Life is about carefully calculating daily necessities and the same is true for technology. Frugal people spend money on things that are needed most, while programmers are always seeking to reduce the resources cost of their code. Cube Planner is a new feature created by eBay’s programmers that helps you spend resources on building cost-effective dimension combinations.
Background
Apache Kylin is an open source Distributed Analytics Engine designed to provide multi-dimensional analysis (OLAP) on Hadoop, originally contributed from eBay to the Apache Software Foundation in 2014. Kylin became a Apache top-level project in 2015. With the rapid development of the Apache Kylin community since 2015, Apche Kylin has been deployed by many companies worldwide.
There has also been a crescendo of data analysis applications deployed on the Apache Kylin platform within eBay. There are currently 144 cubes in the production environment of eBay, and this number continues to grow on an average of 10 per month. The largest cube is about 100T. The average query amount is between 40,000 and 50,000 per week day. During last month, the average query latency is 0.49 seconds.
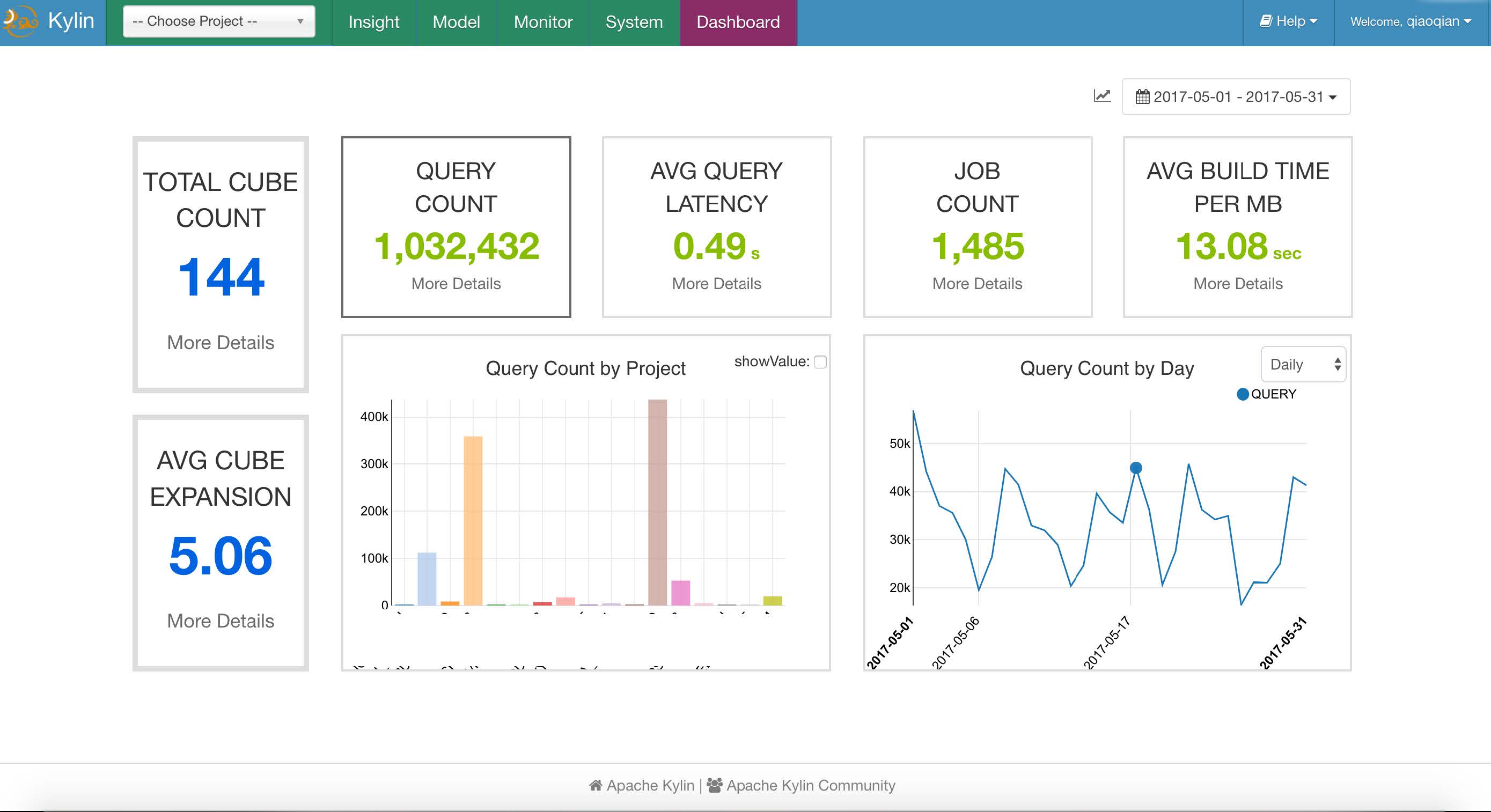
Why is Cube Planner needed
In 2016, eBay Data Services and Solutions (DSS) department began to introduce self-service reports. Data analysts are able to drag and drop dimensions and measures to create their own reports. But the self-service report generally has many dimensions, measures, and it is difficult to define the query pattern, which requires Kylin to pre-calculate a large amount of dimension combinations.
In addition, in companies that reach a certain scale, data providers and data users don’t belong to the same department, and data providers may not be particularly familiar to the query pattern, which leads to a gap between the capability of cube design and actual use. Some combinations of dimensions are pre-calculated, but are not queried, while some are often queried, but are not pre-calculated. These gaps have effect on the resource utilization and query performance of a cube.
