Overview of Griffin
At eBay, when people use big data (Hadoop or other streaming systems), measurement of data quality is a significant challenge. Different teams have built customized tools to detect and analyze data quality issues within their own domains. As a platform organization, we think of taking a platform approach to commonly occurring patterns. As such, we are building a platform to provide shared infrastructure and generic features to solve common data quality pain points. This will enable us to build trusted data assets.
Currently it is very difficult and costly to validate data quality when we have large volumes of related data flowing across multiple platforms (streaming and batch). Take eBay’s Bullseye Personalization Platform as an example: every day we have to validate the data quality for ~600M records. Data quality often becomes an enormous challenge in this complex environment and at this massive scale.
Our investigation found the following gaps at eBay:
- No end-to-end unified view of data quality from multiple data sources to target applications that takes account of data lineage. This results in a long delay in identifying and fixing data quality issues.
- No system to measure data quality in streaming mode through self-service. The need is for a system with a simple tool for registering data assets, defining data quality models, visualizing and monitoring data quality, and alerting teams when an issue is detected.
- No shared platform and API service. Each team should not have to apply and manage its own hardware and software infrastructure to solve this common problem.
With these needs in mind, we decided to build Griffin, a data quality service that aims to solve these shortcomings. Griffin is an open-source solution for validating the quality of data in an environment with distributed data systems, such as Hadoop, Spark, and Storm. It creates a unified process to define, measure, and report quality for the data assets in these systems. You can see Griffin’s source code at its home page on GitHub.
Features
- Accuracy measurement: Assessment of the accuracy of a data asset compared to a verifiable source
- Data profiling: Statistical analysis and assessment of data values within a data asset for consistency, uniqueness, and logic
- Anomaly detection: Pre-built algorithmic functions for the identification of events that do not conform to an expected pattern in a data asset
- Visualization: Dashboards that can report the state of data quality
Key benefits
- Real-time: The data quality checks can be executed in real time to detect issues faster.
- Extensible: The solution can work with multiple data systems.
- Scalable: The solution is designed to work on large volumes of data. It currently runs on ~1.2 PB of data.
- Self-serviceable: The solution provides a simple user interface to define new data assets and rules. It also allows users to visualize the data quality dashboards and personalize their view of the dashboards.
System process
Griffin has been deployed at eBay and is serving major data systems. It takes a platform approach to providing generic features to solve common data quality validation pain points. To detect data quality issues, the key process is as follows.
- The user registers the data asset.
- The Model Engine creates a data quality model for the data asset.
- The Model Engine calculates metrics.
- Any data quality issue is reported through email or the web portal.
The following BPMN (Business Process Model and Notation) diagram illustrates the system process.
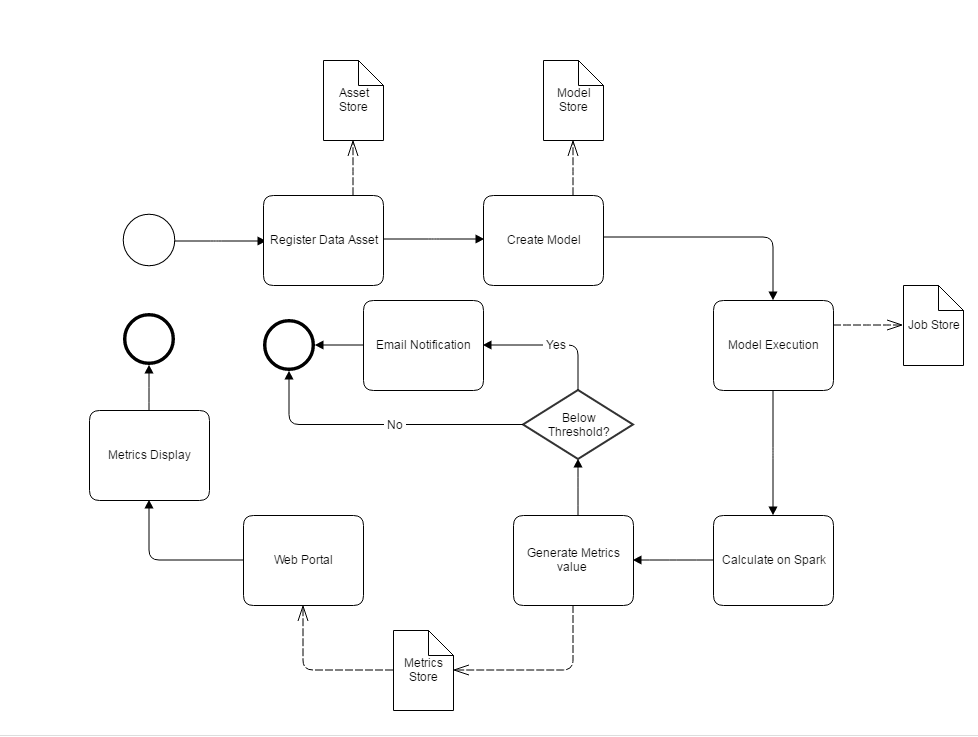
The following sections describe each step in detail.
