Intern Pralay Biswas submitted the following blog post at the conclusion of his summer with eBay. Pralay was one of 120 college interns welcomed into eBay Marketplaces this summer.
In pioneer days, they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers. — Admiral Grace Hopper (1906-1992)
Like any company where data is of primary importance, eBay needed a scalable way to store and analyze data to help shape the company’s future, formulate strategies, and comprehend customer pain points in a much better way. eBay began its Hadoop journey in 2007 — and yes, eBay has come a long way since then.
I spent the summer of 2012 with eBay’s core Hadoop Platform team, working on quality engineering. Part of eBay’s central Marketplaces business, this team is where eBay manages the shared clusters, augments public-domain Hadoop software, and validates each release of Hadoop at eBay.
The problem
- How do we validate each new Hadoop release?
- How do we test the software to decrease the probability that we are shipping bugs?
- What about cluster-wide, end-to-end tests and integration tests?
- How do we make sure there are no quality regressions?
These are difficult questions to answer, especially when it comes to Hadoop.
No silver bullet for Hadoop testing
Existing software solutions from the Apache community that orchestrate and automate Hadoop testing and validation are insufficient. JUnit and PyUnit are great for small, self-contained developer (unit) tests. AspectJ works fine for local, single-module fault injection tests. Herriot is also based on JUnit and has some badly designed, buggy extensions. EclEmma is IDE-specific, and inappropriate.
Long story short: there is no existing framework or test harness that can validate a Hadoop platform release. Quick and automatic validation with minimal human intervention (ideally, zero-touch) is of primary importance to any company that needs to test with large-scale, mission-critical data. The quicker we store and analyze data, the quicker we understand our progress and ensure that we can roll out new software or configurations.
Engineer Arun Ramani developed the eBay Hadoop test framework. I was hired as a graduate summer intern to add tests to the framework that he conceived. In the following sections, I’ll elaborate on the test harness (as opposed to the tests that I wrote).
Architecture of the framework
The architecture of the test harness follows the model-view-controller (MVC) design pattern. The framework separates test cases from the test logic, so that the logic can remain almost unchanged; most changes can be made in the test XML only. The driver in the figure below is a Perl script that uses support modules (some more Perl modules) to prepare the test environment, and then pulls in the tests themselves, which reside in an XML file.
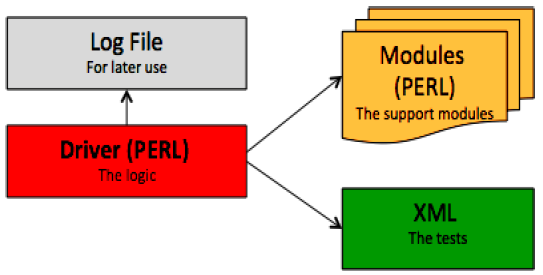
The main driver module acts as an orchestrator, and the support modules help determine the environment configuration; they restart daemons (name node, secondary name node, data node, job tracker, task tracker), send email reports of results, look for anomalous and correct exit conditions of processes, etc. The actual tests are in the XML file only. The driver parses these tests, executes them, and checks whether a test passed. Determination of a test’s pass/fail status can be achieved using Perl extended regular-expression comparisons of standard out, standard error, process termination, exit signals, log file data, or other system-level information. The use of Perl affords extraordinary visibility into end-to-end system-level test results (memory, cpu, signals, exit codes, stdout, stderr, and log files).
