Building applications resilient to infrastructure failure is essential for systems that run in a distributed environment, such as NoSQL databases. For example, failure can come from compute resources such as nodes, local/remote clusters, network switches, or the entire data center. On occasion, NoSQL nodes or clusters may be marked down by Operations to perform administrative tasks, such as a software upgrade and adding extra capacity. In this blog, you can find information on how to build resilient NoSQL applications using appropriate design patterns that are suitable to your needs.
Note that the resilience design pattern described in this blog is complementary to other patterns, such as the Hystrix library. The difference is that it focuses on the following abstractions:
- NoSQL database architecture and capability abstraction, such as replication strategy, durability, and high availability
- Infrastructure and environment abstraction, such as standard minimal deployment, disaster recovery, and continuous operation
- Application abstraction, such as workload, performance, and access patterns
Why resiliency design patterns for NoSQL databases?
Enabled by more efficient distributed consensus protocols, such as Paxos and Raft, and new thinking, such as flexible database schema, NoSQL databases have grown out of early adoption and are gaining popularity among mainstream companies. Although many NoSQL vendors tout their products as having unparalleled web-level scalability and capabilities such as auto-failover, not all are created equal in terms of availability, consistency, durability and recoverability. This is especially true if you are running mission-critical applications using heterogeneous NoSQL systems that include key-value (KV) pairs, column families (CF), and document and graph databases across a geographically dispersed environment.
It becomes imperative that a well-run enterprise optimizes its management to achieve the highest operational efficiency and availability. To accomplish this, an enterprise should not only empower application developers with well-defined NoSQL database resilience design patterns so that they can be relieved from preventable infrastructure failure, but it should also provide a guaranteed-availability Service Level Agreement (SLA) on these resilience design patterns.
NoSQL resiliency design pattern consideration
Given the enormous complexity associated with integrating an enterprise-class infrastructure, such as eBay, developing meaningful and usable NoSQL resilience pattern is more than just one dimension — it comprises a multitude of coherent and intricately interconnected cogs such as these:
- Use case qualification
- Application persistence error handling
- Technology stack and engineering framework
- Data center infrastructure (for example, public/private/hybrid cloud) configuration and setup
- NoSQL database-agnostic and -specific resilience abstraction
- Operation and management best practice and standard operation procedure (SOP)
Since NoSQL databases are not panaceas, ill-suited applications can disrupt operations and cause friction between stakeholders within the organization. The first step toward defining a meaningful NoSQL database resilience pattern is to ensure that only qualified use cases will use it. With that, we recommend the following guidelines when qualifying new NoSQL use cases.

NoSQL resiliency design pattern approach
One main objective of a NoSQL resilience design pattern is that it should support a wide range of use cases across different NoSQL databases. To achieve this objective, we devised the following steps in our approach:
- Identify a meaningful NoSQL database architectural abstraction based on the CAP theorem, ACID/BASE properties, and performance characteristics.
- Categorize and define types of different resilience patterns based on workload, performance, and consistency properties that are meaningful to applications.
- Define a standardized minimal NoSQL deployment pattern for common small-to-medium, non-mission critical use cases.
- Define an enhanced design pattern to support mission-critical use cases that require high availability, consistency, durability, scalability, and performance.
- Define other design patterns to support non-conforming use cases, for example, standalone without disaster recovery (DR), and application sharding.
Given that JSON has become the de facto standard data format for web-centric e-commerce businesses like eBay, this blog will use two of the top document-centric NoSQL databases (MongoDB and Couchbase) to illustrate our proposed resilience design pattern.
Although a tutorial on MongoDB and Couchbase is beyond the scope of this blog, the high-level comparison between them in Table 1 helps illustrate their differences. It also helps explain how these differences influence respective resilience design patterns for each product.
| MongoDB | Couchbase | |||
|---|---|---|---|---|
| * Throughout this blog post, for convenience we designate one Couchbase cluster per data center even though multiple clusters can be set up per data center. However, nodes in the same Couchbase cluster do not span across multiple data centers. | ||||
| Name | Replica set/sharded cluster | “Cluster”* | ||
| Architecture | Master-slave | Peer-to-peer | ||
| Replication | Master to slave (or primary to secondary) nodes | Local cluster | Primary to replica nodes | |
| Multiple cluster | Bi- or uni-directional Cross Data Center Replication (XDCR) | |||
| Sharding | Optional | Built-in | ||
| Quorum | Read | Yes | No | |
| Write | Yes | |||
From the comparison above, we observe the following characteristics when designing a resilience pattern design:
- NoSQL databases tend to simplify their resilience pattern if they are based on peer-to-peer architecture.
- NoSQL databases tend to complicate their resilience pattern if they lack quorum read/write, an important capability to support global read and write consistency.
Lastly, we found it helpful to organize resilience design patterns into different categories, as shown in the Table 2. For brevity, we will focus the examples on the following three categories: workload, durability, and application sharding.
| Category | Pattern |
|---|---|
| Workload | General purpose mixed read and write ✔ |
| Performance | High performance read and/or write |
| Durability | 100% durability |
| High local and/or cross data center durability ✔ | |
| High availability (HA) | High availability local read and write |
| High availability multi-data center read and write | |
| High Read and write consistency | High local data center read and write consistency |
| High multi-data center read and write consistency | |
| Others | Administration, backup and restore, application sharding … ✔ |
Standard minimal deployment
As mentioned earlier, one key objective of NoSQL resilience design patterns is to relieve applications and Operation of preventable infrastructure failure. It is our opinion that, disregarding the size or importance of applications, enterprise-class NoSQL clusters should be able to handle node, cluster, site or network partition failure gracefully with built-in preventive measures. Also, they should be able to perform disaster recovery (DR) within reasonable bounds. This assumption warrants the need of the “standard minimal deployments” described below.
