Complex systems can fail in many ways and I find it useful to divide failures into two classes. The first consists of failures that can be anticipated (e.g. disk failures), will happen again, and can be directly checked for. The second class is failures that are unexpected. This post is about that second class.
The tool for unexpected failures is statistics, hence the name for this post. A statistical anomaly detector hunts for things that seem off and then sends an alert. The power of statistical anomalies is that they can detect novel problems. The downside is that they must be followed up to track down the root cause. All this might seem abstract, but I will give a concrete example below.
To avoid confusion, I find it helps to carefully define some terminology:
- Monitored Signals: Results of continuous scans that look for trouble.
- Disruption: Behavior indicating that the site is not working as designed. A human will need to investigate to find the root cause.
- Anomaly: Unusual behavior in the monitored signals, suggesting a disruption.
- Alert: Automatic signal that an anomaly has occurred. It is common to send an alert after detecting an anomaly.
The obstacle to building useful statistical detectors is false positives: an alert that doesn’t correspond to a disruption. If the anomaly detector has too many false positives, users will turn off alerts or direct them to a spam folder or just generally ignore them. An ignored detector is not very useful.
In this post I will describe a statistical anomaly detector in use at eBay; my paper at the recent USENIX HotCloud 2015 workshop has more details. The monitored signals in our search system are based on the search results from a set of reference queries that are repeatedly issued. A statistical anomaly detector needs a way to encode the results of the monitoring as a set of numbers. We do this by computing metrics on the results. For each reference query, we compute about 50 metrics summarizing the items returned by the query. Two examples of metrics are the number of items returned and the median price of the returned items. There are 3000 reference queries and 50 metrics, therefore 150,000 numbers total. Currently, reference queries are issued every 4 hours, or 6 times a day, so there are 900,000 numbers per day. In these days of terabyte databases, this is very small. But the problem of sifting through those numbers to find anomalies, and do it with a low false-positive rate, is challenging.
I’ll outline our approach using diagrams, and refer you to my HotCloud paper for details. First, here is a picture of the monitored signals—that is, the metrics collected:
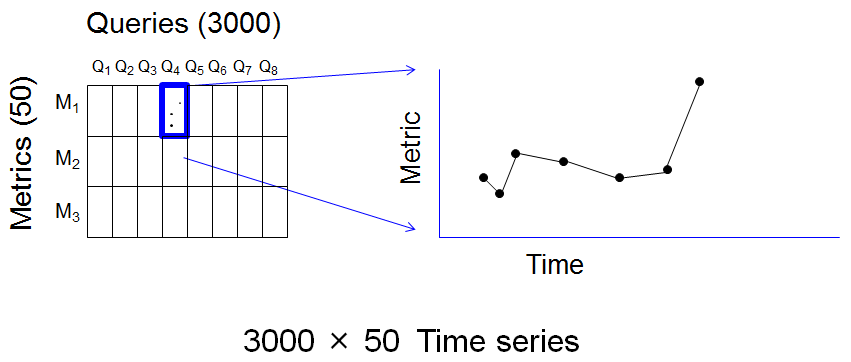
Each (query, metric) pair is a number that can be tracked over time, resulting in a time series. That’s 150,000 times series, and it’s reasonable to expect that during every 4-hour collection window, at least one of them will appear anomalous just by chance. So alerting on each time series is no good, because it will result in many false positives.
Our approach is to aggregate, and it starts with something very simple: examining each time series and computing the deviation between the most recent value and what you might have expected by extrapolating previous values. I call this the surprise, where the bigger the deviation the more the surprise. Here’s a figure illustrating that there is a surprise for each (query, metric, time) triple.
