Problem overview
Conventional on-demand Virtual Machine (VM) provisioning methods on a cloud platform can be time-consuming and error-prone, especially when we need to provision VMs in large numbers quickly.
The following list captures different issues that we often encounter while trying to provision a new VM instance on the fly:
- Insufficient availability of compute resources due to capacity constraints
- Desire to place VMs on different fault domains to avoid concentration of VM instances on the same rack
- Transient failures or delays in the service provider platform result in failure or an increase in time to provision a VM instance.
Elasticsearch-as-a-service, or Pronto, is a cloud-based platform that provides distributed, easy to scale, and fully managed Elasticsearch clusters. This platform uses the OpenStack-based Nova module to get different compute resources (VMs). Nova is designed to power massively scalable, on-demand, self-service access to compute resources. The Pronto platform is available across multiple data centers with a large number of managed VMs.
Typically, the time taken for provisioning a complete Elasticsearch cluster via Nova APIs is directly proportional to the largest time taken by the member node to be in a “ready to use” state (active state). Typically, provisioning a single node could take up to three minutes (95th Percentile) but can be up to 15 minutes in some cases. Therefore, in a fairly large size cluster, our platform would take a long time for complete provisioning. This greatly impacts our turnaround time to remediate production issues. In addition to provisioning time, it is time-consuming to validate new created VMs.
There are many critical applications that leverage our platform for their search use cases. Therefore, as a platform provider, we need high availability to ensure that in a case of catastrophic cluster event (such as a node or an infrastructure failure), We can quickly flex up our clusters in seconds. Node failures are also quite common in a cloud-centric world, and applications need to ensure that there is sufficient resiliency built in. To avoid over-provisioning nodes, remediation actions such as flex-up (adding a new node) should ideally be done in seconds for high availability.
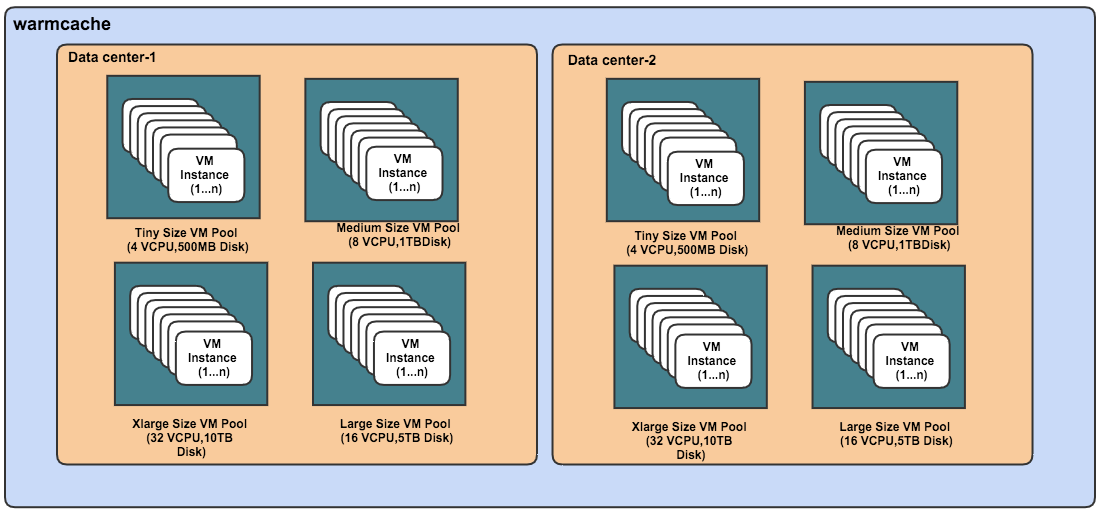
New hardware capacity is acquired as racks from external vendors. Each rack typically has two independent fault domains with minimal resource overlap (For example, different networks), and sometimes they don’t share a common power source. Each fault domain hosts many hypervisors, which are virtual machine managers. Standalone VMs are provisioned on such hypervisors. VMs can be of different sizes (tiny, medium, large, and so on). VMs on the same hypervisor can compete for disk and network I/O resources, and therefore can lead to noisy neighbor issues.