Registering the data asset
The user can register the data set to be used for a data quality check. The data set can be batch data in an RDBMS (for example, Teradata), a Hadoop system, or near real-time streaming data from Kafka, Storm, and other real-time data platforms. Normally, some basic information should be provided for the data asset, including name, type, schema definition, owner, and other items.
Creating the model
After the data asset is ready, the user can create a data quality model to define the data quality rules and metadata. We can define models for different data quality dimensions, such as accuracy, data profiling, anomaly detection, validity, timeliness, and so on.
Executing the model
The model or rule is executed automatically (by the Model Engine) to get the sample data quality validation results in a few seconds for streaming data. “Data quality model design” introduces the details of how the Model Engine is designed and executed.
Calculating on Spark
The models are running on Spark. They can calculate data quality values for both real-time and batch data. Large-scale data can be handled in a timely fashion.
Generating the metrics value
After the data quality values are calculated, the metrics value is generated based on the calculation results and persisted in the MongoDB database.
Notifying by email
If any metrics value is below its threshold, an email notification is triggered and the end user is notified as soon as any data quality issue occurs.
Web portal and metrics display
Finally, all metrics values are displayed in the web portal, so that the user can analyze the data quality results through Griffin’s built-in visualization tool and then take action.
System architecture
To accomplish this process, we designed three layers for the entire system, as shown in the following architecture design diagram:
- Data collection and processing layer
- Back-end service layer
- User interface
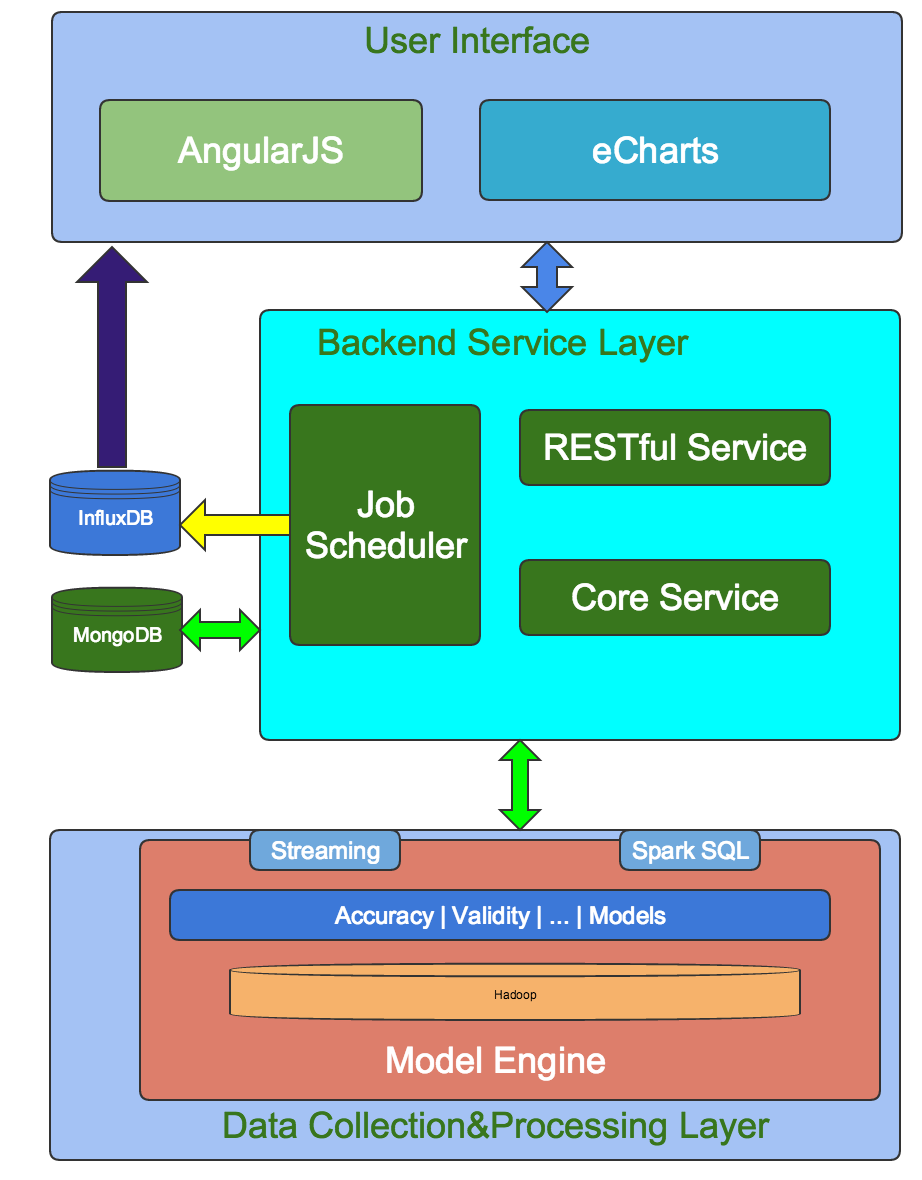
Data collection and processing layer
The key component of this layer is our Model Engine. Griffin is a model-driven solution, and the user can choose various data quality dimensions to execute data quality validation based on a selected target data set or source data set (as the golden reference data). It has a corresponding library supporting it in the back end for measurements.
We support two kinds of data sources: batch data and real-time data. For batch mode, we can collect the data source from our Hadoop platform by various data connectors. For real-time mode, we can connect with messaging systems like Kafka to achieve near real-time analysis. After retrieving the data, the Model Engine computes data quality metrics in our Spark cluster.
Back-end service layer
On the back-end service layer, we have three key components.
- The Core Service is responsible for metadata management, such as model definition, subscription management, user customization, and so on.
- The Job Scheduler is responsible for scheduling the jobs, interacting with Model Engine, saving metrics values, sending email notifications, etc.
- RESTful web services accomplish all the functions of Griffin, such as registering data sets, creating data quality models, publishing metrics, retrieving metrics, and adding subscriptions. Developers can develop their own user interfaces using these web services.
User Interface
We have a built-in visualization tool for Griffin. It’s a web front-end application that leverages AngularJS and eCharts to give you an effective tool for performing data quality activities. Here are some screenshots.