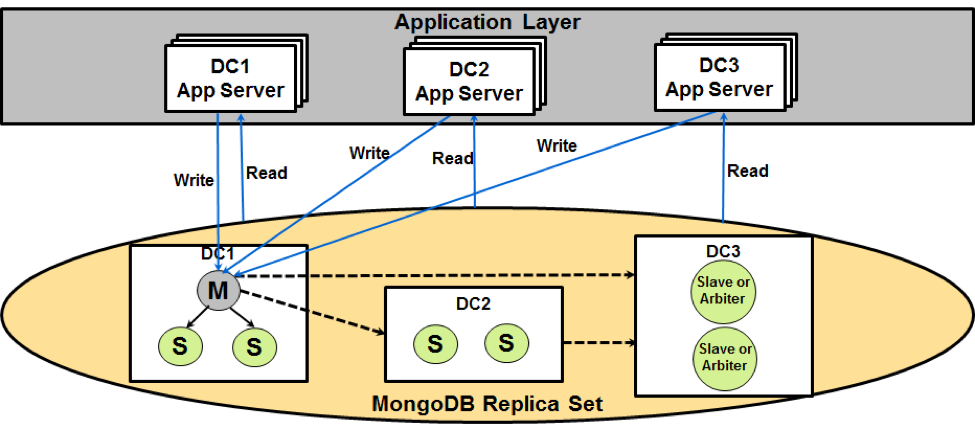
MongoDB standard minimal deployment
According to our experience managing some of the largest 24×7 heterogeneous NoSQL clusters in the world, we recommend the following “standard minimal deployment” best practice for enterprise-class MongoDB deployments:
- Whenever possible, nodes in the same MongoDB replica set will be provisioned in different fault domain to minimize any availability risk associated with node and network failure.
- Standard MongoDB deployment (for example, type 1 in Table 3) always includes third data center with two or more secondary nodes. For applications that do not have traffic in a third data center, light-weight arbiter nodes should be used for cross-data center quorum voting during site or total data center failure.
- With few exceptions (for example, type 2 below), a MongoDB replica set can be deployed in only one data center if applications do not require remote DR capability.
| Deployment Type | MongoDB Replica Set Nodes Configuration | Description | |||
|---|---|---|---|---|---|
| Data Center 1 | Data Center 2 | Data Center 3 | |||
| 1 | Standard deployment with built-in DR capability | Minimum three nodes, which include one primary and two secondary nodes | Minimum two secondary nodes | Minimum two secondary or arbiter nodes.This is to ensure that should any one data center experience total failure, it is not excluded from quorum voting for new primary node. | In selected high traffic or important use cases, additional secondary nodes may be added in each data center. The purpose is to increase application read resilience so that surviving nodes won’t be overwhelmed in case of one or more secondary nodes fail in any data center. |
| 2 | Special qualified use case without DR | Three (one primary, two secondary nodes) | This deployment pattern is for use cases that do not require remote DR since applications can rebuild the entire dataset from an external data source.Furthermore, the lifespan of data can be relatively short-lived and may expire in a matter of minutes, if not seconds. In selected high traffic or important use cases, additional secondary nodes may be added to the replica set to help increase resilience. | ||
The following diagram illustrates the MongoDB “standard minimal deployment” pattern.
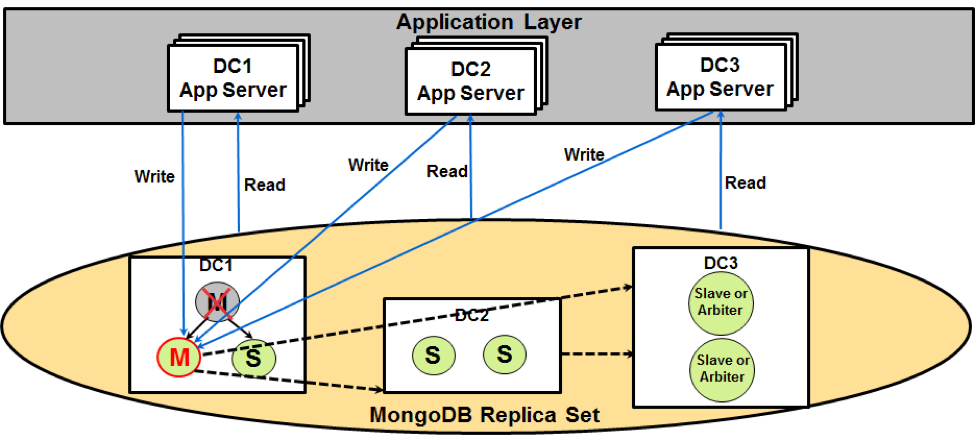
During primary node failover, one of the available secondary nodes in either data center will be elected as the new primary node, as shown in the following diagram.
