We are happy to announce Pulsar – an open-source, real-time analytics platform and stream processing framework. Pulsar can be used to collect and process user and business events in real time, providing key insights and enabling systems to react to user activities within seconds. In addition to real-time sessionization and multi-dimensional metrics aggregation over time windows, Pulsar uses a SQL-like event processing language to offer custom stream creation through data enrichment, mutation, and filtering. Pulsar scales to a million events per second with high availability. It can be easily integrated with metrics stores like Cassandra and Druid.
![]()
Why Pulsar
eBay provides a platform that enables millions of buyers and sellers to conduct commerce transactions. To help optimize eBay end users’ experience, we perform analysis of user interactions and behaviors. Over the past years, batch-oriented data platforms like Hadoop have been used successfully for user behavior analytics. More recently, we have newer use cases that demand collection and processing of vast numbers of events in near real time (within seconds), in order to derive actionable insights and generate signals for immediate action. Here are examples of such use cases:
- Real-time reporting and dashboards
- Business activity monitoring
- Personalization
- Marketing and advertising
- Fraud and bot detection
We identified a set of systemic qualities that are important to support these large-scale, real-time analytics use cases:
- Scalability – Scaling to millions of events per second
- Latency – Sub-second event processing and delivery
- Availability – No cluster downtime during software upgrade, stream processing rule updates , and topology changes
- Flexibility – Ease in defining and changing processing logic, event routing, and pipeline topology
- Productivity – Support for complex event processing (CEP) and a 4GL language for data filtering, mutation, aggregation, and stateful processing
- Data accuracy – 99.9% data delivery
- Cloud deployability – Node distribution across data centers using standard cloud infrastructure
Given our unique set of requirements, we decided to develop our own distributed CEP framework. Pulsar CEP provides a Java-based framework as well as tooling to build, deploy, and manage CEP applications in a cloud environment. Pulsar CEP includes the following capabilities:
- Declarative definition of processing logic in SQL
- Hot deployment of SQL without restarting applications
- Annotation plugin framework to extend SQL functionality
- Pipeline flow routing using SQL
- Dynamic creation of stream affinity using SQL
- Declarative pipeline stitching using Spring IOC, thereby enabling dynamic topology changes at runtime
- Clustering with elastic scaling
- Cloud deployment
- Publish-subscribe messaging with both push and pull models
- Additional CEP capabilities through Esper integration
On top of this CEP framework, we implemented a real-time analytics data pipeline.
Pulsar real-time analytics pipeline
Pulsar’s real-time analytics data pipeline consists of loosely coupled stages. Each stage is functionally separate from its neighboring stage. Events are transported asynchronously across a pipeline of these loosely coupled stages. This model provides higher reliability and scalability. Each stage can be built and operated independently from its neighboring stages, and can adopt its own deployment and release cycles. The topology can be changed without restarting the cluster.
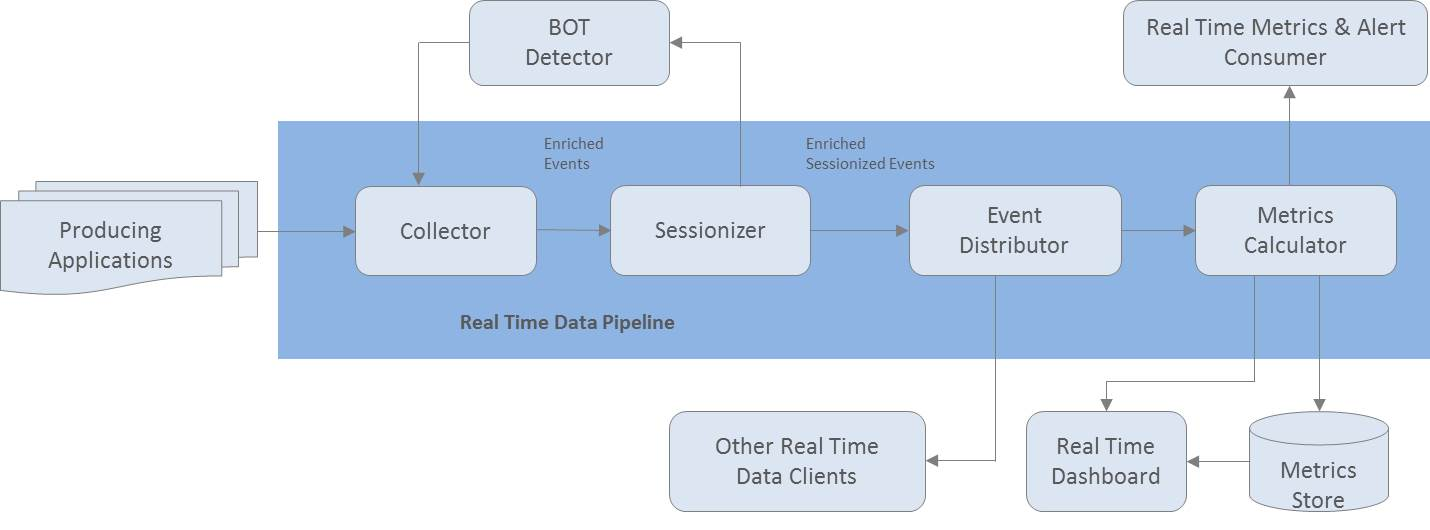
Here is some of the processing we perform in our real-time analytics pipeline:
- Enrichment – Decorate events with additional attributes. For example, we can add geo location information to user interaction events based on the IP address range.