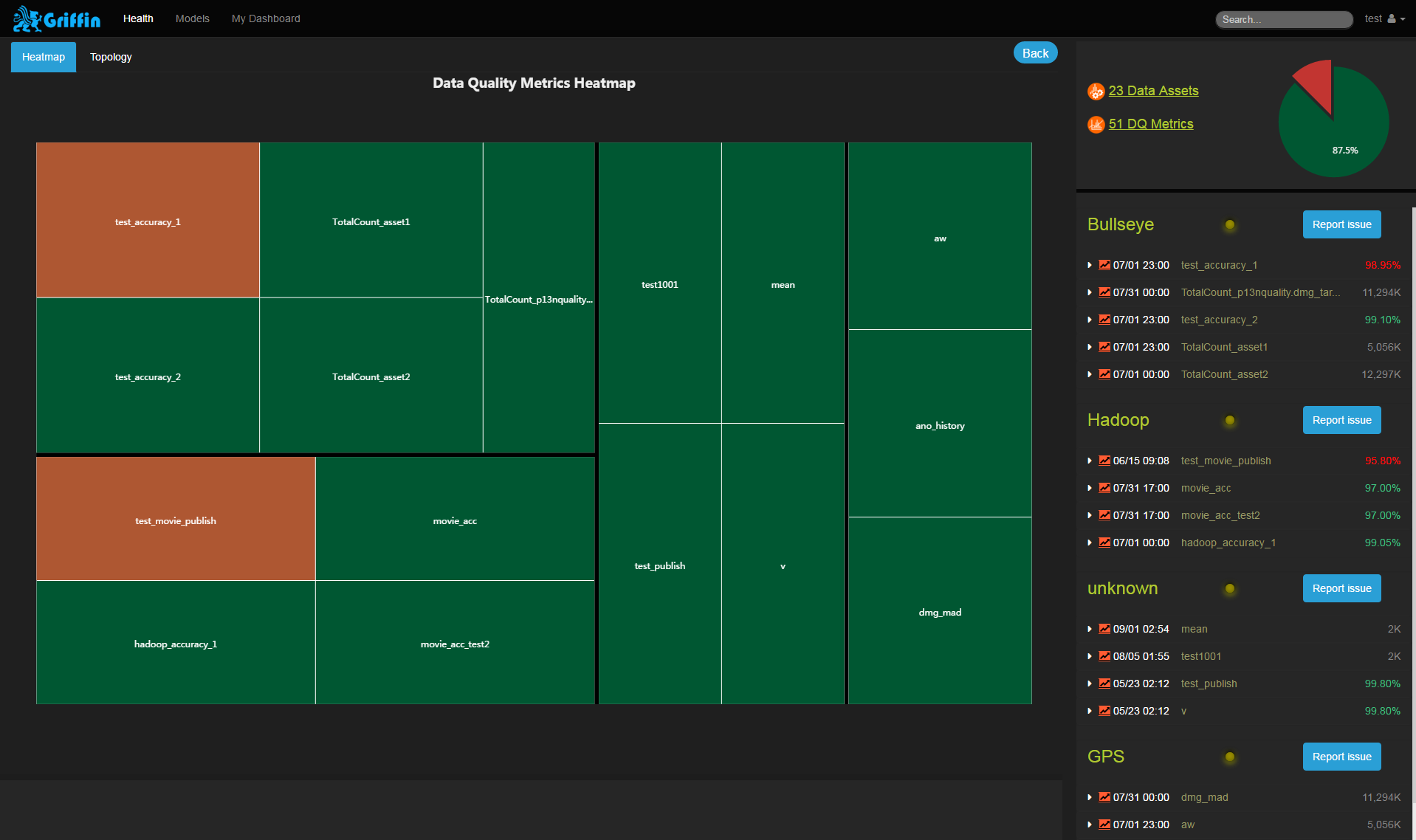
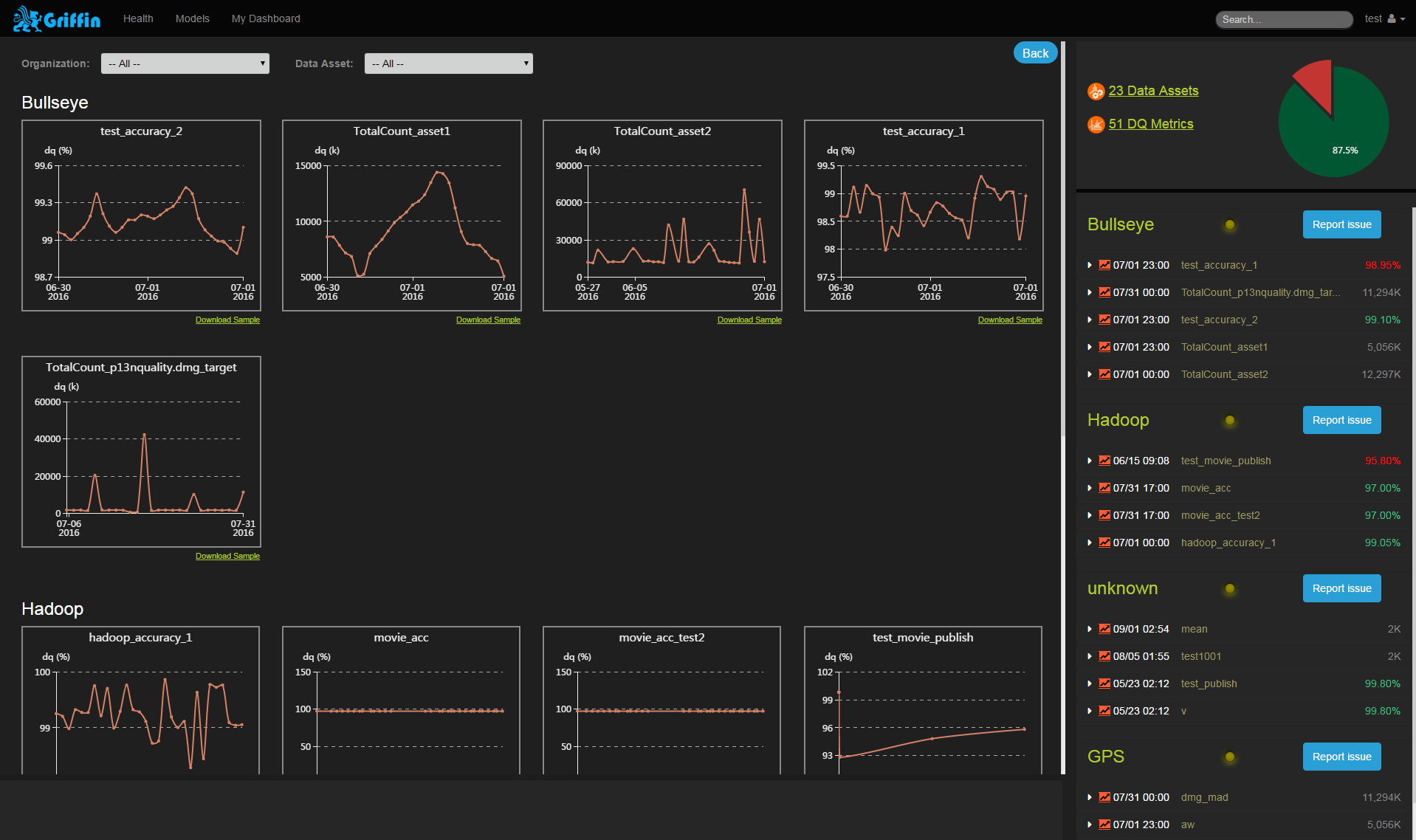
Besides the built-in UI, developers can easily develop other kinds of user interfaces by calling the RESTful services provided by Griffin.
Data quality model design
Currently, Griffin support three types of models:
- Accuracy
- Data profiling
- Anomaly detection
Accuracy provides the measurement of the accuracy rate for a data asset. Data profiling provides a way to perform data assessment by investigating the characteristics of subject data sets. Anomaly detection provides the ability to predict data issues by applying some mathematical algorithms.
Accuracy
Given a data set, does this target data set accurately represent the “real-world” values that they are expected to represent? We can define “real-world” values as a source of truth or golden reference data set, which could come from upstream after some data processing logic or from the user’s requirement directly or from a third-party’s certified data.
Now we know how to get a golden data set and target data set, and furthermore, if we know how to compare the target data set against the golden data set by defining some mapping rules, we can measure the accuracy of the target data set.
For example, if a source file has 100 records, but in the target file only 95 records exactly match with records in the source file, then the accuracy rate is 95/100 * 100% = 95.00%.
Approach
Creating an accuracy model takes three steps:
- The user defines the golden data set (as the source of truth). In our solution, the user can register the golden data set first or just select an existing one in the next step.