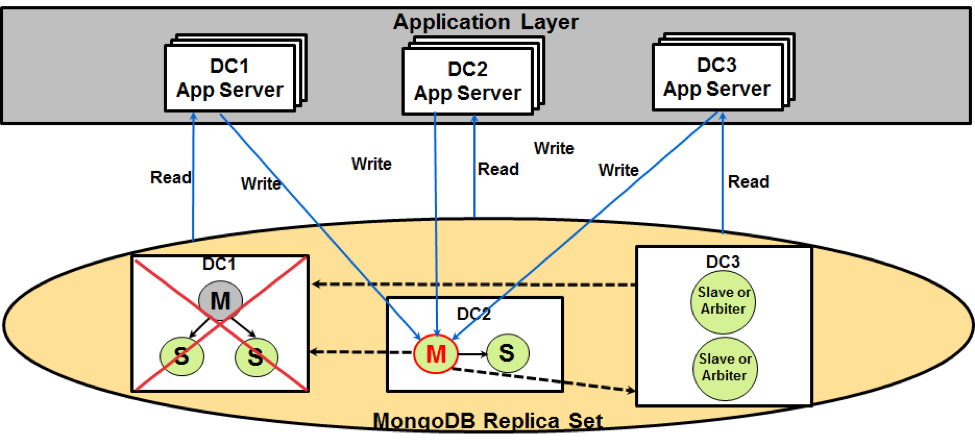
During site or data center failure, one of the available secondary nodes in other data centers will be elected as the new primary node, as shown in the following diagram.
Couchbase standard minimal deployment
With peer-to-peer architecture, Couchbase’s “standard minimal deployment” does not require a third data center since it does not involve quorum voting when failing over to a new primary node. Arguably, increasing minimal nodes from four to five or six or more per data center can help strengthen operational viability should two or more nodes in the same data center fail at the same time (itself an unlikely scenario if they were provisioned in different fault domains in the first place). With that, we feel that a minimal four nodes per data center are sufficient for most Couchbase use cases to start with.
| Deployment Type | Couchbase Replica Set Nodes Configuration | Description | |||
|---|---|---|---|---|---|
| Data Center 1 | Data Center 2 | Data Center 3 (Optional) | |||
| 1 | Standard deployment with built-in DR capability | 4+ nodes | 4+ nodes | 4+ nodes | See description above |
| 2 | Special qualified use case without DR | 4+ nodes | Same as MongoDB | ||
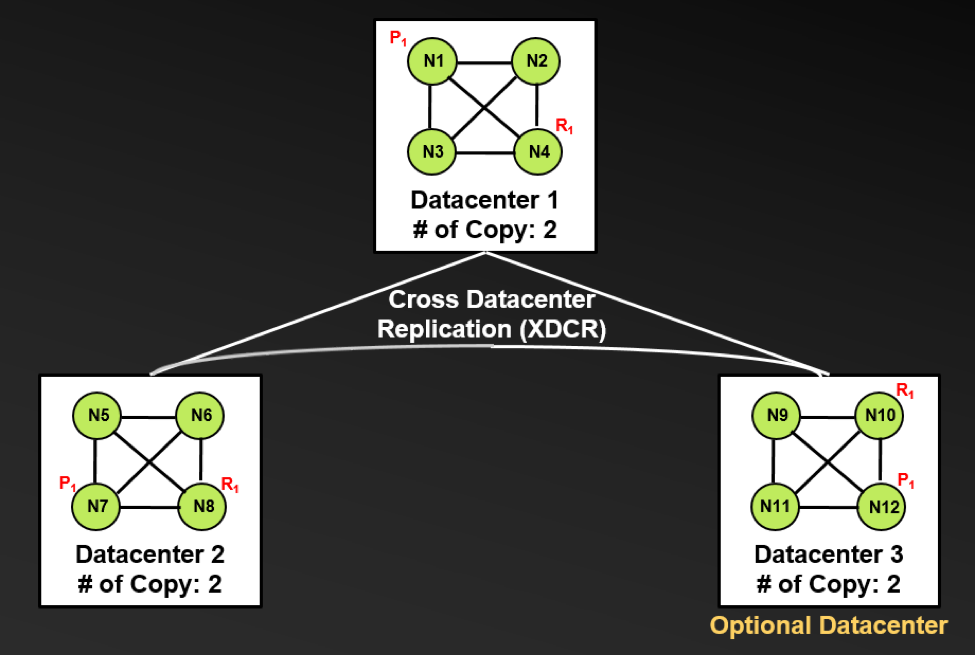
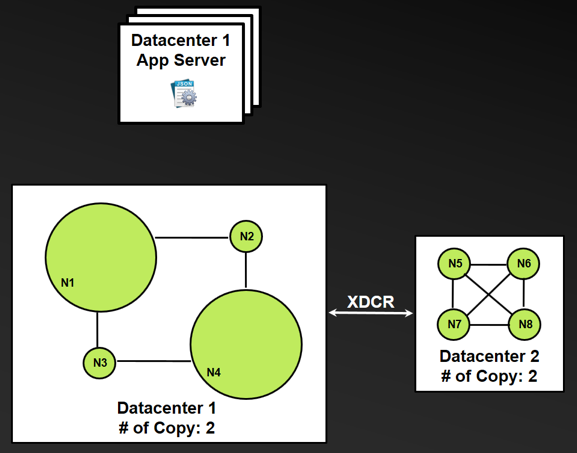
The following diagram illustrates the Couchbase “standard minimal deployment” pattern where each data center/cluster has two copies of the same document (for example, P1 being the primary copy and R1 the eventually consistent replica copy).