- Filtering and mutation – Filter out irrelevant attributes and events, or transform the content of an event.
- Aggregation – Count the number of events, or add up metrics along a set of dimensions over a time window.
- Stateful processing – Group multiple events into one, or generate a new event based on a sequence of events and processing rules. An example is our sessionization stage, which tracks user session-based metrics by grouping a sequence of user interaction events into web sessions.
The Pulsar pipeline can be integrated with different systems. For example, summarized events can be sent to a persistent metrics store to support ad-hoc queries. Events can also be sent to some form of visualization dashboard for real-time reporting, or to backend systems that can react to event signals.
A taste of complex event processing
In Pulsar, our approach is to treat the event stream like a database table. We apply SQL queries and annotations on live streams to extract summary data as events are moving.
The following are a few examples of how common processing can be expressed in Pulsar.
Event filtering and routing
insert into SUBSTREAM select D1, D2, D3, D4
from RAWSTREAM where D1 = 2045573 or D2 = 2047936 or D3 = 2051457 or D4 = 2053742; // filtering
@PublishOn(topics=“TOPIC1”) // publish sub stream at TOPIC1
@OutputTo(“OutboundMessageChannel”)
@ClusterAffinityTag(column = D1); // partition key based on column D1
select * FROM SUBSTREAM;
Aggregate computation
// create 10-second time window context
create context MCContext start @now end pattern [timer:interval(10)];
// aggregate event count along dimension D1 and D2 within specified time window
context MCContext insert into AGGREGATE select count(*) as METRIC1, D1, D2 FROM RAWSTREAM group by D1,D2 output snapshot when terminated;
select * from AGGREGATE;
TopN computation
// create 60-second time window context
create context MCContext start @now end pattern [timer:interval(60)];
// sort to find top 10 event counts along dimensions D1, D2, and D3
// within specified time window
context MCContext insert into TOPITEMS select count(*) as totalCount, D1, D2, D3 from RawEventStream group by D1, D2, D3 order by count(*) limit 10;
select * from TOPITEMS;
Pulsar deployment architecture
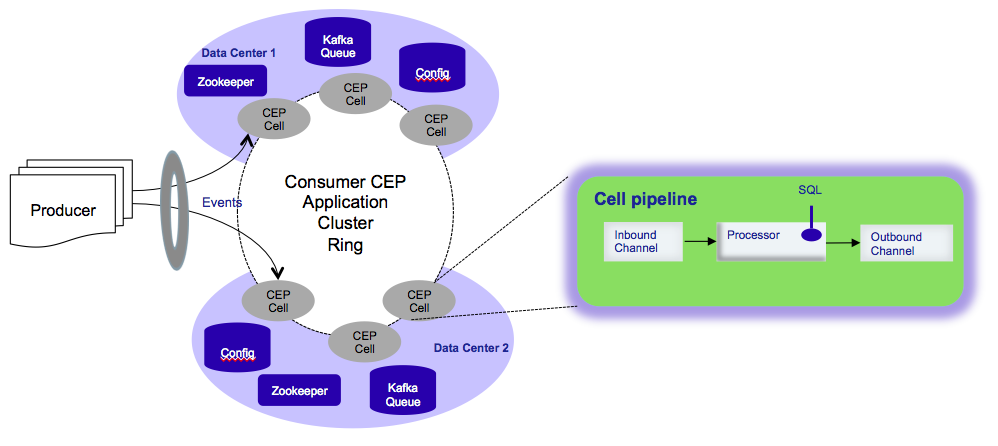
Pulsar CEP processing logic is deployed on many nodes (CEP cells) across data centers. Each CEP cell is configured with an inbound channel, outbound channel, and processing logic. Events are typically partitioned based on a key such as user id. All events with the same partitioned key are routed to the same CEP cell. In each stage, events can be partitioned based on a different key, enabling aggregation across multiple dimensions. To scale to more events, we just need to add more CEP cells into the pipeline. Using Apache ZooKeeper, Pulsar CEP automatically detects the new cell and rebalances the event traffic. Similarly, if a CEP cell goes down, Pulsar CEP will reroute traffic to other nodes.
Pulsar CEP supports multiple messaging models to move events between stages. For low delivery latency, we recommend the push model when events are sent from a producer to a consumer with at-most-once delivery semantics. If a consumer goes down or cannot keep up with the event traffic, it can signal the producer to temporarily push the event into a persistent queue like Kafka; subsequently, the events can be replayed. Pulsar CEP can also be configured to support the pull model with at-least-once delivery semantics. In this case, all events will be written into Kafka, and a consumer will pull from Kafka.
What’s next
Pulsar has been deployed in production at eBay and is processing all user behavior events. We have open-sourced the Pulsar code, we plan to continue to develop the code in the open, and we welcome everyone’s contributions. Below are some features we are working on. We would love to get your help and suggestions.
- Real-time reporting API and dashboard
- Integration with Druid or other metrics stores
- Persistent session store integration
- Support for long rolling-window aggregation