Introduction
eBay’s data storage related to Shopping Cart information relies on two different data stores. There’s a MongoDB store that stores the entire cart contents for a user’s cart, and there’s an Oracle store that stores only the cart summary and basic cart details but has enough hints to recompute the full cart if needed. The Oracle store is used to overcome the persistence and consistency challenges (if any) associated with storing data in MongoDB. It’s easier to think of the MongoDB layer as a “cache” and the Oracle store as the persistent copy. If there’s a cache miss (that is, missing data in MongoDB), the services fall back to recover the data from Oracle and make further downstream calls to recompute the cart.
All MongoDB carts are in JSON format, while the Oracle carts are stored in JSON format in a BLOB column. (These Oracle carts are user-sharded and are used only for OLTP reasons. All other filtering and querying to peek into cart data happens via a data warehouse and denormalized access patterns.)
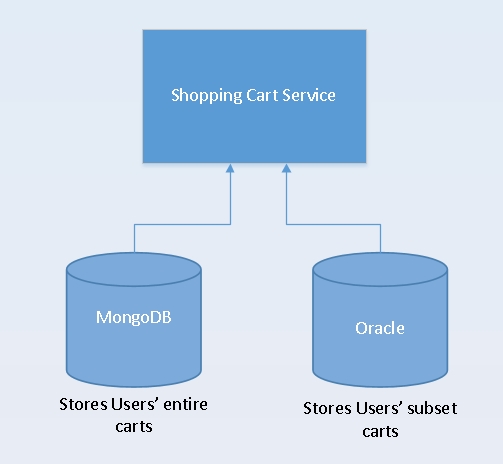
Figure 1. Storage architecture
While this is not a discussion on the choice of technology (Oracle vs. MongoDB vs. any other database), we are hoping that our experience gives folks an insight into what it takes to identify, debate, solve, and (most importantly) roll out fixes rapidly to a site that handles hundreds of millions of calls across tens of millions of users each day.
Problem statement
Late in 2016, the Shopping Cart service started experiencing a high number of misses at its caching layer, and at around the same time, we started getting alerts from eBay’s Ops team about our MongoDB replicas failing to catch up in a decent amount of time. (MongoDB runs in master-slave configuration and this description is worth a read if you are unfamiliar with the setup.) The setup, which was seemingly working “fine” for the past few years, had suddenly started to hit bottlenecks that were unrelated to any infrastructure or code change. Upon further investigation, this was narrowed down to MongoDB’s oplog hitting network I/O limits. You can think of the oplog as Oracle’s redo logs, except that this has a very critical purpose in making sure that the MongoDB read replicas are refreshed in as real time as possible. Due to this, the read replicas for a GET Cart operation, for example, were returning stale carts and were being rejected as a “cache” miss because of the incorrect (stale) version that was stamped on the cart. This meant that we were doing a lot more recomputes of users’ carts by falling back on the Oracle cart and using that to call downstream systems to formulate the full cart from the basic summary.
Obviously, this was a bad thing since we were making our users wait more than normal. (Cache misses are bad! Recomputes are bad!)
Solutions
Before we go into specific solutions, we want to call out the numerous other conversations and options that were worth a mention but not selected into the final bucket. For example, once the replicas were not catching up, we ran trials on “hiding” some of the replicas to try and allow them to catch up faster without taking user traffic. We also played around with timeouts and periodic replica reboots, but none of them seemed to cause the issues to die down.
Option 1: sharding (MongoDB)
The first obvious option was to split our JSON data into shardable sections. (Note that the entire cart was stored as a single JSON object.) This allows specific sections (only) to be written to disk and into a separate MongoDB cluster, which in turn reduces the number of writes and I/Os sent across the wire into the single master instance. The challenge with this approach was the re-write of the existing business logic to now understand a seemingly new schema.
Option 2: selective writes
This option would use MongoDB’s set command to update only the specific values changing on each update. While this works in theory, the kind of updates happening on the cart JSON object would involve domino-effect updates, which would pretty much trigger a change across numerous sections of the JSON. Keeping this aside, there was no assurance from the MongoDB folks that this would reduce the amount of oplogs being written. Their concern was that given the large number of selecting updates within a document, it might trigger the entire document update — thus not helping.