We decided to make a cube build planner, Cube Planner, with the goal of efficiently using computing and storage resources to build cost-effective dimension combinations intelligently.
What is Cube Planner?
Cube Planner checks the costs and benefits of each dimension combination, and selects cost-effective dimension combination sets to improve cube build efficiency and query performance. The Cube Planner recommendation algorithm can be run multiple times throughout the life cycle of the cube. For example, after the cube is created for the first time, or after a certain amount of query statistics is collected, the cube is periodically optimized.
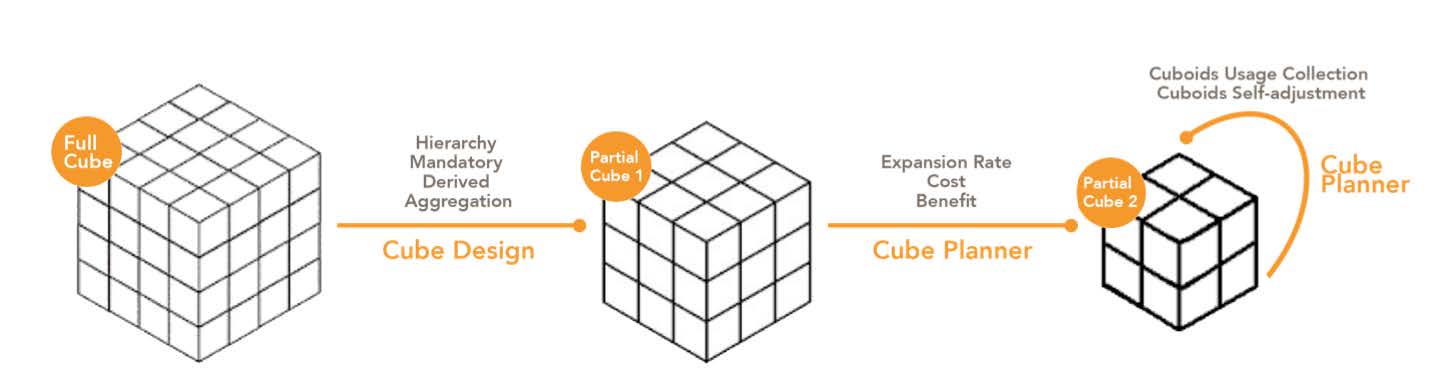
Definitions and Formulas
Here are some definitions and formulas used in the Cube Planner algorithm.
- Dimensions and Measures are the basic concepts of data warehousing.
- A dimension combination (Cuboid) refers to any combination of multiple dimensions of the data. Suppose the data has three dimensions (time, location, category), then it has eight kinds of dimension combinations: [ ], [time], [location], [category], [time, location], [time, category], [location, category], [time, location, category].
- The basic dimension combination (Basic Cuboid) is a combination of all dimensions, with the most detailed aggregation information, such as the combination of the dimensions above [time, place, category].
- The symbol≼ represents a parent-child relationship between dimension combinations,
- w ≼ i, indicates that a query involving dimension combination w can be aggregated from the data of the dimension combination i, the combination w is a child combination, and the combination i is the parent combination. For example, dimension combination w [time, category] and dimension combination i [time, location, category]. Each parent combination may have multiple child combinations, and the basic dimension combination is the parent of all other dimension combinations.
- Costs of a dimension combination
- The costs of a dimension combination is divided into two aspects. One is the build cost, which is defined by the number of rows of data combined by itself, and the other is the query cost, which is defined by the number of rows scanned by the query. Since the build is often one-time while the query is repetitive, we ignore the build cost and only use the query cost to calculate the cost of a dimension combination. C(i) = Cost of dimension combination(i).
- Benefits of dimension combination
- The benefits of a dimension combination can be understood as reduced costs, that is, the cost of all queries on this cube that can be reduced by pre-calculating this dimension combination.B(i, S) refers to the benefit of creating a dimension combination (i) in the dimension combination set S, calculated by summing up the benefits of all the subsets of i:B(i,S) = ∑w≼i Bw
- Among the set, the benefit of each subset Bw=max{ C(w) – C(i) ,0}
- Benefit ratio of dimension combination
- Dimension combination benefit ratio = (cost of the dimension combination/benefit of dimension combination) * 100%:
- Br(i, S) = (B(i, S) / C(i)) * 100%
How to choose a cost-effective dimension combination?
We use greedy algorithms to choose a cost-effective dimension combination, and the process of selection is iterative. For each iteration, the system will go through the candidate set, select a dimension combination with the highest benefit ratios at the current state, and add it to the combination result set that needs to be built.
Let’s now look at a simple example to understand the process of the iterative selection.