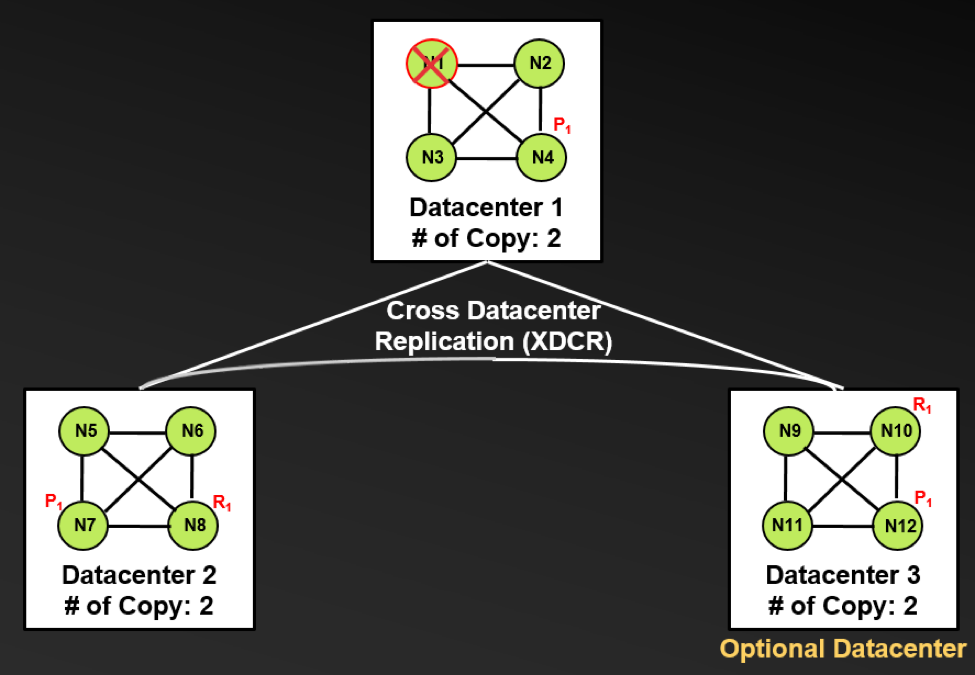
During automatic node failover, the Couchbase client SDK in applications will detect node failure and receive an updated failover cluster map with a topology containing the new location of replica documents that have been promoted to primary. This is shown in following diagram.
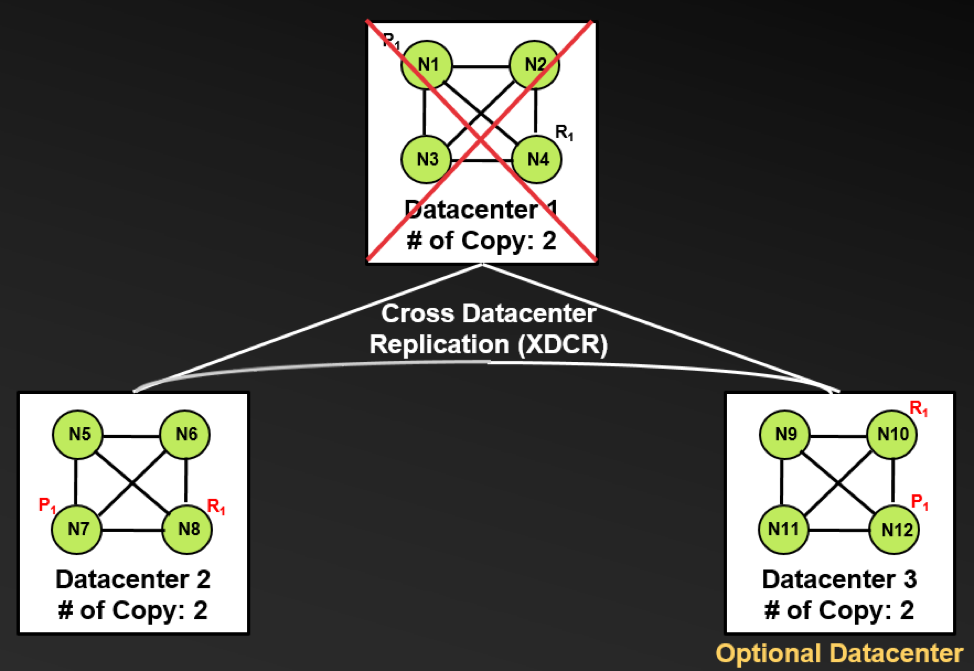
Although Couchbase supports bidirectional Cross Data Center Replication (XDCR) between geographically dispersed clusters, its current implementation does not offer automatic cluster failover. To address this limitation, Couchbase will support a new feature called Multi-Cluster Awareness (MCA) in a future release (tentatively v4.x) to provide this capability, as shown in following diagram.
High-level MongoDB and Couchbase resilience capability comparison
Before we talk about the details of an individual resilience design pattern for each product, it helps to understand the capability of MongoDB and Couchbase in terms of high availability, consistency, durability, and DR across local and multiple data centers. The following table highlights their differences.
| NoSQL Database | Data center | High Availability | High Consistency | High Durability | DR |
|---|---|---|---|---|---|
| * MCA (Multi-Cluster Awareness) and TbCR (Timestamp-based Conflict Resolution) will be available in a future Couchbase v4.x release. | |||||
| MongoDB | Local DC | No for Write Yes for Read |
Yes | Yes | No |
| Multi DC | Yes | ||||
| Couchbase | Local DC | No for Write Yes for Read |
Yes | Yes | No |
| Multi DC | Yes with MCA* | No | Yes with MCA and TbCR* | Yes | |
From the above comparison, we observe one similarity between MongoDB and Couchbase in their support for high-availability writes or the lack of. This is because both products limit their writes to a single primary node only. Nonetheless, Couchbase does plan to support high-availability write for multiple data centers through its future Multi-Cluster Awareness feature, which will help alleviate this limitation. This is the reason why Couchbase’s standard minimal deployment pattern requires at minimum two data centers/clusters.
MongoDB resilience design pattern examples
Before we show MongoDB’s resilience design pattern examples, it is important to understand how data loss can happen in MongoDB if applications do not use a proper resilience design pattern.
