At eBay we run Hadoop clusters comprising thousands of nodes that are shared by thousands of users. We analyze data on these clusters to gain insights for improved customer experience. In this post, we look at distributing RPC resources fairly between heavy and light users, as well as mitigating denial of service attacks within Hadoop. By providing appropriate response times and increasing system availability, we offer a better Hadoop experience.
Problem: namenode slowdown
In our clusters, we frequently deal with slowness caused by heavy users, to the point of namenode latency increasing from less than a millisecond to more than half a second. In the past, we fixed this latency by finding and terminating the offending job. However, this reactive approach meant that damage had already been done—in extreme cases, we lost cluster operation for hours.
This slowness is a consequence of the original design of Hadoop. In Hadoop, the namenode is a single machine that coordinates HDFS operations in its namespace. These operations include getting block locations, listing directories, and creating files. The namenode receives HDFS operations as RPC calls and puts them in a FIFO call queue for execution by reader threads. The dataflow looks like this:
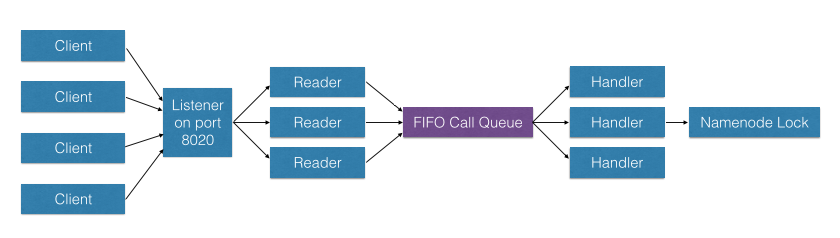
Though FIFO is fair in the sense of first-come-first-serve, it is unfair in the sense that users who perform more I/O operations on the namenode will be served more than users who perform less I/O. The result is the aforementioned latency increase.
We can see the effect of heavy users in the namenode auditlogs on days where we get support emails complaining about HDFS slowness:
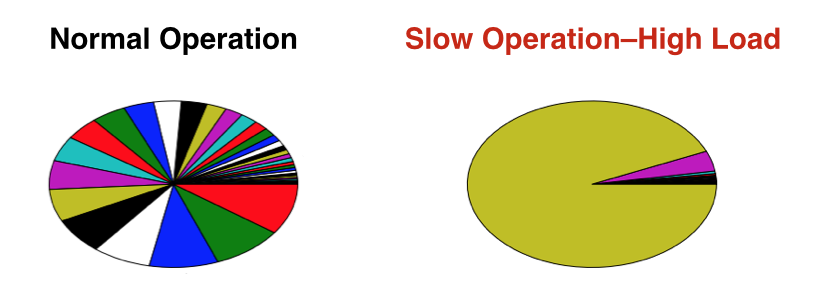
Each color is a different user, and the area indicates call volume. Single users monopolizing cluster resources are a frequent cause of slowdown. With only one namenode and thousands of datanodes, any poorly written MapReduce job is a potential distributed denial-of-service attack.
Solution: quality of service
Taking inspiration from routers—some of which include QoS (quality of service) capabilities—we replaced the FIFO queue with a new type of queue, which we call the FairCallQueue.

The scheduler places incoming RPC calls into a number of queues based on the call volume of the user who made the call. The scheduler keeps track of recent calls, and prioritizes calls from lighter users over calls from heavy users.
The multiplexer controls the penalty of being in a low-priority queue versus a high-priority queue. It reads calls in a weighted round-robin fashion, preferring to read from high-priority queues and infrequently reading from the lowest-priority queues. This ensures that high-priority requests are served first, and prevents starvation of low-priority RPCs.
The multiplexer and scheduler are connected by a multi-level queue; together, these three form the FairCallQueue. In our tests at scale, we’ve found the queue is effective at preserving low latencies even in the face of overwhelming denial-of-service attacks on the namenode.
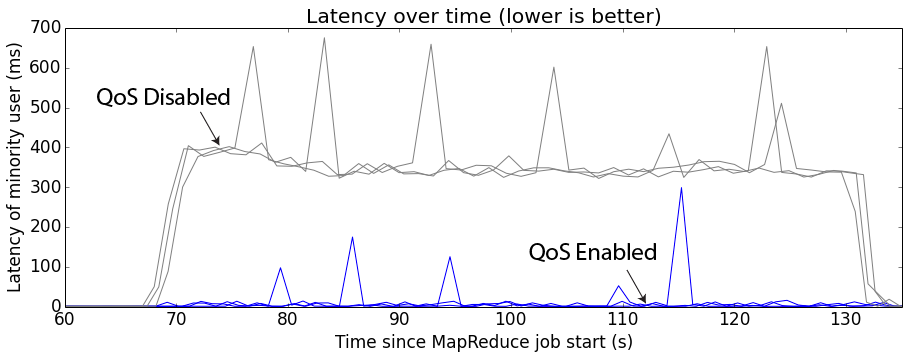
This plot shows the latency of a minority user during three runs of a FIFO queue (QoS disabled) and the FairCallQueue (QoS enabled). As expected, the latency is much lower when the FairCallQueue is active. (Note: spikes are caused by garbage collection pauses, which are a separate issue).
Open source and beyond
The 2.4 release of Apache Hadoop includes the prerequisites to namenode QoS. With this release, cluster owners can modify the implementation of the RPC call queue at runtime and choose to leverage the new FairCallQueue. You can try the patches on Apache’s JIRA: HADOOP-9640.
The FairCallQueue can be customized with other schedulers and multiplexers to enable new features. We are already investigating future improvements, such as weighting different RPC types for more intelligent scheduling and allowing users to manually control which queues certain users are scheduled into. In addition, there are features submitted from the open source community that build upon QoS, such as RPC client backoff and Fair Share queuing.
With namenode QoS in place, we have improved our users’ experience of our Hadoop clusters by providing faster and more uniform response times to well-behaved users while minimizing the impact of poorly written or badly behaved jobs. This in turn allows our analysts to be more productive and focus on the things that matter, like making your eBay experience a delightful one.
– Chris Li
eBay Global Data Infrastructure Analytics Team