Cube Planner Select a dimension combination process example
Let’s assume there is a cube that has the following dimension combination.
| Dimension Combination ID | Dimension |
|---|---|
| a | time, place, category |
| b | time, place |
| c | time, category |
| … | … |
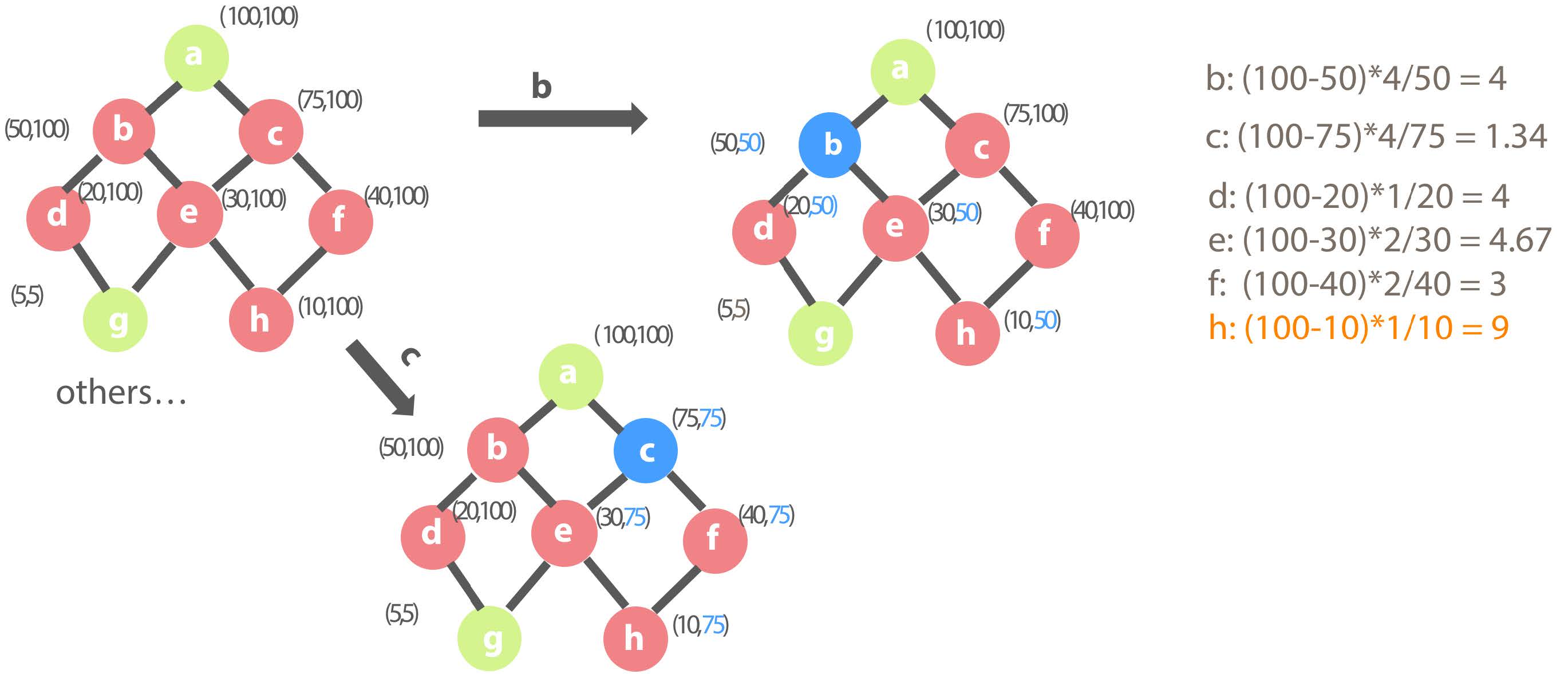
The parent-child relationship between each dimension combination is shown in the following figure. Each dimension combination has a set of numbers (i, j) in addition to ID.
i: the number of rows in this dimension combination
j: the cost of querying the dimension combination
In the following figure, dimension combination a is the basic dimension combination (Basic Cuboid), and the data has 100 rows. In the Kylin cube, the basic dimension combination will be pre-calculated by default. Initially, the result set starts with only the basic dimension combination. Therefore, queries on other dimension combinations need to answered by scanning the basic dimension combination data then doing the aggregation, so the cost of these queries is the number of rows, 100.
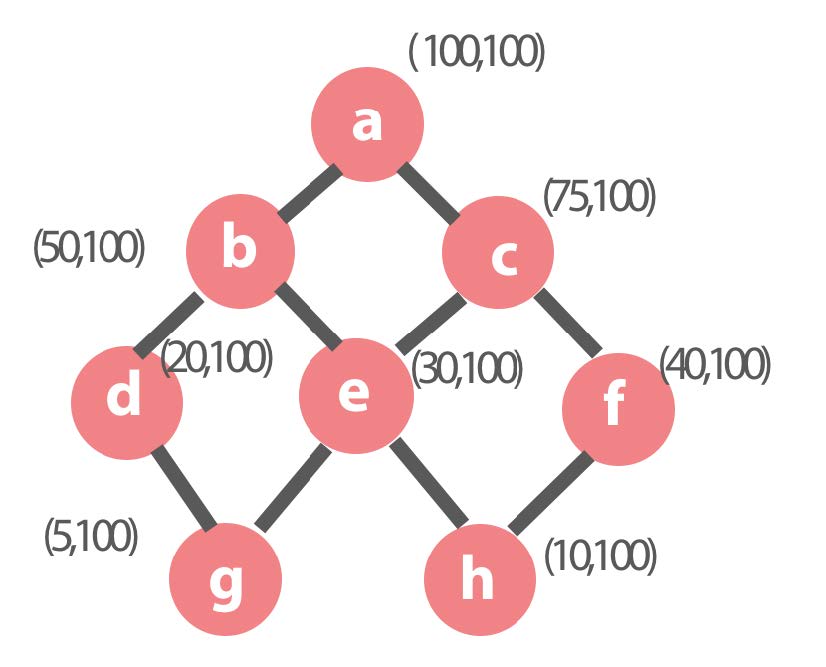