Non-synchronous writes
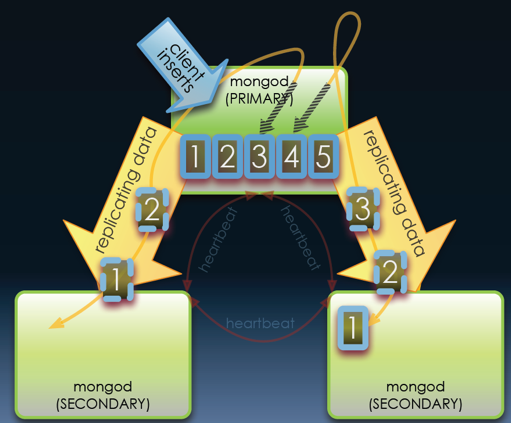
Let’s assume that you have a MongoDB replica set comprised of three nodes. The following operations illustrate how data loss can happen:
- First, the application writes five documents and receives write confirmation from the primary node only.
- The first three documents are replicated successfully at the second secondary node, and two documents are replicated at the third secondary node.

- The primary node fails before all five documents reach both of the two secondary nodes

- Quorum voting re-elects the second secondary node as the new primary node because it receives the third document, that is, more recently than the third secondary node

- The original primary node steps down to be a secondary and rolls back its fourth and fifth documents, since they didn’t reach other two secondary nodes

- In effect, the application loses the fourth and fifth documents even though it receives confirmation from the original primary node. The issue associated with this type of data loss (non-synchronous write) occurs because that application didn’t apply the “quorum write” option to majority nodes in the same replica set.
- In addition to “quorum write”, one should also enable MongoDB’s write-ahead logging journal file to further increase primary node write durability.
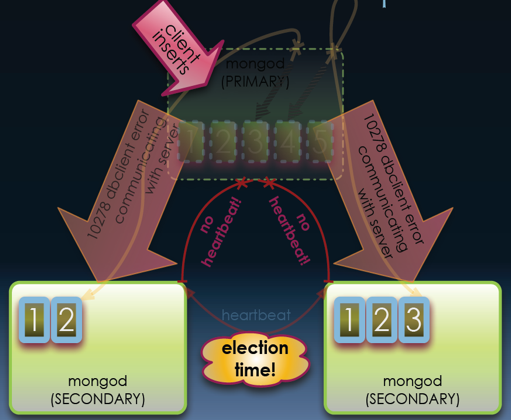

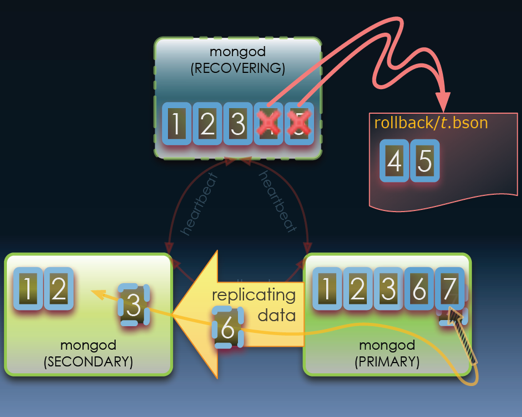
Since non-synchronous write is just one type of issue that can happen to applications, it is not sufficient to develop a pattern just to solve it. Having various add-on patterns, like synchronous write and others, on top of the MongoDB standard minimal deployment patterns helps enrich the overall NoSQL database resilience capabilities.
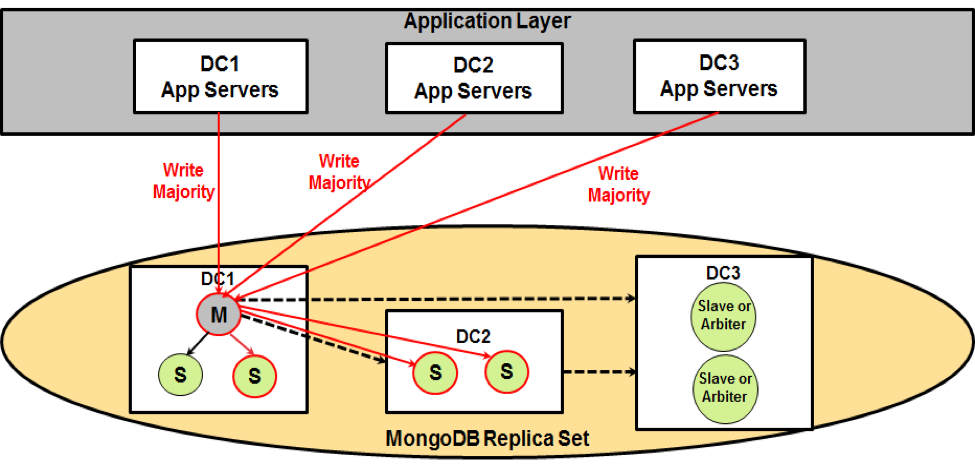
MongoDB write durability pattern
To achieve MongoDB replica-set-wide write durability, an application should use MongoDB’s WriteConcern = Majority option, where a write waits for confirmation from majority nodes across multiple data centers. During primary node failover, one of the majority secondary nodes having the latest committed write will be elected as the new primary node.
One caveat of this pattern is that one should weigh the pros and cons associated with waiting for cross-data center majority nodes confirmation, since it may not suitable for applications that require short latency.