Nova provides ways to be fault domain- and hypervisor- aware. However, it is still difficult to successfully achieve guaranteed rack isolation during run-time provisioning of VM instances. For example, once we start provisioning VMs, there is no guarantee that we will successfully create VM instances on different racks. This depends entirely on the underlying available hardware at that point in time. Rack isolation is important to ensure high availability of Elasticsearch master nodes (cluster brain). Every master node in an Elasticsearch cluster must reside on a different rack for fault tolerance. (If a rack fails, at least some other master node in an another rack can take up active master role). Additionally, all data nodes of a given cluster must reside on different hypervisors for logical isolation. Our APIs must fail immediately when we cannot get VMs on different racks or hypervisors. A subsequent retry will not necessarily solve this problem.
Solution
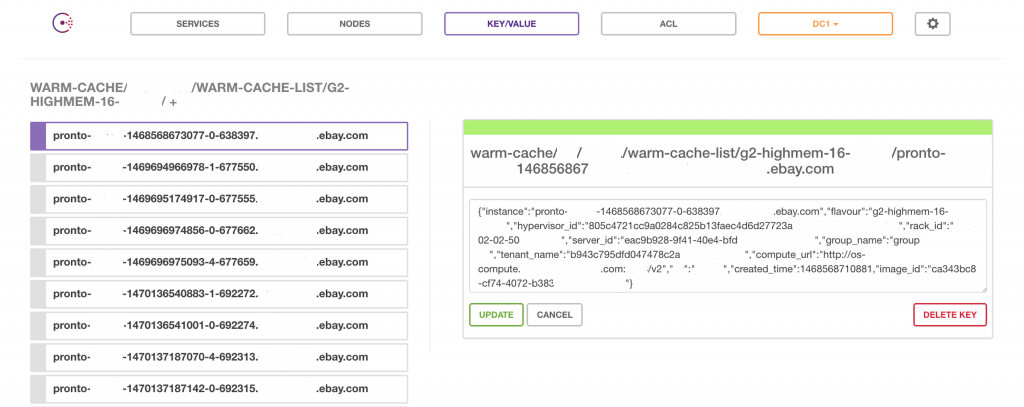
The warm-cache module intends to solve these issues by creating a cache pool of VM instances well ahead of actual provisioning needs. Many pre-baked VMs are created and loaded in a cache pool. These ready-to-use VMs cater to the cluster-provisioning needs of the Pronto platform. The cache is continuously built, and it can be continuously monitored via alerts and user-interface (UI) dashboards. Nodes are periodically polled for health status, and unhealthy nodes are auto-purged from the active cache. At any point, interfaces on warm-cache can help tune or influence future VM instance preparation.