First iteration of Cube Planner greedy algorithm
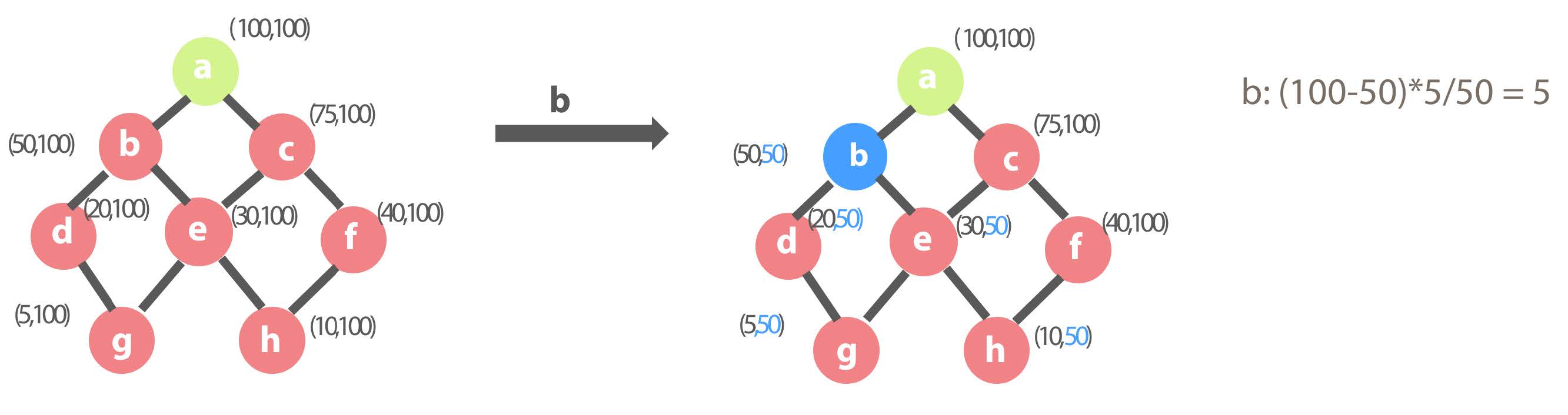
The green dimension combinations are the combinations that have been selected into the result set during the previous rounds, initially with only the basic dimension combination. The red ones are the combinations that may be selected into the result set during the this round. The blue ones indicate that these combinations are selected and will be added to the result set during this round.
What is the benefit of selecting dimension combination b, that is, the reduced cost of the entire cube? If b is selected, the cost of b and its children (d, e, g, h) will be reduced from 100 to 50, so that the benefit ratio of the dimension combination b is (100 – 50) * 5 / 50 = 5.
If you choose the dimension combination C, the benefit ratio is 1.67.
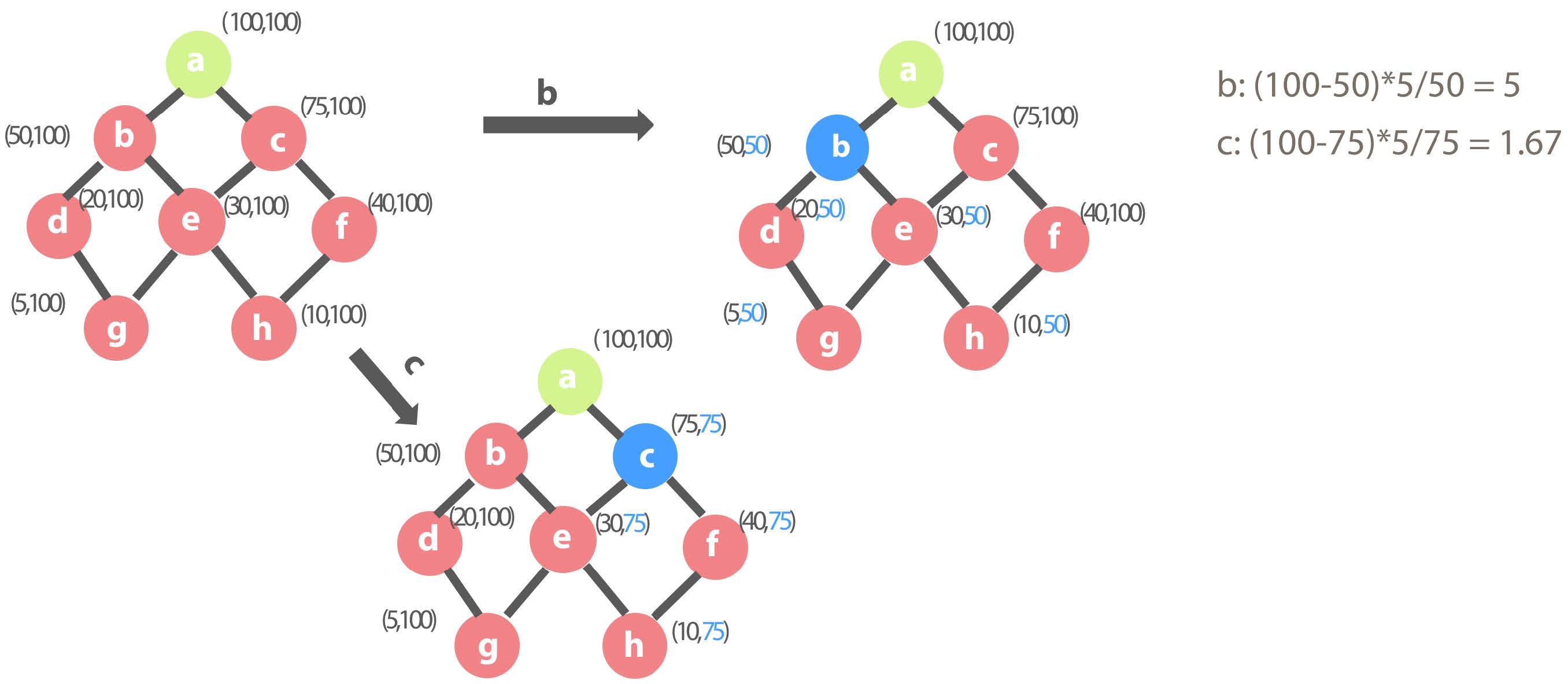
If other dimension combinations are selected, the benefit ratio is as follows. It is obvious that g is a combination with the highest benefit ratio, so dimension combination g is added to the result set during this round.