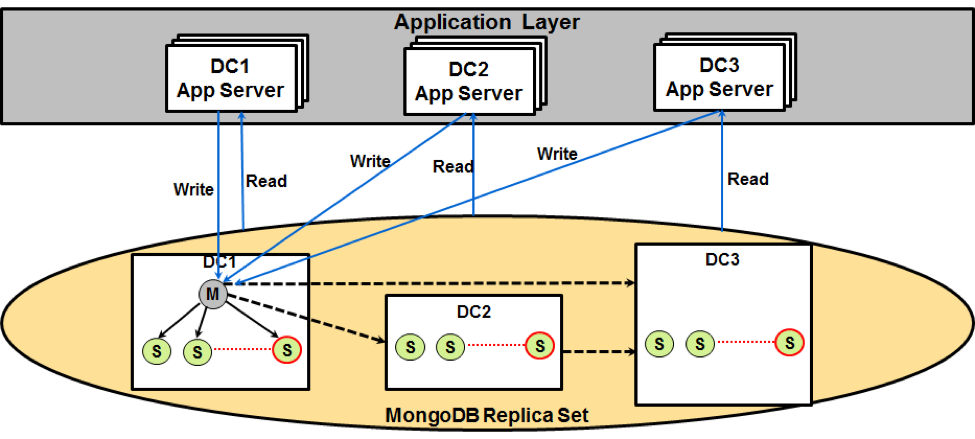
MongoDB read intensive pattern
This pattern is for applications that require high availability reads. With MongoDB’s master-slave replication architecture and ability to scale up to 49 secondary nodes across multiple data centers, it inherently supports highly available reads, provided that the number of healthy secondary nodes in any data center are capable of handling read traffic if one or more fail. Note that even though the current MongoDB replica set can scale up to 50 nodes, only 7 nodes can vote during primary node failover. The following diagram illustrates this capability.
MongoDB extreme high write pattern
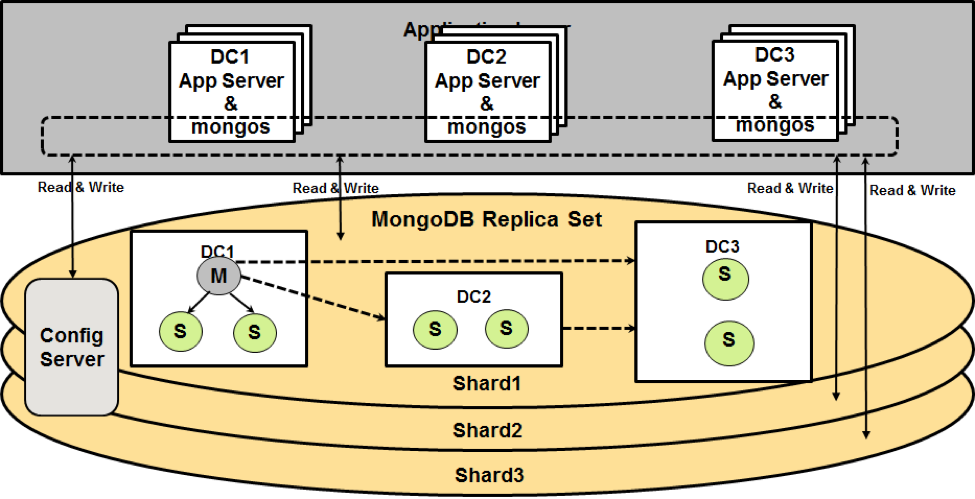
Use cases requiring extreme high writes can use MongoDB optional sharding since it allows horizontal write scaling across multiple replica sets (shards). Each shard (or replica set) stores part of the entire dataset as defined by a predefined shard key of the collection. With a well-designed shard key, MongoDB automatically distributes and balances read/write queries to designated shards. Although MongoDB sharding provides horizontal scale-out write capability, this pattern incurs consequent complexity and overhead and should be used with caution:
- An application should start with sharding using an appropriate shard key from the start instead of migrating from a single replica set as afterthought. This is because migrating a single replica set to a sharded cluster is a major undertaking from both development and operations perspectives.
- We recommend starting with a predefined number of shards capable of handling capacity and traffic in the foreseeable future. This helps eliminate the overhead associated with rebalancing when adding new shards.
- Note that MongoDB automatic shard balancing may introduce spikes during chunk migration and can potentially impact performance.
- Developers needs to understand behavior and limitation on how mongos, a software router process, on queries that do not include shard key, such as scatter gather operations.
- Developers should weigh the pros and cons of the overhead associated with running mongos as part of application servers vs. in separate nodes.
The following diagram illustrates this capability.
Couchbase resilience design pattern examples
Although Couchbase does not support write-ahead logging or quorum write, it achieves high durability through following mechanisms:
- Local cluster durability — ReplicateTo and PersistTo functions
- Multi-cluster durability (to be released in a future v4.x release):
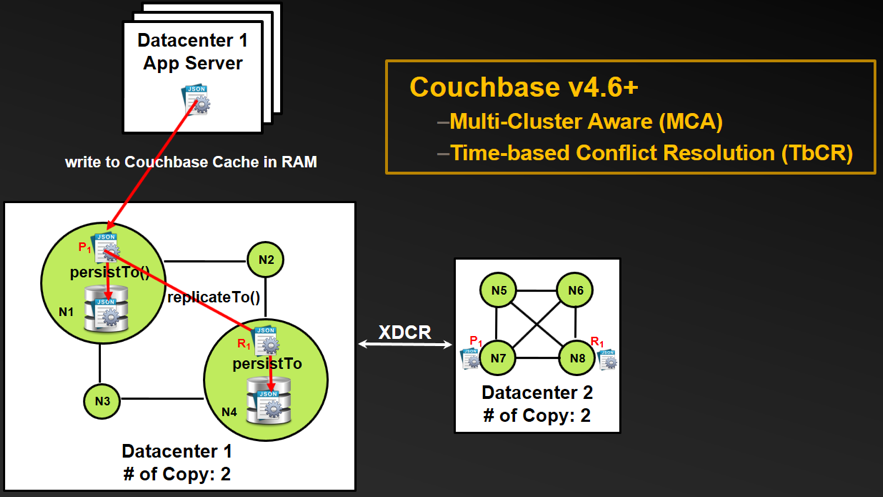
- Multi-Cluster Awareness (MCA) — Without application logic, this feature allows application developers and DBA to define rules on how applications should behave in the event of complete data center/cluster failover.