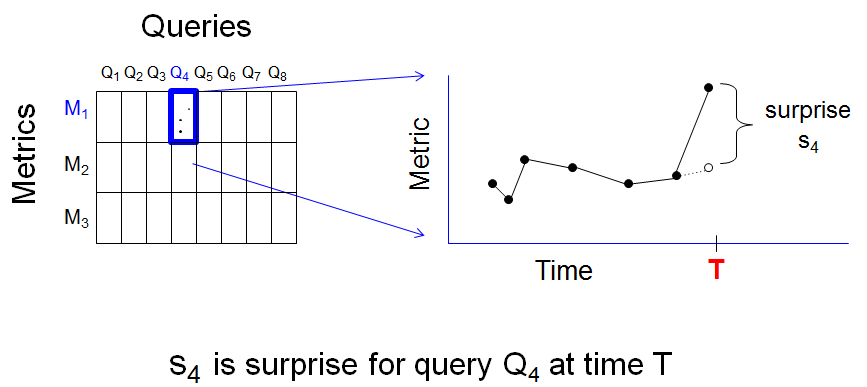
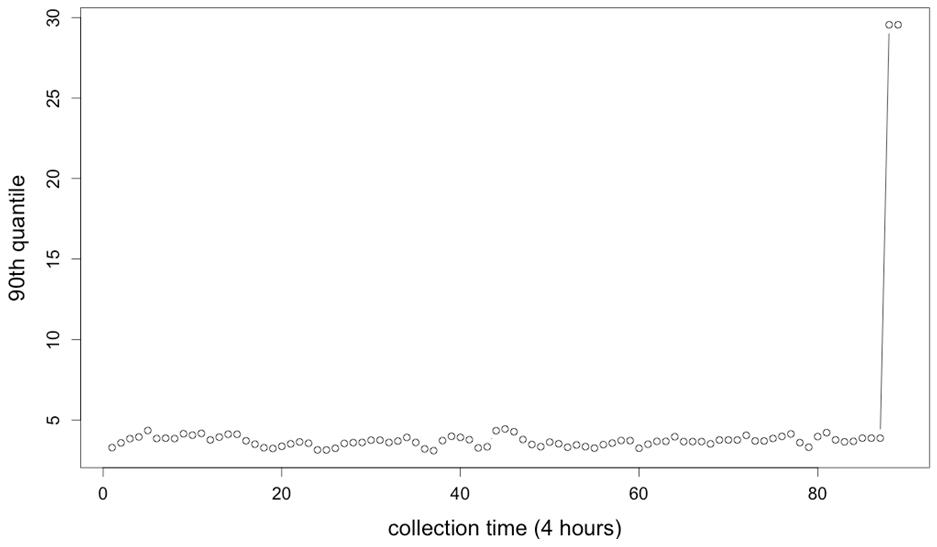
The idea for our anomaly detector is this: at each collection time T we expect a few (query,metric, T) triples to have a large surprise. We signal an alert if an unusually high number of triples have a large surprise. To make this idea quantitative, fix a metric, look at the surprise for all 3000 queries, and compute the 90th percentile of surprise at time T: S90(T).
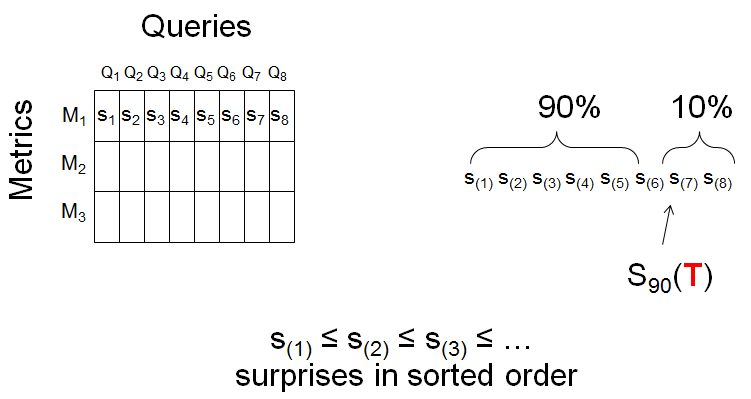
This gives a new time series in T, one for each metric. Hypothetical time series for the first two metrics are illustrated below.
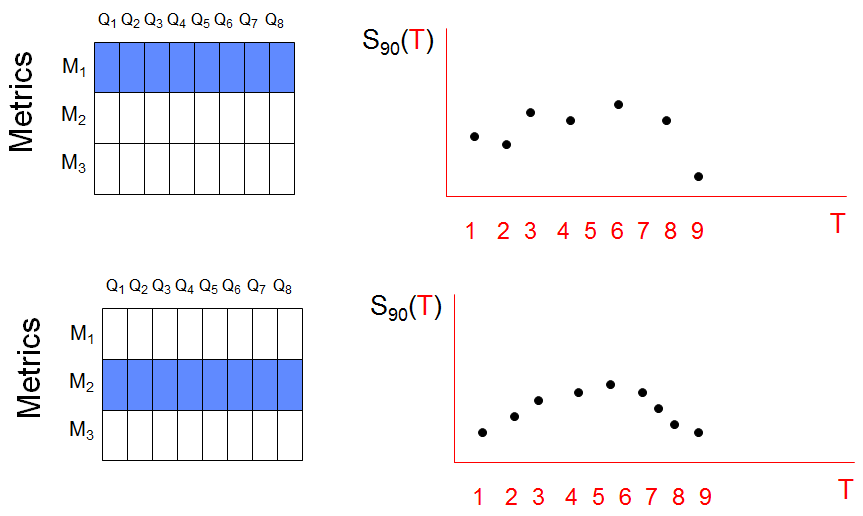
We’ve gone from 150,000 time series down to 50. Aggregation like this is a very useful technique in anomaly detection.
Our final anomaly detector uses a simple test on this aggregated time series. We define an anomaly to occur when the current value of any of the 50 series is more than 3σ from the median of that series. Here’s an example using eBay data with the metric median sale price. There is clearly an anomaly at time T=88.
For more details, see my previously cited HotCloud paper, The Importance of Features for Statistical Anomaly Detection.