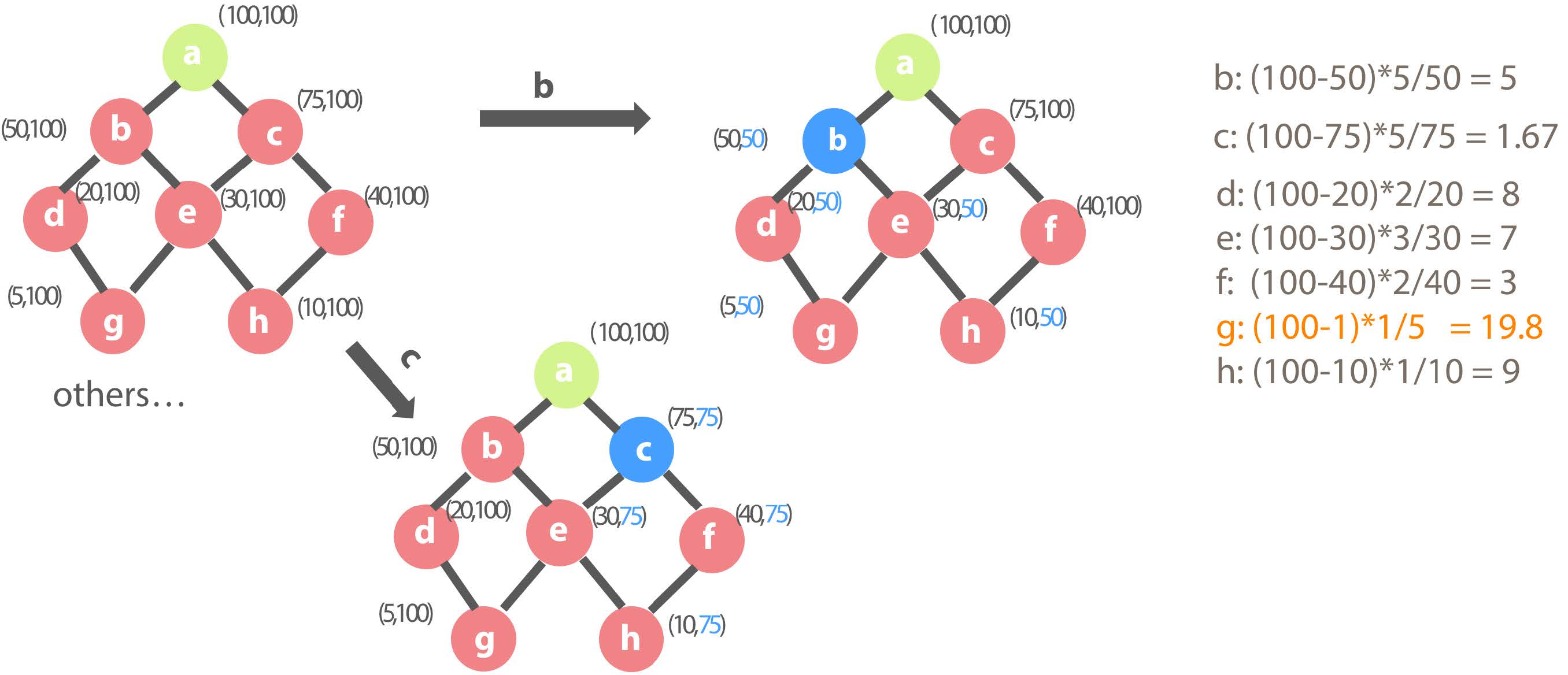
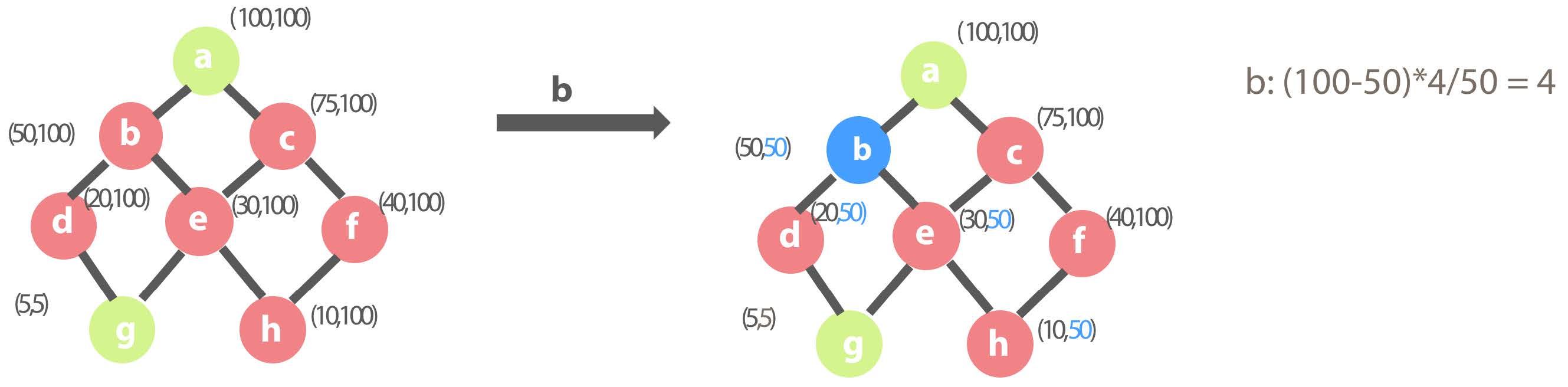
Second round selection of the Cube Planner
At this point, the result set has become (a, g). At this state, if b is selected, although the children of b are d, e, g and h, only query over b, d and e will be effected because g has been pre-calculated and g has fewer row counts than b. When the query against dimension combination g arrives, the