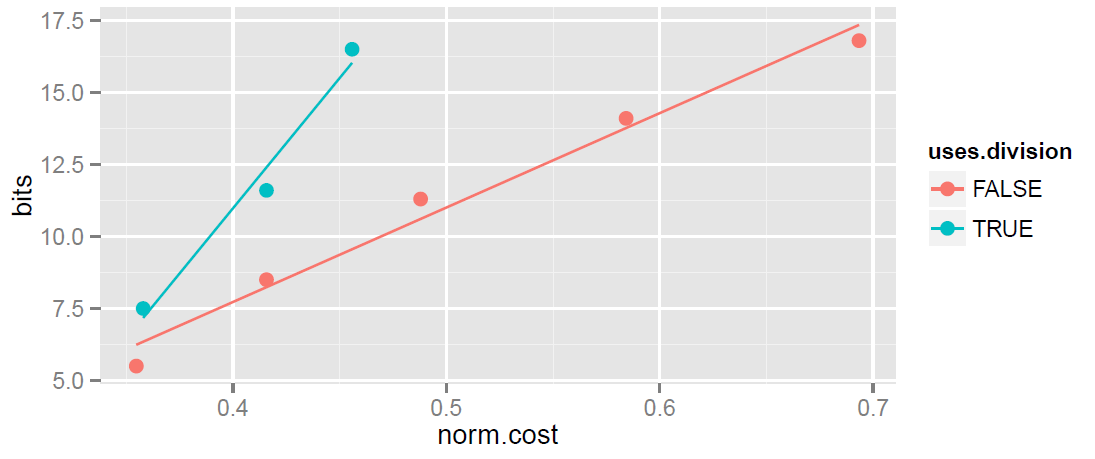
The lines show that formulas using division outperform the multiplication-only formulas, and that the gain gets greater as the formulas become more complex (more costly to execute).
You might wonder: if one division is good, are two divisions even better? Division adds new power because a formula using division can’t be rewritten using just multiplication and addition. But a formula with two divisions can be rewritten to have only a single division, for example
![\[ \frac{ay + b}{y + c + \frac{d}{y}} = \frac{(ay + b)y}{y(y+c) + d} \]](assets/Uploads/Blog/Imported/quicklatex.com-434bdfa962f05b8eb0b49949729ef05b_l3.svg "Rendered by QuickLaTeX.com")
Two divisions add no new functionality, but could be more efficient. In the example above, a division is traded for two multiplications. In fact, using two divisions gives an alternative way to write line 10 of Table 1. On my Mac, that’s a bad tradeoff: the execution time of the form with 2 divisions increases by 40%.
Up till now I’ve been completely silent about how I computed the minimax coefficients of the functions. Or to put it another way, how I computed the values of  ,
,  ,
,  , etc. in Table 1. This computation used to be done using the Remez algorithm, but now there is a simpler way that reduces to solving a convex optimization problem. That in turn can then be solved using (for example) CVX, a Matlab-based modeling system.
, etc. in Table 1. This computation used to be done using the Remez algorithm, but now there is a simpler way that reduces to solving a convex optimization problem. That in turn can then be solved using (for example) CVX, a Matlab-based modeling system.