Option 3: client-side compressed writes and reads
Given the desire to get our situation fixed quickly, without rewriting the business logic, compression seemed like another logical option to consider. Reducing the amount of data coming into the master should correspondingly reduce the amount of data flowing into the oplog. However, this would convert the data into a binary format and would need clients to understand compressed reads and writes.
Our choice
Considering various options and the timings for them, we chose Option 3 as the fastest, cleanest, and the most likely to succeed at first try. The biggest assumption was that the CPU hit taken by the clients on compression and decompression would be well worth the savings in terms of the latency on the MongoDB side. One advantage we had is that we had already embraced SOA, and our service encapsulated all the calls in and out of the MongoDB cluster, so it was only our service (“client” to MongoDB) that needed to change.
Goals and considerations
Before we got started to do something as fundamental as this, we had to get our goals right first. Here were our simple premises.
- Allow carts to be compressed and persisted into MongoDB (no change of the data store at this time).
- Allow a choice of compression codecs and seamless shifting between reading with one codec and persisting/writing with another, in case there’s ever a need to change because of performance reasons.
- Allow reading of old, new, and intermediate carts, that is, forward and backward compatibility.
- Old carts can be read by new clients and should work.
- New carts can be read by old clients and should work.
- Old carts can be read and persisted as new carts.
- New carts can be read and persisted as old carts.
- Implementation should allow for uncompressed and compressed carts to be stored at the same time (not necessarily for the same exact cart).
- Ultimately, getting rid of raw uncompressed storage in favor of compressed carts.
- Make sure that there are no use cases needing real-time query of JSON data in the MongoDB store. (The new data will be compressed binary and won’t be query-able).
After a quick round of deliberation, we moved to the next phase of evaluation.
Codecs, codecs everywhere
For our choice of codecs, we had four well-known Java implementations we could choose from:
SNAPPY: Google-contributed compressor/de-compressor and heavily used in many Google products, externally and internally. The source code for the SNAPPY codec is available on GitHub.LZ4_HIGH: Open-source software, BSD 2-clause license, running in high-compression mode and requiring the storage capacity for decompression to work. The source code for the LZ4 codec is available on GitHub.LZ_FAST: Same as above, just running in fast compression mode.GZIP: the Java-provided implementation
We wrote a benchmark with sample cart data (all sizes in bytes) from production across these libraries to choose what our initial choice of algorithm would be. To make sure that they are not impacted by CPU or I/O spikes on the local machine, these tests were run multiple times to make sure that the results (sample shown here below) are consistent.
Running test for: SNAPPY
Orig_size Compressed Ratio Comp_time Decom_time Total_time
687 598 1.149 188.062ms 1.683ms 189.745ms
786 672 1.170 0.079ms 0.193ms 0.272ms
848 695 1.220 0.081ms 0.227ms 0.308ms
15022 3903 3.849 0.296ms 3.181ms 3.477ms
17845 4112 4.340 0.358ms 2.268ms 2.627ms
45419 9441 4.811 0.775ms 5.999ms 6.774ms
55415 10340 5.359 0.860ms 3.851ms 4.711ms
125835 21338 5.897 1.012ms 8.834ms 9.845ms
1429259 179838 7.947 6.248ms 14.742ms 20.990ms
4498990 625338 7.194 19.339ms 64.469ms 83.808ms
Running test for: LZ4_FAST