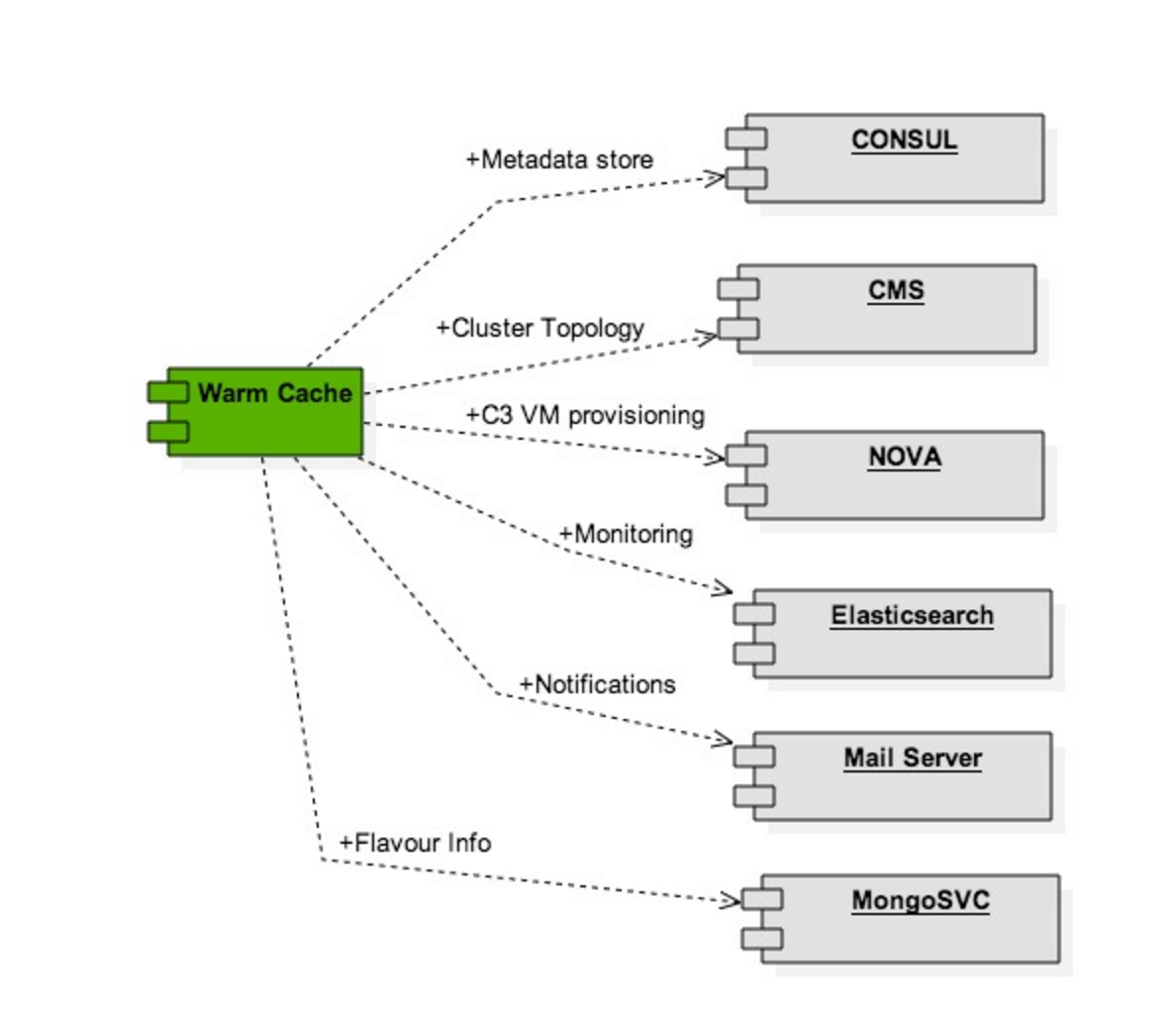
The warm-cache module leverages open source technologies like Consul, Elasticsearch, Kibana, Nova, and MongoDB for realizing its functionality.
Consul is an open-source distributed service discovery tool and key value store. Consul is completely distributed, highly available, and scalable to thousands of nodes and services across multiple data centers. Consul also provides distributed locking mechanisms with support for TTL (Time-to-live).
We use Consul as key-value (KV) store for these functions:
- Configuring VM build rules
- Storing VM flavor configuration metadata
- Leader election (via distributed locks)
- Persisting VM-provisioned information
The following snapshot shows a representative warm-cache KV store in Consul.

The following screenshot shows a sample Consul’s web UI.
Elasticsearch “is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements.” Apart from provisioning and managing Elasticsearch clusters for our customers, we ourselves use Elasticsearch clusters for our platform monitoring needs. This is a good way to validate our own platform offering. Elasticsearch backend is used for warm-cache module monitoring.