- Timestamp-based Conflict Resolution (TbCR) — Based on a server-synced clock, this feature provides Last-Write-Win (LWW) capability on bidirectional replication update conflict resolution to ensure correct cross-data center/cluster write durability.
Couchbase local cluster write durability pattern
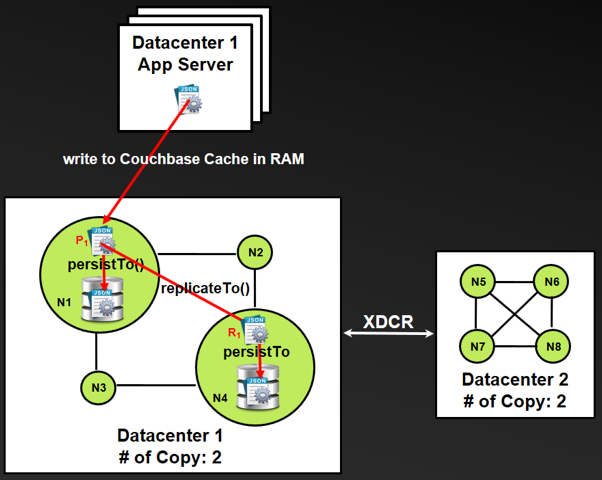
For local cluster durability, Couchbase provides the following two functions through its client SDK:
- ReplicateTo — This function allows writes on the same document to be successfully replicated in memory for all copies in the local cluster. However, it does not guarantee writes to be persisted on disk, which may result in data loss if both primary and replica nodes fail before that happens.
- PersistTo — For increased durability, applications can use this function so that writes will not only be successfully replicated in memory but also persisted on disk in the local cluster.
Note that even with the second PersistTo function, the current Couchbase version still does not guarantee writes to be successfully replicated to remote data centers/clusters. (This capability is explained in the next section, “Couchbase Multi-cluster write durability pattern.”) The following operations illustrate how both functions work.
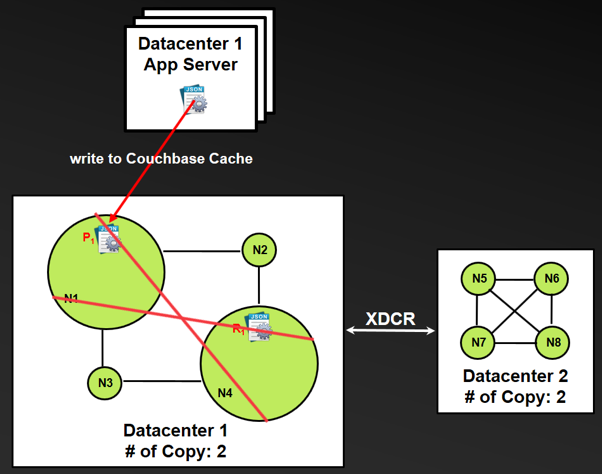
- Assume that the Couchbase topology contains four nodes per data center/cluster with each storing two copies of the same document replicated through XDCR between clusters.

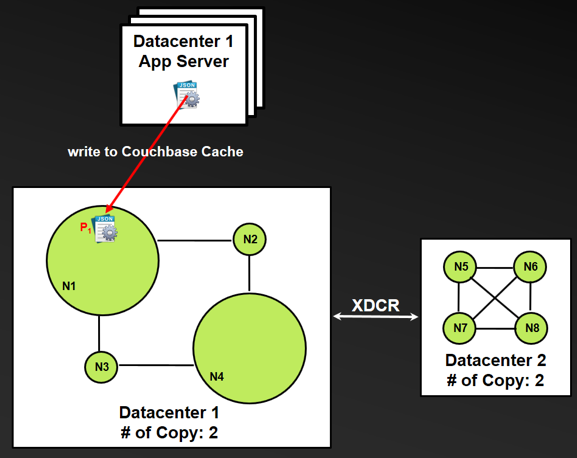
- The application in Data Center 1 writes documentP1 to nodeN1.

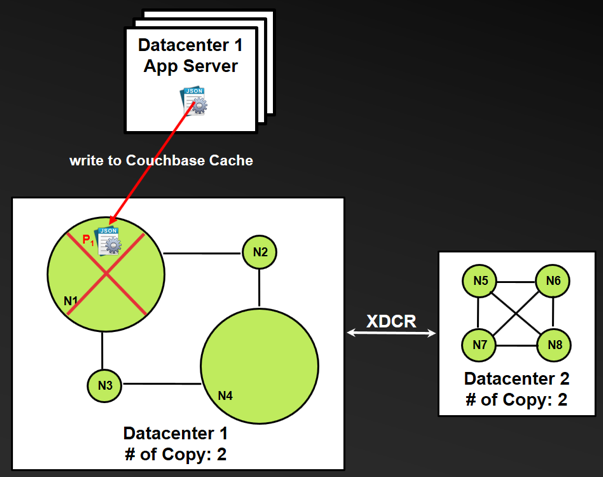
- BeforeP1 is replicated to the replica node in the local cluster or to the remote data center/cluster, nodeN1 fails, and as a result the application suffers data loss.