Here’s how it works for line 8. I want to find the minimax approximation to . As discussed in the first post of this series, it’s the relative error that should be minimized. This means solving
![\[ \min_{A,B,C}\; \max_{0.75 \leq x \leq 1.5} \left | \frac{\frac{A(x-1)^2 + B(x-1)}{(x-1)+C} - \log_2 x}{\log_2 x} \right | \]](assets/Uploads/Blog/Imported/quicklatex.com-9e642ee0c100ed38b6576df470a2729f_l3.svg "Rendered by QuickLaTeX.com")
This is equivalent to finding the smallest  for which there are
for which there are  ,
,  , and
, and  satisfying
satisfying

For the last equation, pick  . Of course this is not exactly equivalent to being true for all
. Of course this is not exactly equivalent to being true for all  but it is an excellent approximation. The notation may be a little confusing, because
but it is an excellent approximation. The notation may be a little confusing, because  are constants, and , and are the variables. Now all I need is a package that will report if
are constants, and , and are the variables. Now all I need is a package that will report if
![\[ {\scriptstyle \left | A(x_i-1)^2 + B(x_i-1) - ((x_i-1) + C) \log_2 x_i \right | \leq \lambda ((x_i-1) + C) \log_2 x_i \;\;\; 1 \leq i \leq m } \]](assets/Uploads/Blog/Imported/quicklatex.com-62982e64bf43945d3447f9406c15c73b_l3.svg "Rendered by QuickLaTeX.com")
has a solution in , , . Because then binary search can be used to find the minimal . Start with  that you know has no solution and
that you know has no solution and  that is large enough to guarantee a solution. Then ask if the above has a solution for
that is large enough to guarantee a solution. Then ask if the above has a solution for  . If it does, replace
. If it does, replace  ; otherwise,
; otherwise,  . Continue until has the desired precision.
. Continue until has the desired precision.
The set of  satisfying the equation above is convex (this is easy to check), and so you can use a package like CVX for Matlab to quickly tell you if it has a solution. Below is code for computing the coefficients of line 8 in Table 1. This matlab/CVX code is modified from http://see.stanford.edu/materials/lsocoee364a/hw6sol.pdf.
satisfying the equation above is convex (this is easy to check), and so you can use a package like CVX for Matlab to quickly tell you if it has a solution. Below is code for computing the coefficients of line 8 in Table 1. This matlab/CVX code is modified from http://see.stanford.edu/materials/lsocoee364a/hw6sol.pdf.
It is a peculiarity of CVX that it can report  for a value of , but then report
for a value of , but then report  for a smaller value of . So when seeing I presume there is a solution, then decrease the upper bound and also record the corresponding values of
for a smaller value of . So when seeing I presume there is a solution, then decrease the upper bound and also record the corresponding values of  ,
,  , and
, and  . I do this for each step
. I do this for each step  of the binary search. I decide which to use by making an independent calculation of the minimax error for each set
of the binary search. I decide which to use by making an independent calculation of the minimax error for each set  .
.
You might think that using a finer grid (that is, increasing  so that there are more ) would give a better answer, but it is another peculiarity of CVX that this is not always the case. So in the independent calculation, I evaluate the minimax error on a very fine grid
so that there are more ) would give a better answer, but it is another peculiarity of CVX that this is not always the case. So in the independent calculation, I evaluate the minimax error on a very fine grid  that is independent of the grid size given to CVX. This gives a better estimate of the error, and also lets me compare the answers I get using different values of . Here is the CVX code:
that is independent of the grid size given to CVX. This gives a better estimate of the error, and also lets me compare the answers I get using different values of . Here is the CVX code:
format long
format compact
verbose=true
bisection_tol = 1e-6;
m=500;
lo=0.70; % check values a little bit below 0.75
hi=1.5;
xi = linspace(lo, hi, m)';
yi = log2(xi);
Xi = linspace(lo, hi, 10000); % pick large number so you can compare different m
Xi = Xi(Xi ~= 1);
Yi = log2(Xi);
xip = xi(xi >= 1); % those xi for which y = x-1 is positive
xin = xi(xi = 0.75);
xinn = xi(xi = 1);
yin = yi(xi = 0.75);
yinn = yi(xi = 0.75);
Xin = Xi(Xi = bisection_tol
gamma = (l+u)/2;
cvx_begin % solve the feasibility problem
cvx_quiet(true);
variable A;
variable B;
variable C;
subject to
abs(A*(xip - 1).^2 + B*(xip - 1) - yip .* (xip - 1 + C)) <= ...
gamma * yip .* (xip-1 + C)
abs(A*(xin - 1).^2 + B*(xin - 1)- yin .* (xin - 1 + C)) <= ...