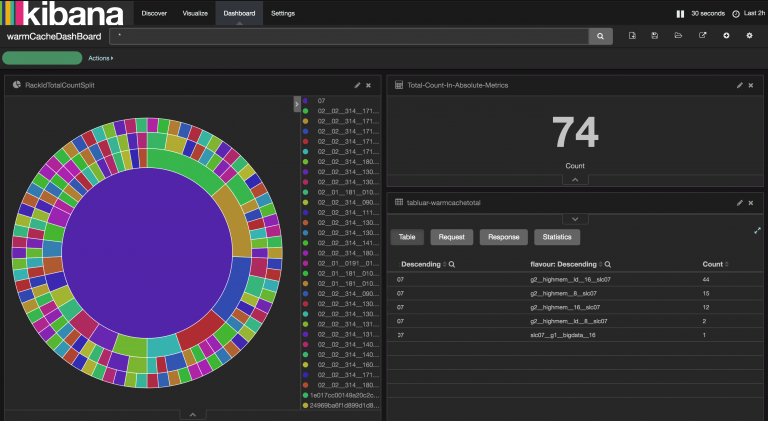
Kibana is “built on the power of Elasticsearch analytics capabilities to analyze your data intelligently, perform mathematical transformations, and slice and dice your data as you see fit.” We use Kibana to depict the entire warm-cache build history stored in Elasticsearch. This build history is rendered on Kibana dashboard with various views. The build history contains information such as how many instances were created and when were they created, how many errors had occurred, how much time was taken for provisioning, how many different Racks are available, and VM instance density on racks/hypervisors. warm-cache module can additionally send email notifications whenever the cache is built, updated, or affected by an error.
We use the Kibana dashboard to check active and ready-to-use VM instances of different flavors in a particular datacenter, as shown in the following figure.
MongoDB “is an open-source, document database designed for ease of development and scaling.” warm-cache uses this technology to store information about flavor details. Flavor corresponds to the actual VM-underlying hardware used. (They can be tiny, large, xlarge, etc.). Flavor details consist of sensitive information, such as image-id, flavour-id, which are required for actual Nova compute calls. warm-cache uses a Mongo service abstraction layer (MongoSvc) to interact with the backend MongoDB in a secure and protected manner. The exposed APIs on MongoSvc are authenticated and authorized via Keystone integration.
CMS (Configuration Management System) is a high-performance, metadata-driven persistence and query service for configuration data with support for RESTful API and client libraries (Java and Python). This system is internal to eBay, and it is used by warm-cache to get hardware information of various compute nodes (including rack and hypervisor info).
System Design
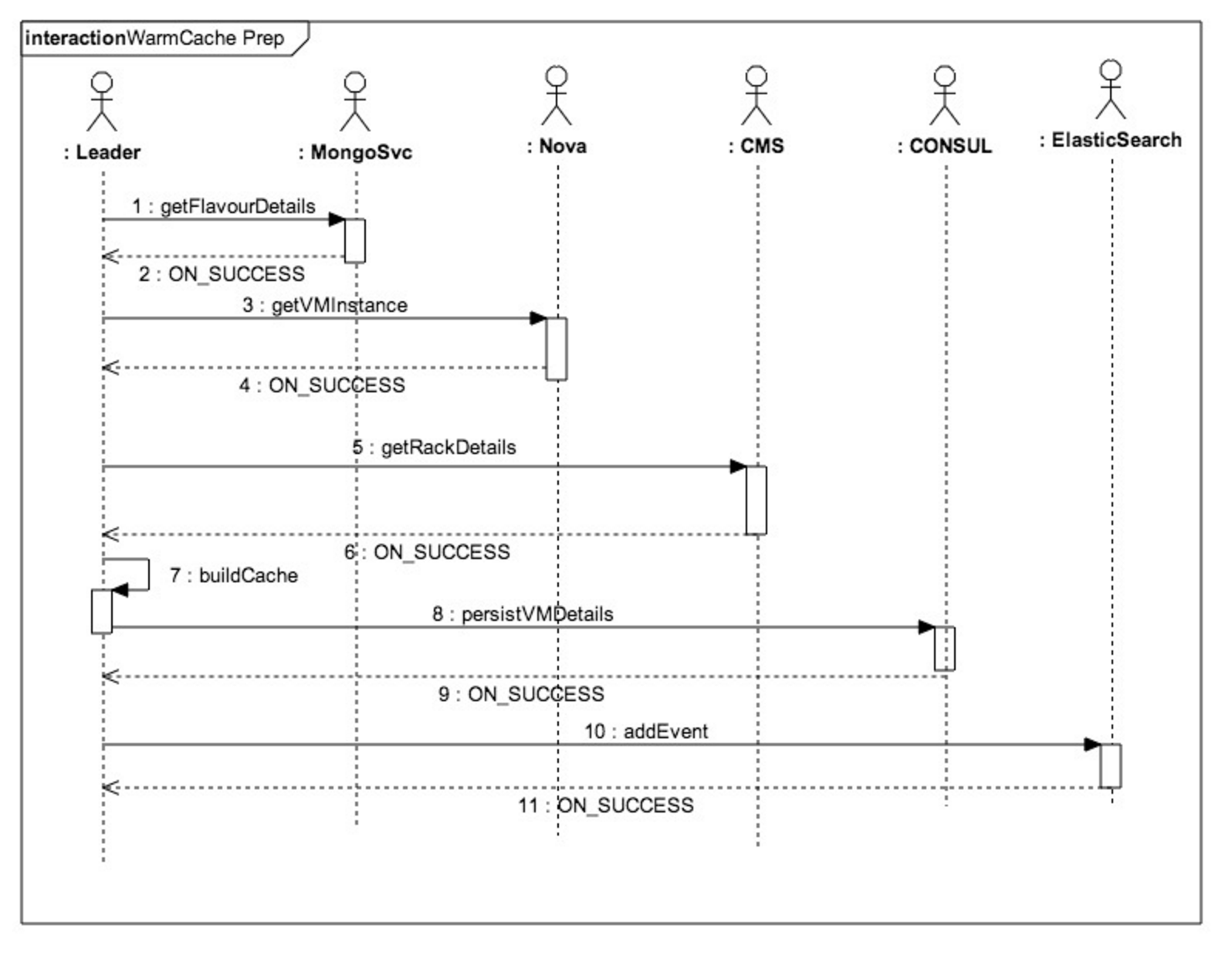