Orig_size Compressed Ratio Comp_time Decom_time Total_time
687 591 1.162 0.091ms 16.615ms 16.705ms
786 658 1.195 0.020ms 26.348ms 26.368ms
848 685 1.238 0.026ms 15.140ms 15.166ms
15022 3539 4.245 0.065ms 17.934ms 17.999ms
17845 3712 4.807 0.096ms 16.895ms 16.991ms
45419 6224 7.297 0.197ms 18.445ms 18.642ms
55415 6172 8.978 0.164ms 17.282ms 17.445ms
125835 11830 10.637 0.538ms 16.239ms 16.777ms
1429259 49364 28.953 4.201ms 21.064ms 25.265ms
4498990 167400 26.876 14.094ms 26.003ms 40.097ms
Running test for: LZ4_HIGH
Orig_size Compressed Ratio Comp_time Decom_time Total_time
687 589 1.166 0.149ms 0.032ms 0.181ms
786 648 1.213 0.064ms 0.012ms 0.076ms
848 676 1.254 0.066ms 0.013ms 0.079ms
15022 3270 4.594 0.232ms 0.041ms 0.273ms
17845 3349 5.328 0.244ms 0.045ms 0.290ms
45419 5192 8.748 0.587ms 0.154ms 0.741ms
55415 5130 10.802 0.666ms 0.102ms 0.769ms
125835 8413 14.957 1.776ms 0.403ms 2.179ms
1429259 17955 79.602 12.251ms 3.162ms 15.413ms
4498990 60096 74.863 35.819ms 8.585ms 44.404ms
Running test for: GZIP
Orig_size Compressed Ratio Comp_time Decom_time Total_time
687 447 1.537 0.939ms 0.636ms 1.575ms
786 489 1.607 0.138ms 0.103ms 0.240ms
848 514 1.650 0.099ms 0.109ms 0.207ms
15022 2579 5.825 0.502ms 0.400ms 0.902ms
17845 2659 6.711 0.596ms 0.508ms 1.104ms
45419 4265 10.649 1.209ms 0.755ms 1.964ms
55415 4324 12.816 1.301ms 0.775ms 2.076ms
125835 7529 16.713 3.108ms 1.651ms 4.760ms
1429259 23469 60.900 26.322ms 37.250ms 63.572ms
4498990 69053 65.153 153.870ms 103.974ms 257.844ms
Here are some observations:
SNAPPYseems to suffer from a slow start. The time taken for the first run is always notoriously high. It also has not-so-great compression ratios. We were surprised that SNAPPY performed so badly given how much talk it gets.LZ4_FASTdecompression times are almost constant, independent of size. It also shows not-so-great compression ratios though.LZ4_HIGHprovides great times for both compression and decompression and gets a bit slower at high data sizes.GZIPseems to get worse at high data sizes.
Given these results, LZ4_HIGH seems to be the most optimal code for the following reasons.
- No slow start issues or performance quirks observed
- Linear time growth with data sizes
- Excellent overall performance for small to medium cart sizes (well into the 99th percentile cart size) and reasonable performance at very large cart sizes
However, there’s one caveat. Decompression for LZ4_HIGH expects the output buffer size to be specified in the API call. The memory pre-allocation is likely what enables the faster decompression. It’s a price to be paid for the benefits but something we felt was useful enough to account for it in the final design. So while the decision was clear, the implementation was designed to have all four codecs available as choices to be possible to shift seamlessly between one codec or another (one of our goals as mentioned previously) depending on a future need.
Payload design
A sample payload of today’s shopping cart looks like this. The cart variable is the only interesting piece in the payload.
{
"_id" : ObjectId("560ae017a054fc715524e27a"),
"user" : "9999999999",
"site" : 0,
"computeMethod" : "CCS_V4.0.0",
"cart" : "...JSON cart object...",
"lastUpdatedDate" : ISODate("2016-09-03T00:47:44.406Z")
}Our new payload with support for compressed data looks like this. The cart variable remains unchanged, but the new elements, initially derived from the cart variable, provide support for the Compression feature.
{
"_id" : ObjectId("560ae017a054fc715524e27a"),
"user" : "9999999999",
"site" : 0,
"computeMethod" : "CCS_V4.0.0",
"cart" : "...JSON cart object...",
"compressedData" : {
"compressedCart" : "...Compressed cart object..."
