At eBay we want our customers to have the best experience possible. We use data analytics to improve user experiences, provide relevant offers, optimize performance, and create many, many other kinds of value. One way eBay supports this value creation is by utilizing data processing frameworks that enable, accelerate, or simplify data analytics. One such framework is Apache Spark. This post describes how Apache Spark fits into eBay’s Analytic Data Infrastructure.
![]()
What is Apache Spark?
The Apache Spark web site describes Spark as “a fast and general engine for large-scale data processing.” Spark is a framework that enables parallel, distributed data processing. It offers a simple programming abstraction that provides powerful cache and persistence capabilities. The Spark framework can be deployed through Apache Mesos, Apache Hadoop via Yarn, or Spark’s own cluster manager. Developers can use the Spark framework via several programming languages including Java, Scala, and Python. Spark also serves as a foundation for additional data processing frameworks such as Shark, which provides SQL functionality for Hadoop.
Spark is an excellent tool for iterative processing of large datasets. One way Spark is suited for this type of processing is through its Resilient Distributed Dataset (RDD). In the paper titled Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing, RDDs are described as “…fault-tolerant, parallel data structures that let users explicitly persist intermediate results in memory, control their partitioning to optimize data placement, and manipulate them using a rich set of operators.” By using RDDs, programmers can pin their large data sets to memory, thereby supporting high-performance, iterative processing. Compared to reading a large data set from disk for every processing iteration, the in-memory solution is obviously much faster.
The diagram below shows a simple example of using Spark to read input data from HDFS, perform a series of iterative operations against that data using RDDs, and write the subsequent output back to HDFS.
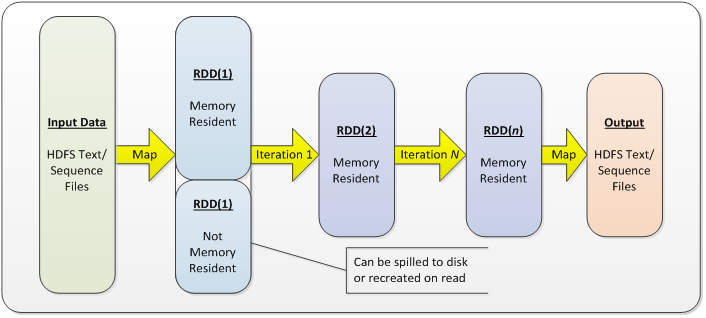
In the case of the first map operation into RDD(1), not all of the data could fit within the memory space allowed for RDDs. In such a case, the programmer is able to specify what should happen to the data that doesn’t fit. The options include spilling the computed data to disk and recreating it upon read. We can see in this example how each processing iteration is able to leverage memory for the reading and writing of its data. This method of leveraging memory is likely to be 100X faster than other methods that rely purely on disk storage for intermittent results.
Apache Spark at eBay
Today Spark is most commonly leveraged at eBay through Hadoop via Yarn. Yarn manages the Hadoop cluster’s resources and allows Hadoop to extend beyond traditional map and reduce jobs by employing Yarn containers to run generic tasks. Through the Hadoop Yarn framework, eBay’s Spark users are able to leverage clusters approaching the range of 2000 nodes, 100TB of RAM, and 20,000 cores.
The following example illustrates Spark on Hadoop via Yarn.
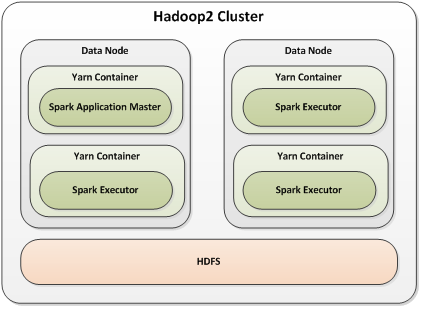
The user submits the Spark job to Hadoop. The Spark application master starts within a single Yarn container, then begins working with the Yarn resource manager to spawn Spark executors – as many as the user requested. These Spark executors will run the Spark application using the specified amount of memory and number of CPU cores. In this case, the Spark application is able to read and write to the cluster’s data residing in HDFS. This model of running Spark on Hadoop illustrates Hadoop’s growing ability to provide a singular, foundational platform for data processing over shared data.
The eBay analyst community includes a strong contingent of Scala users. Accordingly, many of eBay’s Spark users are writing their jobs in Scala. These jobs are supporting discovery through interrogation of complex data, data modelling, and data scoring, among other use cases. Below is a code snippet from a Spark Scala application. This application uses Spark’s machine learning library, MLlib, to cluster eBay’s sellers via KMeans. The seller attribute data is stored in HDFS.
|
In addition to Spark Scala users, several folks at eBay have begun using Spark with Shark to accelerate their Hadoop SQL performance. Many of these Shark queries are easily running 5X faster than their Hive counterparts. While Spark at eBay is still in its early stages, usage is in the midst of expanding from experimental to everyday as the number of Spark users at eBay continues to accelerate.
The Future of Spark at eBay
Spark is helping eBay create value from its data, and so the future is bright for Spark at eBay. Our Hadoop platform team has started gearing up to formally support Spark on Hadoop. Additionally, we’re keeping our eyes on how Hadoop continues to evolve in its support for frameworks like Spark, how the community is able to use Spark to create value from data, and how companies like Hortonworks and Cloudera are incorporating Spark into their portfolios. Some groups within eBay are looking at spinning up their own Spark clusters outside of Hadoop. These clusters would either leverage more specialized hardware or be application-specific. Other folks are working on incorporating eBay’s already strong data platform language extensions into the Spark model to make it even easier to leverage eBay’s data within Spark. In the meantime, we will continue to see adoption of Spark increase at eBay. This adoption will be driven by chats in the hall, newsletter blurbs, product announcements, industry chatter, and Spark’s own strengths and capabilities.
Editor's Note: The eBay Global Data Infrastructure Analytics Team contributed to this article.