The warm-cache module is built as a pluggable library that can be integrated or bundled into any long running service or daemon process. On successful library initialization, a warm-cache instance handle is created. Optionally, a warm-cache instance can enroll for leader election participation. Leader instances are responsible for preparation of VM cache pools for different flavors. warm-cache will consist of all VM pools for every flavor across the different available data centers.
The following figure shows the system dependencies of warm-cache.
The warm-cache module is expected to bring down VM instance preparation time to few seconds. It should also remedy a lot of exceptions and errors that occur while VM instances get ready to a usable state, because these errors are handled well in advance of actual provisioning needs. Typical errors that are encountered today are nodes not available in Foreman due to sync issues and waiting for VM instances to get to the active state.
The figure below depicts the internal state diagram of the warm-cache service. This state flow is triggered on every warm-cache service deployed. Leader election is triggered at every 15-minute boundary interval (which is configurable). This election is done via Consul locks with an associated TTL (Time-to-live). After a leader instance is elected, that particular instance holds the leader lock and reads metadata from Consul for each Availability Zone (AZ, equivalent to a data center). These details include information such as how many minimum instances of each flavor are to be maintained by warm-cache. Leader instance spawns parallel tasks for each AZ and starts preparing the warm cache based on predefined rules. Preparation of a VM instance is marked as complete when the VM instance moves to an active state (for example, as directed by an open-stack Nova API response). All successfully created VM instances are persisted on an updated warm-cache list maintained on Consul. The leader instance releases the leader lock on the complete execution of its VM’s build rules and waits for next leader election cycle.
