At eBay, we run Hadoop clusters comprised of thousands of nodes that are shared by thousands of users. We store hundreds of petabytes of data in our Hadoop clusters. In this post, we look at how to optimize big data storage based on frequency of data usage. This method helps reduce the cost in an effective manner.
Hadoop and its promise
It is now common knowledge that commodity hardware can be grouped together to create a Hadoop cluster with big data storage and computing capability. Parts of the data are stored in each individual machine, and data processing logic is also run on the same machines.

For example: A 1,000-node Hadoop cluster with storage capacity of 20 TB per node can store up to 20 petabytes (PB) of data. All these machines have sufficient computing power to fulfill Hadoop’s motto of “take compute to data.”
Temperature of data
Different types of datasets are usually stored in the clusters, which are shared by different teams running different types of workloads to crunch through the data. Each dataset is enhanced and enriched by daily and hourly feeds through the data pipelines.
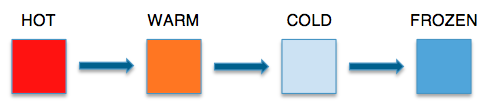
A common trait of datasets is heavy initial usage. During this period the datasets are considered HOT. Based on our analysis, we found there is a definite decline in usage with time, where the stored data is accessed a few times a week and ages to being WARM data. In the next 90 days, when data usage falls to a few times a month, it is defined as COLD data.
So data can be considered HOT during its initial days, then it remains WARM in the first month. Jobs or applications use the data a few times during this period. The data’s usage goes down further; the data becomes COLD, and may be used only a handful of times in the next 90 days. Finally, when the data is very rarely used, at a frequency of once or twice per year, the “temperature” of the data is referred to as FROZEN.
| Data Age | Usage Frequency | Temperature |
| Age < 7 days | 20 times a day | HOT |
| 7 days > Age < 1 month | 5 times a week | WARM |
| 1 month < Age < 3 months | 5 times a month | COLD |
| 3 months < Age < 3 years | 2 times a year | FROZEN |
In general, a temperature can be associated with each dataset. In this case, temperature is inversely proportional to the age of the data. Other factors can affect the temperature of a particular dataset. You can also write algorithms to determine the temperature of datasets.
Tiered storage in HDFS
HDFS supports tiered storage since Hadoop 2.3.
How does it work?
Normally, a machine is added to the cluster, and local file system directories are specified to store the block replicas. The parameter used to specify the local storage directories is dfs.datanode.data.dir. Another tier, such as ARCHIVE, can be added using an enum called StorageType. To denote that a local directory belongs to the ARCHIVE tier, the directory is prefixed in the configuration with [ARCHIVE]. In theory, multiple tiers can exist, as defined by a Hadoop cluster administrator.
For example: Let’s add 100 nodes that contain 200 TB of storage per node to an existing 1,000-node cluster having a total of 20 PB of storage. These new nodes have limited computing capability compared to the existing 1,000 nodes. Let’s prefix all the local data directories with ARCHIVE. These 100 nodes now form the ARCHIVE tier and can store 20 PB of data. The total capacity of the cluster is 40 PB, which is divided into two tiers – the DISK tier and the ARCHIVE tier. Each tier has 20 PB.

Mapping data to a storage tier based on temperature
For this example, we will store the heavily used HOT data in the DISK tier, which has nodes with better computing power.
For WARM data, we will keep most of its replicas in the DISK tier. For data with a replication factor of 3, we will keep two replicas in the DISK tier and one replica in the ARCHIVE tier.
If data is COLD, we will keep at least one replica of each block of the COLD data in the DISK tier. All the remaining replicas go to the ARCHIVE tier.
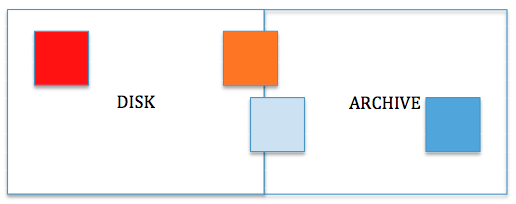
When a dataset is deemed FROZEN, which means it is almost never used, it is not optimal to store it on a node that has lots of CPU power to run many tasks or containers. We will keep it on a node that has minimal computing power. Thus, all the replicas of all blocks of FROZEN data can move to the ARCHIVE tier.
Data flow across tiers
When data is first added to the cluster, it gets stored in the default tier, DISK. Based on the temperature of the data, one or more replicas are moved to the ARCHIVE tier. Mover is used for data movement from one storage tier to another tier. Mover works similarly to Balancer except that it moves block replicas across tiers. Mover accepts an HDFS path, a replica count, and destination tier information. Then it identifies the replicas to be moved based on the tier information, and schedules the moves between source and destination data nodes.
Changes in Hadoop 2.6 to support tiered storage
Many improvements in Hadoop 2.6 further support tiered storage. You can attach a storage policy to a directory to denote it as HOT, WARM, COLD, or FROZEN. The storage policy defines the number of replicas to be located on each tier. It is possible to change the storage policy on a directory and then invoke Mover on that directory to make the policy effective.
Applications using data
Based on the data temperature, some or all replicas of data could be on either tier. But the location is transparent to applications consuming the data via HDFS.
Even though all the replicas of FROZEN data are on ARCHIVE storage, applications can still access it just like any HDFS data. Because no computing power is available on ARCHIVE nodes, mapped tasks running on DISK nodes will read the data from ARCHIVE nodes, which leads to increased network traffic for the applications. If this occurs too frequently, you can declare the data as WARM/COLD, and Mover can move one or more replicas back to DISK.
The determination of data temperature and the designated replica movement to pre-defined tiered storage can be fully automated.
Tiered storage at eBay
Tiered storage is enabled in one of the very large clusters at eBay. The cluster had 40 PB of data. We added 10 PB of additional storage with limited computing power. Each new machine could store 220 TB. We marked the additional storage as ARCHIVE. We identified a few directories as WARM, COLD, or FROZEN. Based on their temperature, we moved all or a few replicas to the ARCHIVE storage.
The price per GB of the ARCHIVE tier is four times less than the price per GB on the DISK tier. This difference is mainly because machines in the ARCHIVE tier have very limited computing power and hence lower costs.
Summary
Storage without computing is cheaper than storage with computing. We can use the temperature of the data to make sure that storage with computing is wisely used. Because each block of data is replicated a few times (the default is three), some replicas can be moved to the low-cost storage based on the temperature of the data. HDFS supports tiered storage and provides the necessary tools to move data between tiers. Tiered storage is enabled on one of the very large clusters at eBay to archive data.
Benoy Antony is an Apache Hadoop committer who focuses on HDFS and Hadoop security. Benoy works as a software engineer in the Global Data Infrastructure team at eBay.