"compressionMetadata" : {
"codec" : "LZ4_HIGH",
"compressedSize" : 3095,
"uncompressedSize" : 6485
},
},
"lastUpdatedDate" : ISODate("2016-09-03T00:47:44.406Z")
}Each of the fields in the compressionMetadata field is described below:
"compressedData"— The container that stores the compressed cart and metadata about the cart itself that will be used for compression/decompression."compressedCart" : "...Compressed cart object..."— The compressed data for thecartfield in the upper-level container."compressionMetadata"— The subcontainer that holds the metadata required for decompression and hints for certain codecs (for example,LZ4_HIGHthat needs the destination size (uncompressedSize) to work."codec" : "LZ4_HIGH"— Stored when compression runs and used when decompression runs."compressedSize" : 3095— Stored when compression runs and used when decompression runs (used byLZ4_HIGHonly, but we do not differentiate)"uncompressedSize" : 6485— Stored when compression runs and used when compression runs (used byLZ4_HIGHonly, but we do not differentiate)
Note that the sizes of the compressed and decompressed data are also stored every time although they are only really used when the codec is LZ4_HIGH. While all of this helped with the need to seamlessly switch between codecs, it also acted as a great source of statistical information for compression metrics for us.
Config-driven approach (versus experimentation)
Once the code rolled out to production, we had two approaches towards experimentation to make sure our implementation works seamlessly. The first was to go with an A/B test, the typical experimentation paradigm, and verify performance via standard reporting that’s already in place. The other option was via back-end config-driven testing. We chose the latter since we were confident that we could figure out issues with pure back-end metrics and have enough logging in place to identify issues. For example, we could make sure that the compressed and decompressed data matched the size stored in the metadata (else log a critical error). We also had alerting built into place that would give us an immediate read if any codec was mis-configured or failed to compress or decompress at run time.
To add to it all, eBay’s services follow the 12-factor approach for the most part. The one factor we focus on here is the config-driven approach that enables us to play around with different codec settings.
In summary, the whole rollout and validation process looked like this:
- Configure builds with compression feature =
OFFas default. - Roll out to all boxes, with a relaxed rollout template, making sure that there are no inadvertent impacts caused by the feature even when it is turned off. Bake for a few hours.
- Pick one random box and turn on compression config for that box ONLY in backwards-compatible mode. This mostly verifies compression, and very seldom is decompression expected to be triggered unless the same single box reads the previously compressed cart.
- Turn on the compression config for a few more boxes until all boxes compress but no one reads the compressed data yet. This causes even more increased traffic and worsen the current situation. Necessary evil.
- Turn on reading decompression config for one box. Make sure that this box is able to read the compressed field and use ONLY the compressed field.
- Like before, turn on reading decompression config for multiple boxes and then for all boxes. Verify across all boxes.
Finally, here are the different configs we used:
compressionEnabled=true/false— The master switch that controls whether this feature is enabled or not.compressionCodec= {SNAPPY,LZ4_HIGH,LZ4_FAST,GZIP} — One of the four choices that will be enabled, withLZ4_HIGHbeing the default choice.WRITE_MODE= One of three modes.NO_COMPRESS— Writes will not write the compressed data fields.DUAL— Writes will write the compressed data fields and the uncompressed/regular cart.COMPRESS_ONLY— Writes will write only the compressed data fields and null out the uncompressed/regular cart field.
READ_MODE= one of three modesNO_COMPRESS— Reads will read from the regular cart fields.VERIFY_COMPRESS— Reads will read from both the fields, use the regular cart field, but verify that the compression data is being decompressed correctly. Think of this as “audit” mode.COMPRESS_ONLY— Reads will directly read the cart from the compressed data fields, decompress it, and use it.
Note that not all mode combinations are valid. For example, WRITE_MODE = COMPRESS_ONLY and READ_MODE = NO_COMPRESS is invalid, and care should be taken to avoid that combination.
It might look like overkill, but the key goal to keep the site up and running at all costs with zero impact was playing on our minds all the time. We felt that the critical factor was to have all the different controls at your disposal for any eventuality.
Everything is backwards compatible. Backwards compatibility is everything.