The configuration of each specific flavor (for example, g2-highmem-16-slc07) is persisted in Consul as build rules for that particular flavor. The following figure shows an example.

In above sample rule, the max_instance_per_cycle attribute indicates how many instances are to be created for this flavor in one leadership cycle. min_fault_domain is used for the Nova API to ensure that at least two nodes in a leader cycle go to different fault domains. reserve_cap specifies the number of instances that will be blocked and unavailable via warm-cache. user_data is the base64-encoded Bash script that a VM instance executes on first start-up. total_instances keeps track on total number of instances that need to be created for a particular flavor. An optional group_hint can be provided that ensures that no two instances with the same group-id are configured on the same hypervisor.
For every VM instance added to warm-cache, following information will be metadata is persisted on Consul:
- Instance Name
- Hypervisor ID
- Rack ID
- Server ID
- Group name (OS scheduler hint used)
- Created time

Since there are multiple instances of the warm-cache service deployed, only of them is elected leader to prepare the warm-cache during a time interval. This is necessary to avoid any conflicts among multiple warm-cache instances. Consul is again used for leader election. Each warm-cache service instance registers itself as a warm-cache service on Consul. This information is used to track available warm cache instances. The registration has a TTL (Time-To-Live) value (one hour) associated with it. Any deployed warm cache service is expected to re-register itself with the warm-cache service within the configured TTL value (one hour). Each of the registered warm-cache services on Consul to elect itself as a leader by making an attempt to acquire the leader lock on Consul. Once a warm-cache service acquires a lock, it acts as a leader for VM cache pool preparation. All other warm-cache service instances move to a stand-by mode during this time. There is a TTL associated with each leader lock to handle leader failures and to enable leader reelection.
In the following figure, leader is a Consul key that is managed by a distributed lock for the leadership role. The last leader node name and leader start timestamp are captured on this key. When a warm-cache service completes it functions in the leader role, this key is released for other prospective warm-cache service instances to become the new leader.

The leadership time-series graph depicts which node assumed the leadership role. The number 1 in the graph below indicates a leadership cycle.

When a leader has to provision a VM instance for a particular flavor, it first looks up for meta information for the flavor on MongoDB (via MongoSvc). This lookup provides details such as image-Id and flavor-Id. This information is used when creating the actual VM instance via NOVA APIs. Once a VM is created, its rack-id information is available via CMS. This information is stored in Consul associated with a Consul key $AZ/$INSTANCE, where $AZ is the Availability Zone and $INSTANCE is the actual instance name. This information is also then persisted on Elasticsearch for monitoring purpose.
The following figure shows a high-level system sequence diagram (SSD) of a leader role instance:
A Kibana dashboard can be used to check how VM instances in the cache pool are distributed across available racks. The following figure shows how many VM instances are provisioned on each rack. Using this information, Dev-ops can change the warm-cache build attributes to influence how the cache should be built in future.