system will still choose g to answer the query. This is exactly why the benefit of each child combinations mentioned above is Bw=max{ QC(w) – QC(i) ,0}. So, the benefit ratio of combination b is 4.
If you pick the combination c, the benefit ratio is 1.34.
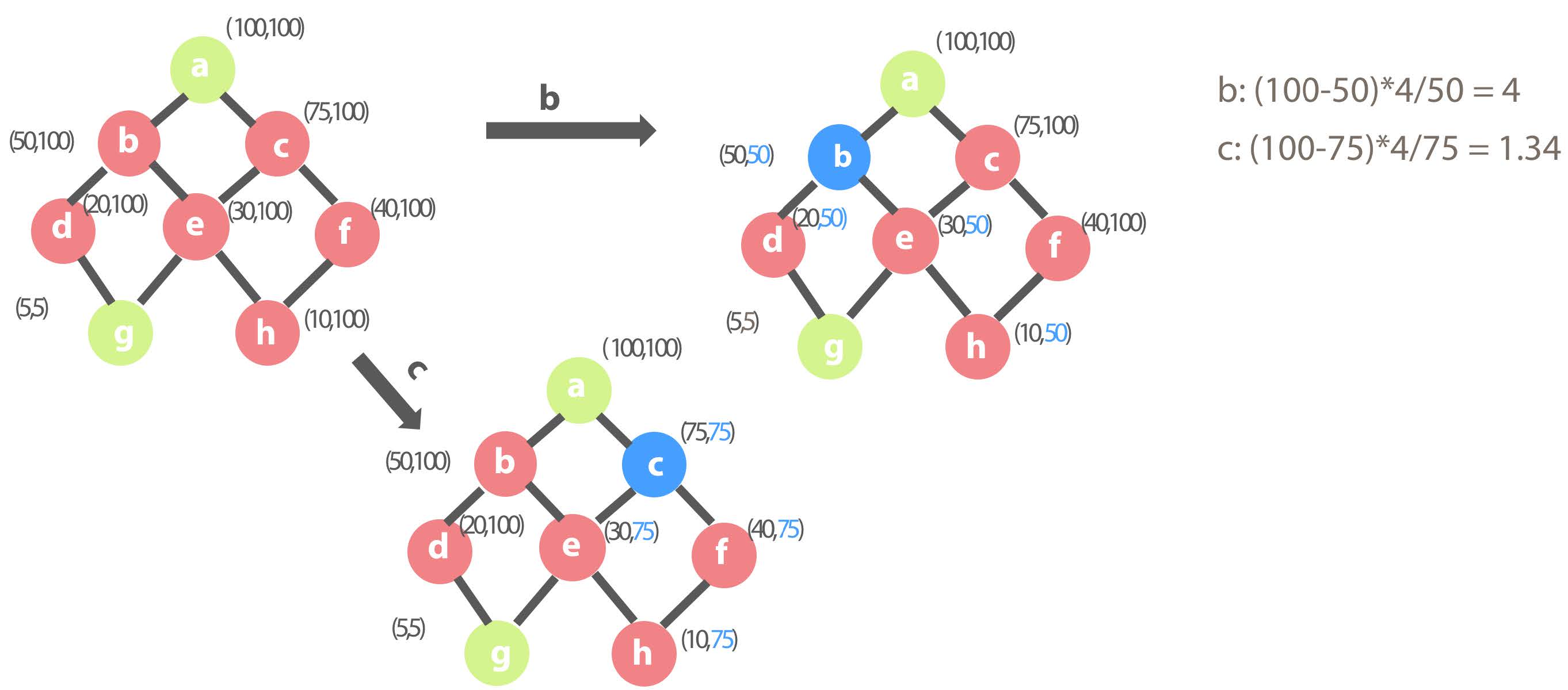
The benefit of other combinations is as follows. Combination h is selected eventually and is added to the result set during this round.