We can’t emphasize this enough. For any site that cares about its Users, this is a critical factor to be factored into any new feature that is rolled out. Our goal was no different, and the diagram in figure 2 captures some of the complexity we faced.
A few things to keep in mind:
- Do not delete fields that are being deprecated. We added the
compressedDatafield as a new one to our existing JSON structure. - Make sure to separate out the code paths in a way and as close to the source of changing data. This practice almost always allows a better code-deprecation option in the future.
- Backward compatibility is critical even when new code is in the process of rollouts. Do not assume a 30 minute “incompatibility window” and everything will be fine after that. For example, you never know when things simply stall and you will be stuck in limbo for much longer.
For example, Figure 2 shows how our code paths looked while we were in the midst of rollout and both the old and new services were taking traffic. By separating out the logic right at the DAO/DO layer, the rest of the business logic continued as if nothing changed.
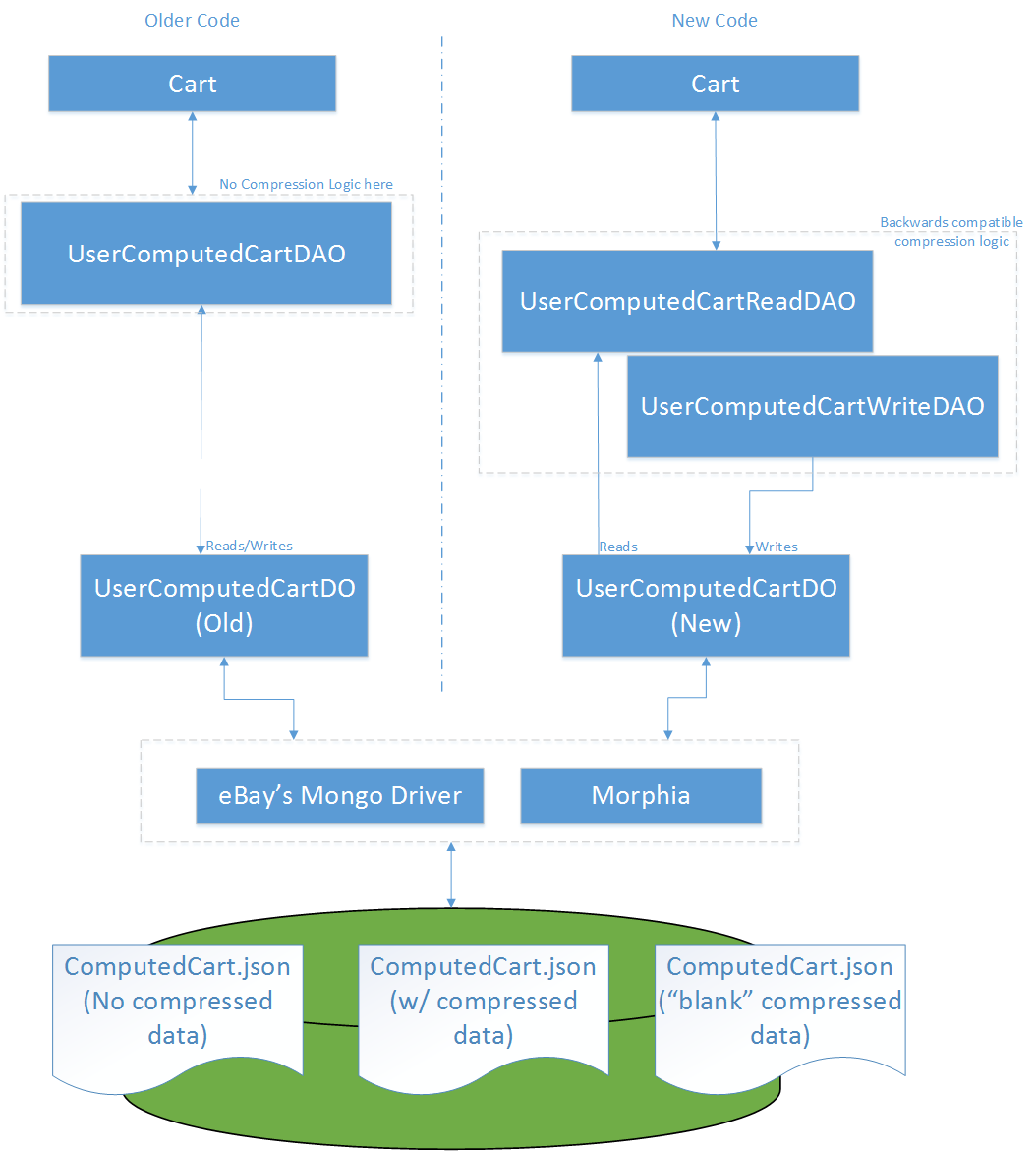
Figure 2. Code paths
Results
After a successful rollout, we saw some magical numbers. Our oplog write rates, which had been almost 150GB/hour, were down to about 11GB/hour, a 1300% drop! The average object size of the documents, which had been hovering around 32KB, was down to 5KB, a 600% drop! In fact, we even saw some improvements in our eventual service response times as well. So overall we achieved what we wanted with ZERO production issues, and all our bets and analysis paid fantastic dividends at the end, benefiting our customers.