-gamma * yin .* (xin-1 + C)
abs(A*(2*xinn - 1).^2 + B*(2*xinn - 1) - (1 + yinn) .* (2*xinn - 1 + C)) <= ...
-gamma * yinn .* (2*xinn - 1 + C)
cvx_end
if verbose
fprintf('l=%7.5f u=%7.5f cvx_status=%s\n', l, u, cvx_status)
end
if strcmp(cvx_status,'Solved') | strcmp(cvx_status, 'Inaccurate/Solved')
u = gamma;
A_opt(k) = A;
B_opt(k) = B;
C_opt(k) = C;
lo = (A*(2*Xin - 1).^2 + B*(2*Xin - 1)) ./ (2*Xin - 1 + C) - 1;
hi = (A*(Xip - 1).^2 + B*(Xip -1)) ./ (Xip - 1 + C);
fx = [lo, hi];
[maxRelErr(k), maxInd(k)] = max(abs( (fx - Yi)./Yi ));
k = k + 1;
else
l = gamma;
end
end
[lambda_opt, k] = min(maxRelErr);
A = A_opt(k)
B = B_opt(k)
C = C_opt(k)
lambda_opt
-log2(lambda_opt)
Here are the results of running the above code for the expressions in the first table. I don’t bother giving all the digits for line 9, since it is outperformed by line 7.

Table 2: Coefficients for Table 1
So, what’s the bottom line? If you don’t have specific speed or accuracy requirements, I recommend choosing either line 3 or line 7. Run both through the evaluation program to get the cost for your machine and choose the one with the lowest cost. On the other hand, if you have specific accuracy/speed tradeoffs, recompute the cost column of Table 1 for your machine, and pick the appropriate line. The bits column is machine independent as long as the machine uses IEEE arithmetic.
 with coefficients A = 0.1501692, B = 3.4226132, C = 5.0225057, D = 4.1130283, E = 3.4813372.
with coefficients A = 0.1501692, B = 3.4226132, C = 5.0225057, D = 4.1130283, E = 3.4813372.
Finally, I’ll close by giving the C code for line 8 (almost a repeat of code from the first posting). This is bare code with no sanity checking on the input parameter . I’ve marked the lines that need to be modified if you want to use it for a different approximating expression.
float fastlog2(float x) // compute log2(x) by reducing x to [0.75, 1.5)
{
/** MODIFY THIS SECTION **/
// (x-1)*(a*(x-1) + b)/((x-1) + c) (line 8 of table 2)
const float a = 0.338953;
const float b = 2.198599;
const float c = 1.523692;
#define FN fexp + signif*(a*signif + b)/(signif + c)
/** END SECTION **/
float signif, fexp;
int exp;
float lg2;
union { float f; unsigned int i; } ux1, ux2;
int greater; // really a boolean
/*
* Assume IEEE representation, which is sgn(1):exp(8):frac(23)
* representing (1+frac)*2^(exp-127). Call 1+frac the significand
*/
// get exponent
ux1.f = x;
exp = (ux1.i & 0x7F800000) >> 23;
// actual exponent is exp-127, will subtract 127 later
greater = ux1.i & 0x00400000; // true if signif > 1.5
if (greater) {
// signif >= 1.5 so need to divide by 2. Accomplish this by
// stuffing exp = 126 which corresponds to an exponent of -1
ux2.i = (ux1.i & 0x007FFFFF) | 0x3f000000;
signif = ux2.f;
fexp = exp - 126; // 126 instead of 127 compensates for division by 2
signif = signif - 1.0;
lg2 = FN;
} else {
// get signif by stuffing exp = 127 which corresponds to an exponent of 0
ux2.i = (ux1.i & 0x007FFFFF) | 0x3f800000;
signif = ux2.f;
fexp = exp - 127;
signif = signif - 1.0;
lg2 = FN;
}
// last two lines of each branch are common code, but optimize better
// when duplicated, at least when using gcc
return(lg2);
}
Addendum
In response to comments, here is some sample code to compute logarithms via table lookup. A single precision fraction has only 23 bits, so if you are willing to have a table of 223 floats (225 bytes) you can write a logarithm that is very accurate and very fast. The one thing to watch out for is floating-point cancellation, so you need to split the table into two parts (see the log_biglookup() code block below).