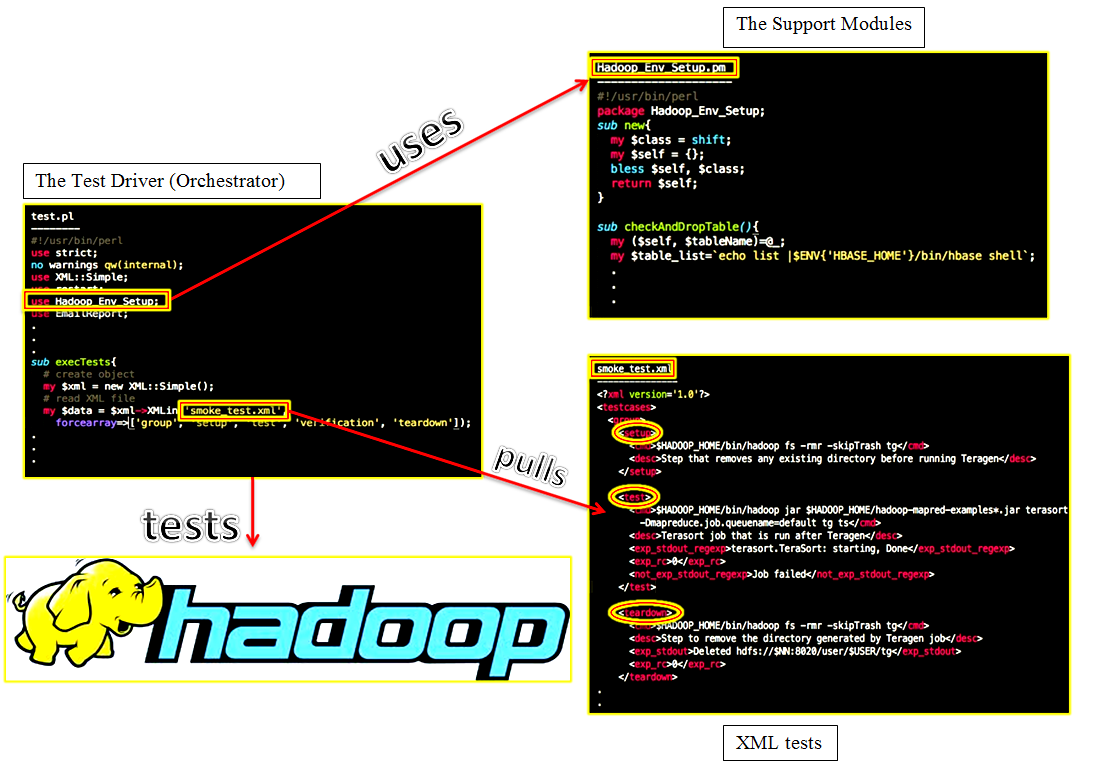
All tests are grouped according to uses cases. Tests within group tags represent one use case. Every use case (group) has a setup action and a teardown action containing commands to be executed for the purposes of those individual tests. All commands to be executed go between cmd tags, and desc tags enclose test and command descriptions.
Test case example
Take, for example, the following test case, which runs a Pi calculation job on the Hadoop cluster. The setup action prepares the environment required by the subsequent test — in this case, executing a command that deletes any existing directories so that the job can create new ones. The cmd tag would typically enclose a Hadoop command. However, this is not a restriction; the command could be a UNIX command line, a Java command to execute any jar, a shell script, another Perl script, or any arbitrary command. This flexibility enables the test framework to support tests not only for MapReduce and HDFS but for the entire Hadoop ecosystem.
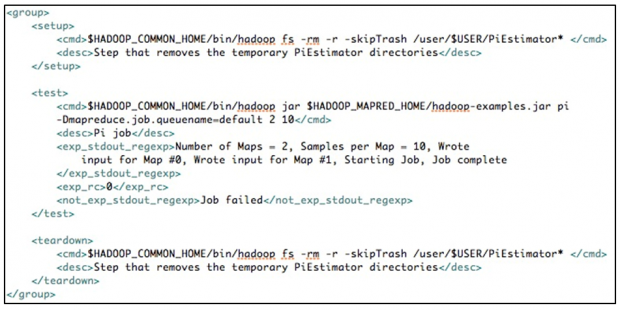
When the test driver executes the command, it stores results in the variable $actual_out. The driver then compares this value to that of the exp_stdout variable specified in the test case; this is a regular expression comparison. The driver also checks that $actual_out has nothing in common with not_exp_stdout_regexp. Furthermore, the return code of the executed command (the Hadoop job) is compared against the expected return code (exp_rc). A strict test driver declares success of a test only if all the checks and assertions are positive.
Once all tests in a group are run, the commands in the teardown phase clean up any data or state that the tests created (in HDFS, HBase, or memory) during their run, leaving the cluster clean for the next test case. Once the end of the XML test file is reached, the driver calculates the total number of cases (groups) executed, passed, and failed, then sends this log to the configured email IDs.
Automation and results
This test framework is kicked off as a Jenkins job that the Hadoop deployment job runs. So, as soon as a new release is deployed and compiled on the QA cluster, this framework runs automatically to validate that the new bits are good. Modular and flexible, the framework has been used successfully to validate Cloudera’s CDH4 and Apache Hadoop 0.22. Going forward, this framework will validate all future releases of Hadoop at eBay.