- BeforeP1 reaches the remote data center/cluster, even thoughP1 has been replicated successfully in memory to the local cluster replica nodeN4, if bothN1 andN4 nodes fail, the application still suffers data loss.

- Using the ReplicateTo function can circumvent the failure described in step 3, and using the PersistTo function can circumvent the failure described in step 4, as shown in the following figure.

- Lastly, for multi-data center/cluster durability, use the design pattern described in “Couchbase multi-cluster write durability pattern.
Couchbase multi-cluster write durability pattern
With its Multi-Cluster Awareness and Timestamp-based Conflict Resolution features, Couchbase supports multi-cluster durability as shown below.
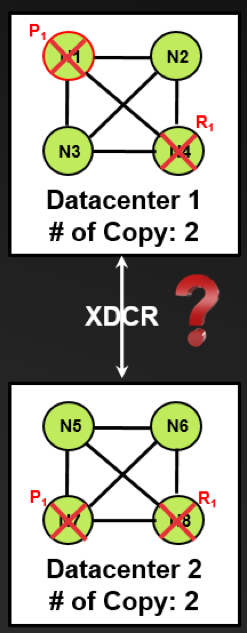
In the absence of write-ahead logging or quorum write, and even though Couchbase provides sufficient support for local and multi-cluster durability, one should still ask this question: what is the likelihood that all primary and replica nodes fail in multiple data centers or even worse that all data centers fail completely at the same time? These two unlikely failure scenarios are shown in the following two diagrams. We feel that the odds are next to zero if one follows this proposed Couchbase durability design pattern.
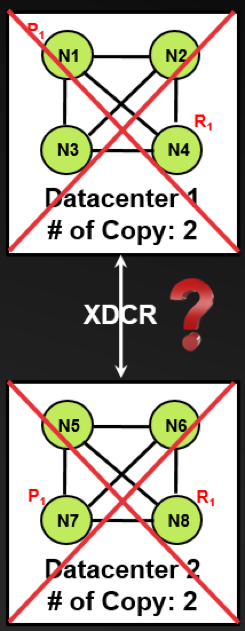
Couchbase read/write intensive scalability pattern
With its peer-to-peer architecture and XDCR’s bidirectional multi-cluster/data center replication capability, Couchbase affords users the flexibility to provision clusters with different sizes and shapes tailored for specific traffic/capacity and usage patterns. This flexibility is shown in the following diagram. On the other hand, the cluster-sizing calculation exercise can become complicated. This is especially true if it involves Multi-Dimensional Scaling.

Other NoSQL design pattern examples
NoSQL DB-agnostic application sharding pattern
The motivation behind this design pattern is that almost all large-scale mission-critical use cases require high availability. According to our experience, it doesn’t matter which NoSQL database you use or how comprehensive the best practice and SOP you follow, sometimes simple mundane maintenance tasks can jeopardize the overall database availability. The larger the size of database, the more severe the damage it may suffer. This design pattern offers an alternative solution using a divide-and-conquer approach, that is, by reducing the NoSQL database cluster to a small and manageable size through the following mechanisms:
- Applications shard their data using modular, hash, round robin, or any other suitable algorithm.
- The DBA and Operations provide a standard-size NoSQL cluster to host each application-level shard.
- If needed, each application-level shard can further use built-in NoSQL vendor product sharding if it is available.
Using MongoDB as an example, the following diagram illustrates this design pattern. One caveat associated with this pattern is that it requires a middle-tier data access layer to help direct traffic, an effort that must not be underestimated.
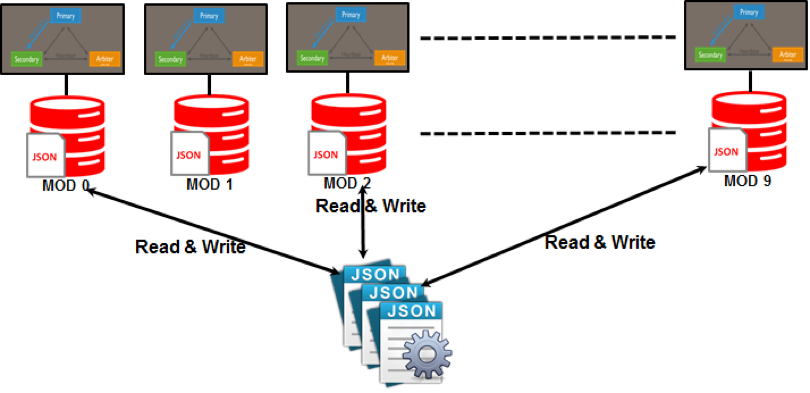
Future work and direction
In this blog, we described the motivation, consideration, and approach behind our proposed NoSQL resilience design pattern. We overviewed key differences between MongoDB and Couchbase in the context of resilience patterns. We also walked through three NoSQL resilience design pattern examples and a DB-agnostic application sharding pattern. In conclusion, we would like to suggest the following future work and direction on this topic:
- Provide end-to-end integration of proven NoSQL design patterns with application frameworks and also cloud provisioning and management infrastructure.
- Formalize the above NoSQL design patterns as officially supported products rather than just engineering patterns.
- Add other types of resilience patterns, such as high consistency.
- Add support for other NoSQL databases, for example, Cassandra.
- Collaborate with NoSQL vendors and develop new resilience patterns for new features and capabilities.
The graphics in Non-synchronous writes are reproduced with the kind permission of Todd Dampier from his presentation “Rock-Solid Mongo Ops“.