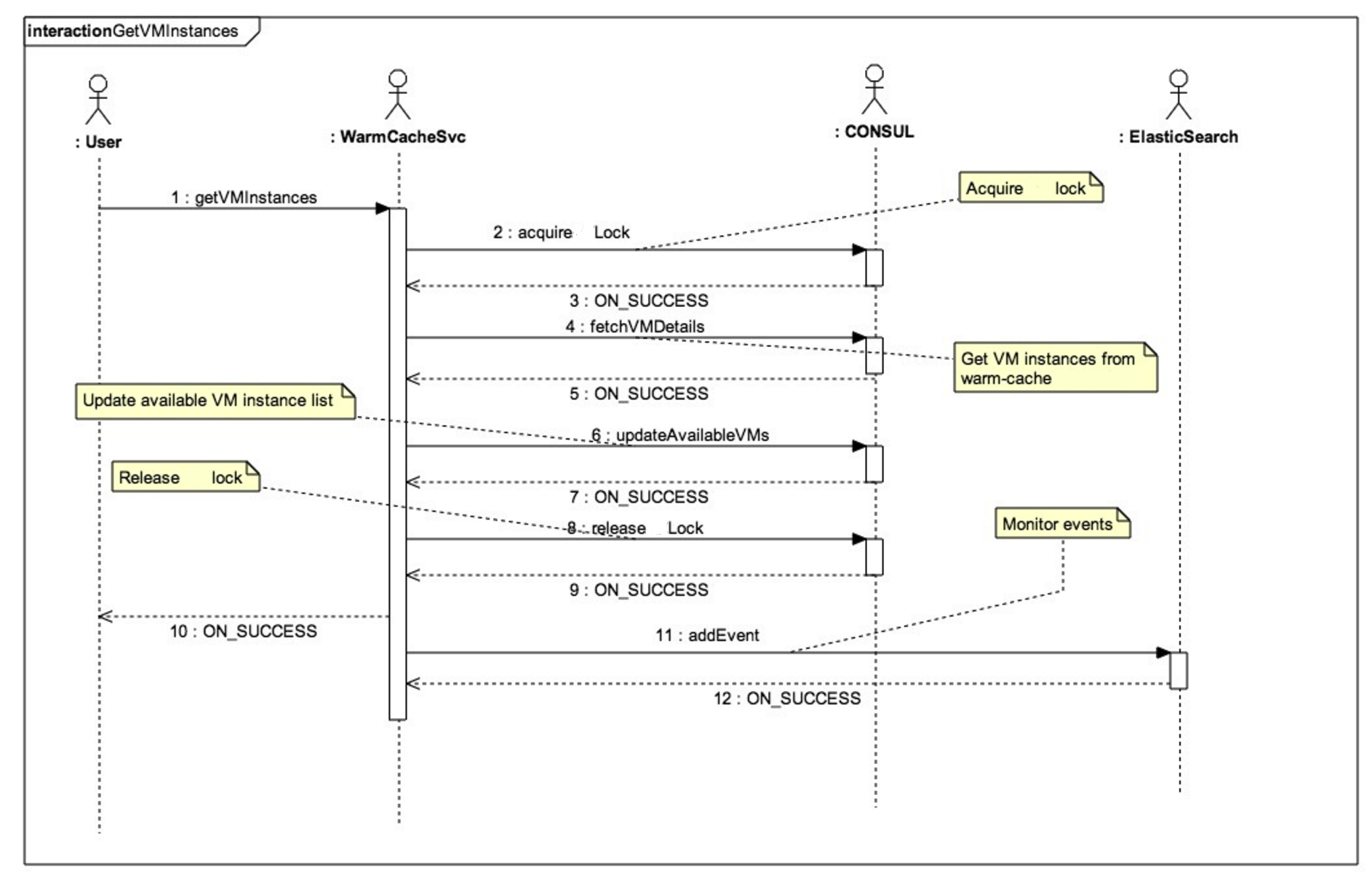
The following options are available for acquiring VM instances from the warm-cache pool:
- The Rack-aware mode option ensures that all nodes provided by warm-cache reside on different racks
- The Hypervisor-aware mode option returns nodes that reside on different hypervisors with no two nodes sharing a common hypervisor
- The Best-effort mode option tries to get nodes from mutually-exclusive hypervisors but does not guarantee it.
The following figure illustrates the process for acquiring a VM.
The following screen-shot includes a table from Kibana showing the time when an instance was removed from warm-cache, the instance’s flavor, data center information, and instance count.

The corresponding metadata information on Consul for acquired VM instances is updated and removed from the active warm-cache list.
Apart from our ability to quickly flex up, another huge advantage of the warm-cache technique compared to conventional run-time VM creation methods is that before an Elasticsearch cluster is provisioned, we know exactly if we have all the required non-error-prone VM nodes to satisfy to our capacity needs. There are many generic applications hosted on a cloud environment that require the ability to quickly flex up or to guarantee non-error-prone capacity for their application deployment needs. They can take a cue from the warm-cache approach for solving similar problems.