The log_lookup() sample uses a smaller table. It uses linear interpolation, because ordinary table lookup results in a step function. When x is near 0, log(1+x) ≈ x is linear, and any step-function approximation will have a very large relative error. But linear interpolation has a small relative error. In yet another variation, log_lookup_2() uses a second lookup table to speed up the linear interpolation.
float
log_lookup(float x) // lookup using NDIGIT_LOOKUP bits of the fraction part
{
int exp;
float lg2, interp;
union { float f; unsigned int i; } ux1, ux2;
unsigned int frac, frac_rnd;
/*
* Assume IEEE representation, which is sgn(1):exp(8):frac(23)
* representing (1+frac)*2ˆ(exp-127) Call 1+frac the significand
*/
// get exponent
ux1.f = x;
exp = ((ux1.i & 0x7F800000) >> 23); // -127 done later
// top NDIGITS
frac = (ux1.i & 0x007FFFFF);
frac_rnd = frac >> (23 - NDIGITS_LOOKUP);
// for interpolating between two table values
ux2.i = (frac & REMAIN_MASK) << NDIGITS_LOOKUP;
ux2.i = ux2.i | 0x3f800000;
interp = ux2.f - 1.0f;
if (frac_rnd < LOOKUP_TBL_LN/2) {
lg2 = tbl_lookup_lo[frac_rnd] + interp*(tbl_lookup_lo[frac_rnd+1] -
tbl_lookup_lo[frac_rnd]);
return(lg2 + (exp - 127));
} else {
lg2 = tbl_lookup_hi[frac_rnd] + interp*(tbl_lookup_hi[frac_rnd+1] -
tbl_lookup_hi[frac_rnd]);
return(-lg2 + (exp - 126));
}
}
static float
log_lookup_2(float x) // use a second table, tbl_interp[]
{
int exp;
float lg2;
union { float f; unsigned int i; } ux1;
unsigned int frac, frac_rnd, ind;
/*
* Assume IEEE representation, which is sgn(1):exp(8):frac(23)
* representing (1+frac)*2ˆ(exp-127) Call 1+frac the significand
*/
// get exponent
ux1.f = x;
exp = ((ux1.i & 0x7F800000) >> 23); // -127 done later
// top NDIGITS
frac = (ux1.i & 0x007FFFFF);
frac_rnd = frac >> (23 - NDIGITS_LOOKUP_2);
// for interpolating between two table values
ind = frac & REMAIN_MASK_2; // interp = tbl_inter[ind]
if (frac_rnd < LOOKUP_TBL_LN_2/2) {
lg2 = tbl_lookup_lo[frac_rnd] + tbl_interp[ind]*(tbl_lookup_lo[frac_rnd+1] -
tbl_lookup_lo[frac_rnd]);
return(lg2 + (exp - 127));
} else {
lg2 = tbl_lookup_hi[frac_rnd] + tbl_interp[ind]*(tbl_lookup_hi[frac_rnd+1] -
tbl_lookup_hi[frac_rnd]);
return(-lg2 + (exp - 126));
}
}
static float
log_biglookup(float x) // full lookup table with 2^23 entries
{
int exp;
float lg2;
union { float f; unsigned int i; } ux1;
unsigned int frac;
/*
* Assume IEEE representation, which is sgn(1):exp(8):frac(23)