When do we stop the iteration selection?
When any one of the following three conditions is fulfilled, the system will stop the selection:
- The expansion rate of combination dimensions in the result set reaches the established expansion rate of the cube.
- The efficiency ratio of the selected dimension combination this round is lower than the established minimum value. This indicates that the newly added dimension is not cost-effective, so there is no need to select more dimension combinations.
- The run time of the selection algorithm reaches the established ceiling.
A Cube Planner algorithm based on weighted query statistics
In the previous algorithm, the benefit weights of other dimension combinations are the same when calculating the benefit that one dimension combination will bring for the entire cube. But in the actual application, the probability of querying dimension combination varies. Therefore, when calculating the benefit, we use the probability of querying as the weight of each dimension combination.
Weighted dimension combination benefit WB(i,S) = ∑w≼i (Bw * Pw)
Pw is the probability of querying this dimension combination. As for those dimension combinations that are not queried, we set the probability to a small non-zero value to avoid overfitting.
As for the newly created cube, the probability is set to the same because there are no query statistics in the system. There is room for improvement. We want to use the platform-level statistics data and some data-mining algorithms to estimate the probability of the querying dimension combinations of the new cube in the future. For the cubes that are already online, we collect the query statistics, and it is easy to calculate the probability of querying each dimension combination.
In fact, the real algorithm based on weighted query statistics is more complex than this. Many practical problems need to be solved, for example, how to estimate the cost of a dimension combination that is not pre-calculated, because Kylin only stores statistics of the pre-calculated dimension combinations.
Greedy algorithm VS Genetic algorithm
Greedy algorithms have some limitations when there are too many dimensions. Because the candidate dimension combination set is very large, the algorithm needs to go through each dimension combination, so it takes some time to run. Thus, we implemented a genetic algorithm as an alternative. Using the iterative and evolutionary model of the gene to simulate the selection of the dimension combination set, the optimal combination set of dimensions is finally evolved (selected) through a number of iterations. There is no refinement. If anyone is interested, we can write a detailed description of the genetic algorithm used in Cube Planner.
Cube Planner one-click optimization
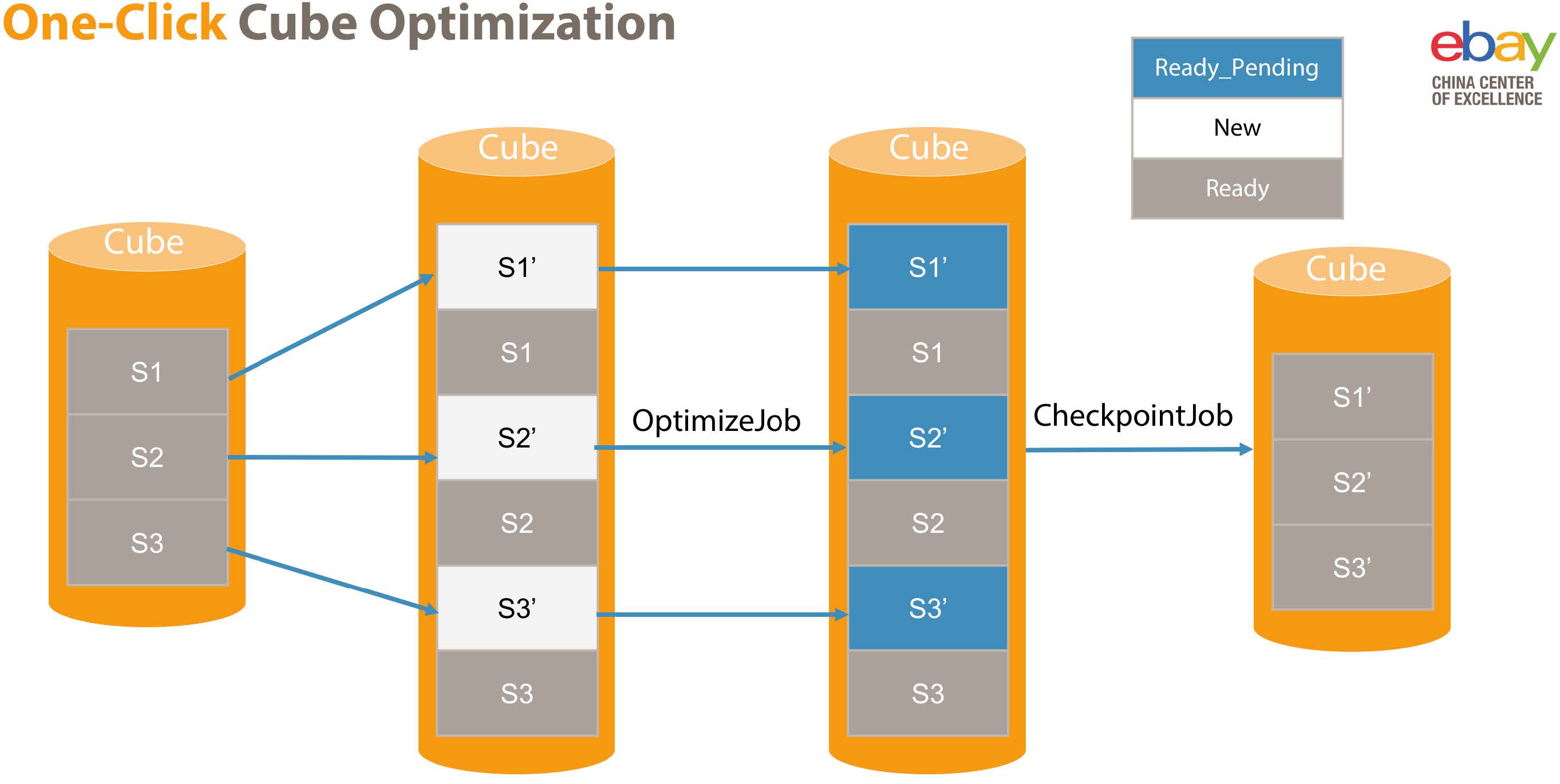
For the cube that is already on the production site, Cube Planner can use the collected query statistics, and intelligently recommend a dimension combination set for pre-calculation based on cost and benefit algorithm. Users can make a one-click optimization based on this recommendation. The following figure is the one-click optimization process. We use two jobs, Optimizejob and Checkpointjob, not only to ensure the optimization process concurrency, but also to ensure the atomicity of the data switching after optimizing. In order to save the resource of optimizing the cube, we will not recalculate all the recommended dimension combinations in Optimizejob, but only compute those new combinations in the recommended dimension combinations set. If some recommended dimension combinations are pre-calculated in the cube, we reuse them.