- The user defines mapping rules between the target data set and the golden data set. In our solution, the user can define mapping rules by selecting corresponding columns (fields) in the UI page.
- The user submits the job, and back-end jobs calculate the accuracy model.
Back-end implementation
This section describes how the back end measures the accuracy dimension of a target data set T, given the source of truth as golden data set S.
To measure the accuracy quality of target dataset T, the basic approach is to calculate the discrepancy between the target and source data sets by going through their contents and examining whether all fields are exactly matched as below,
Accuracy = Count(source.field1 == target.field1 && source.field2 == target.field2 && source.field3 == target.field3 && ...source.fieldN == target.fieldN)/Count(source)
Our two data sets are too big to fit in one box, so our approach is to leverage the MapReduce programming model by distributed computing.
The real challenge is how to make this comparing algorithm generic enough to relieve data analysts and data scientists from coding burdens and at the same time keep it flexible enough to cover most accuracy requirements.
The conventional way is to use SQL joins to calculate this, like scripts in Hive, but this SQL-based solution can be improved since it has not considered the unique natures of the source data set and target data set in this context.
Our approach is to provide a generic accuracy model, after taking into consideration the special natures of the source data set and target data set.
Our implementation is in Scala, leveraging Scala’s declarative capability to accommodate various requirements and running in a Spark cluster.
Data Profiling
Profiling Types
Data quality issues can be identified via different data profiling types. Profiling results can be compared with documented expectations, and an alert report is triggered if the result doesn’t meet the expectations.
There are three types of profiling provided in our framework:
- Simple statistics generates null, unique, and duplicate count profiles. For example, the null count profile reports the count of null values in the selected column. It helps the customer to identify problems in the data, such as an unexpectedly high ratio of null values in a column. An example is to profile an Email Address column and discover an unacceptably high volume of missing email addresses.
- Summary statistics generate max, min, mean, and median number profiles. For example, for Age, the value usually should be less than 150 and greater than 0. The user can do range checking with the max/min profile on the Age column.
-
Advanced statistics generates the frequency of pattern profiles, expressed with regular expressions. For example, a pattern profile of a United States Zip Code column might produce the regular expressions
\d{5}-\d{4},\d{5}, and\d{9}. If you see other formats, your data likely contains values that are not valid or in an incorrect format.
Backend implementation
Our data profiling mechanism is based on the column summary statistics functions provided in MLib of Spark, which enables us to calculate only once for all basic statistics on Number data type columns.
Key benefits
- Fast profiling of big data, since our framework is based on Spark
- Auto-scheduling for data profiling after model creation
- Visualization including a history trend
Anomaly detection
The goal of anomaly detection is to identify cases that are unusual within data that is seemingly homogeneous. Anomaly detection is an important tool for detecting data quality issues.
For now, we have implemented some statistical detection functions by using the Bollinger Band and MAD (Mean Absolute Deviation) algorithms to find those data sets whose total count falls out of expected region. The expected region is calculated based on the history trend of each day’s total count.
Our anomaly detection also allows users to adjust parameters in the algorithm as needed and dynamically show the results after changing the parameters, so that anomaly detection is customized for the specific user.
Back-end implementation
Let’s take MAD as an example, the MAD of a data set is the average distance between each data value and the mean. These steps calculate the MAD:
- Find the mean (average).
- Find the difference between each data value and the mean.
- Take the absolute value of each difference.
- Find the mean (average) of these differences.
The following diagram shows the formula of MAD:

The calculation of Bollinger Bands is similar to that of MAD. For more information, refer to Wikipedia’s article about Bollinger Bands.
Griffin at eBay
Griffin is deployed in production at eBay and provides centralized data quality service for several eBay systems (for example, the Bullseye Personalization Platform, Hadoop data sets, and site-speed data). Griffin validates more than 800M records daily.
What’s Next?
- We will introduce Griffin to more eBay systems, making it the unified data quality platform within eBay.
- We will support more data quality dimensions, such as validity, completeness, uniqueness, timeliness, and consistency.
- We will develop more machine-learning algorithms to detect even deeper relationships within data content and find data quality issues.