* representing (1+frac)*2ˆ(exp-127) Call 1+frac the significand
*/
// get exponent
ux1.f = x;
exp = ((ux1.i & 0x7F800000) >> 23); // -127 done later
frac = (ux1.i & 0x007FFFFF);
if (frac < TWO_23/2) {
lg2 = tbl_lookup_big_lo[frac];
return(lg2 + (exp - 127));
} else {
lg2 = tbl_lookup_big_hi[frac - TWO_23/2];
return(-lg2 + (exp - 126));
}
}
#define NDIGITS_LOOKUP 14
#define LOOKUP_TBL_LN 16384 // 2^NDIGITS
#define REMAIN_MASK 0x1FF // mask with REMAIN bits where REMAIN = 23 - NDIGITS
static float *tbl_lookup_lo;
static float *tbl_lookup_hi;
static void
init_lookup()
{
int i;
tbl_lookup_lo = (float *)malloc(( LOOKUP_TBL_LN/2 + 1)*sizeof(float));
tbl_lookup_hi = (float *)malloc(( LOOKUP_TBL_LN + 1)*sizeof(float));
tbl_lookup_hi = tbl_lookup_hi - LOOKUP_TBL_LN/2;
for (i = 0; i <= LOOKUP_TBL_LN/2; i++) // <= not <
tbl_lookup_lo[i] = log2f(1 + i/(float)LOOKUP_TBL_LN);
for (i = LOOKUP_TBL_LN/2; i < LOOKUP_TBL_LN; i++)
// log2, not log2f
tbl_lookup_hi[i] = 1.0 - log2(1 + i/(float)LOOKUP_TBL_LN);
tbl_lookup_hi[LOOKUP_TBL_LN] = 0.0f;
}
/* two tables */
#define NDIGITS_LOOKUP_2 12
#define LOOKUP_TBL_LN_2 4096 // 2^NDIGITS
#define TWO_REMAIN_2 2048 // 2^REMAIN, where REMAIN = 23 - NDIGITS
#define REMAIN_MASK_2 0x7FF // mask with REMAIN bits
static float *tbl_interp;
static void
init_lookup_2()
{
int i;
tbl_lookup_lo = (float *)malloc(( LOOKUP_TBL_LN_2/2 + 1)*sizeof(float));
tbl_lookup_hi = (float *)malloc(( LOOKUP_TBL_LN_2/2 + 1)*sizeof(float));
tbl_lookup_hi = tbl_lookup_hi - LOOKUP_TBL_LN_2/2;
tbl_interp = (float *)malloc(TWO_REMAIN_2*sizeof(float));
// lookup
for (i = 0; i <= LOOKUP_TBL_LN_2; i++)
tbl_lookup_lo[i] = log2f(1 + i/(float)LOOKUP_TBL_LN_2);
for (i = LOOKUP_TBL_LN_2/2; i < LOOKUP_TBL_LN_2; i++)
// log2, not log2f
tbl_lookup_hi[i] = 1.0 - log2(1 + i/(float)LOOKUP_TBL_LN_2);
tbl_lookup_hi[LOOKUP_TBL_LN_2] = 0.0f;
for (i = 0; i < TWO_REMAIN_2; i++)
tbl_interp[i] = i/(float)TWO_REMAIN_2;
}
#define TWO_23 8388608 // 2^23
static float *tbl_lookup_big_lo;
static float *tbl_lookup_big_hi;
static void
init_biglookup()
{
int i;
tbl_lookup_big_lo = (float *)malloc((TWO_23/2) * sizeof(float));
tbl_lookup_big_hi = (float *)malloc((TWO_23/2) * sizeof(float));
for (i = 0; i < TWO_23/2; i++) {
tbl_lookup_big_lo[i] = log2f(1 + i/(float)TWO_23);
// log2, not log2f
tbl_lookup_big_hi[i] = 1.0 - log2(1 + (i+ TWO_23/2)/(float)TWO_23);
}
}
Powered by QuickLaTeX