Application of Cube Planner in eBay
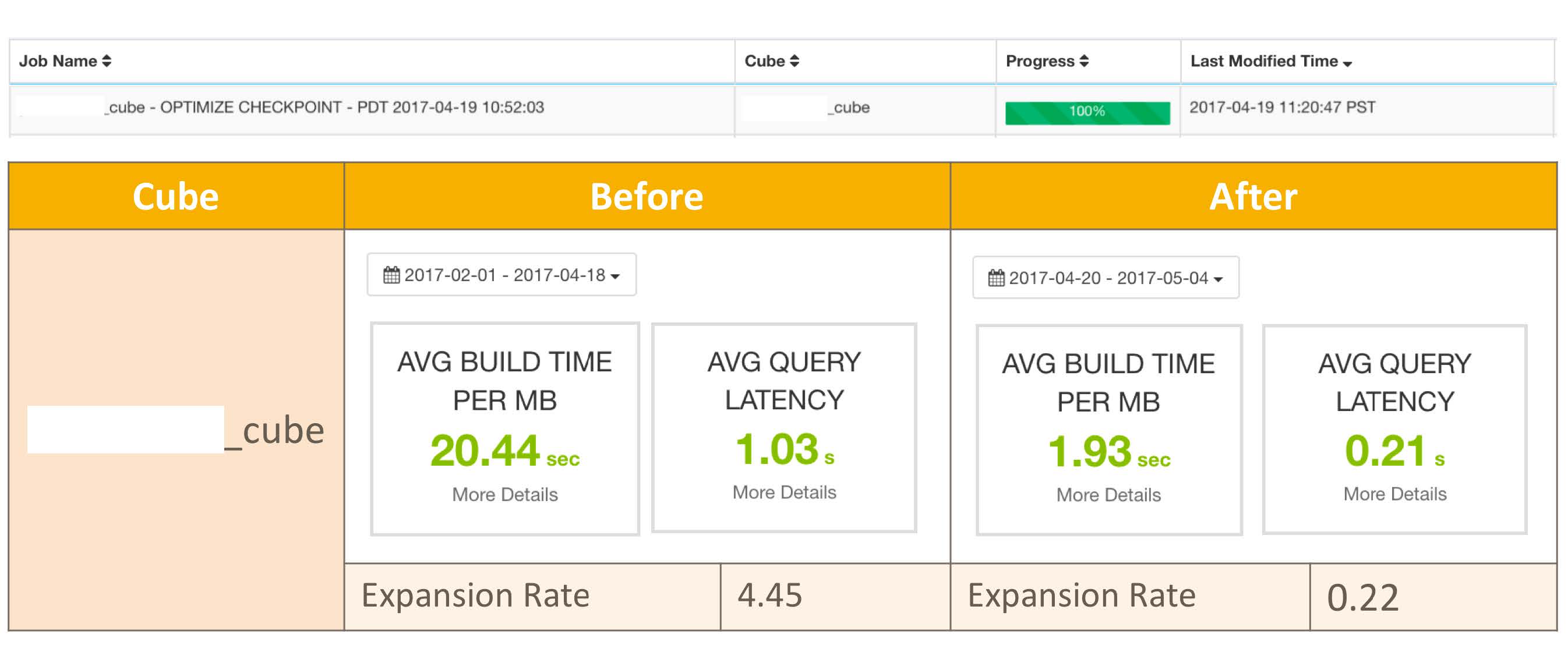
Cube Planner’s development was basically completed at the end of 2016. After a variety of testing, it was formally launched in the production environment in February 2017. After the launch, it was highly praised and unanimously recognized by the users. Here is an example of the use of Cube Planner on eBay’s production line. The customer optimized the cube on April 19th. The optimized cube not only had a significant boost in building performance, but also improved significantly in query performance.
Follow-up development of Cube Planner
In addition to enhancing resource utilization, Cube Planner has another goal of reducing the cube design complexity. At present, the design of a Kylin cube depends on the understanding of data. Cube Planner has made Kylin able to recommend and optimize based on data distribution and data usages, but this is not enough. We want to make the Kylin cube design a smart recommendation system based on query statistics across cubes within same domain.