Figure 3. Before-and-after average object sizes.
Figure 3 shows a screenshot from MongoDB’s Ops Manager UI tool that highlights the slight increase (when we were doing dual writes of compressed and uncompressed data) and the dramatic drop in the average object size from 32KB down to 5KB after we turned the feature on fully.
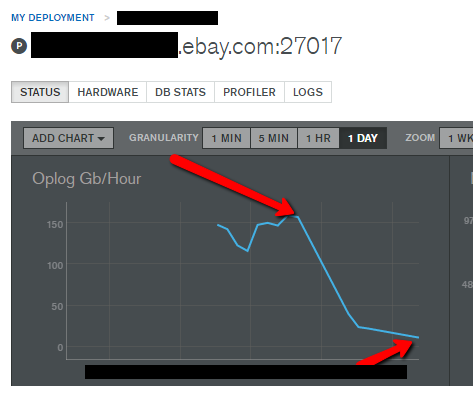
Figure 4. Before-and-after oplog throughput
Figure 4 shows another screenshot from MongoDB’s Ops Manager UI tool showing the slight increase and the dramatic drop in the oplog throughput after the feature was turned on fully.
Post-release, we also went ahead and removed the “dead code,” which was basically the old logic that worked only on compressed data. Over a period of time, as older carts keep getting refreshed, there will never even be a hint that we even had uncompressed data at some point in time! So how did the machines running the (de-)compression do? Not too bad at all. There was hardly any noticeable change comparing CPU and JVM heap usages before and after the code rollout.
Finally, here are some other scatter graphs for a random hour’s worth of data showing how the compression did in the Production environment. These graphs provide many other interesting observations, but those are left as an exercise for the reader.
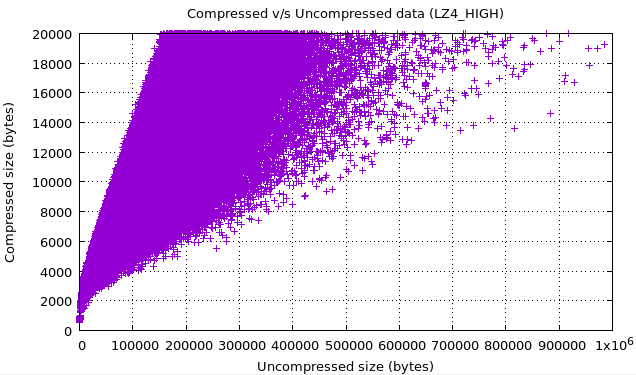
Figure 5. A scatter plot showing compression achieved for the uncompressed data plotted against the original (uncompressed) data

Figure 6. A scatter plot showing the behavior of read times (that is, decompression) versus the size of the compressed data

Figure 7. A scatter plot showing the behavior of write times (that is, compression) versus the size of uncompressed data